Apache Hudi™ at Uber: Engineering for Trillion-Record-Scale Data Lake OperationsJanuary 16, 2026 by Team at Uberuber
From Batch to Streaming: Accelerating Data Freshness in Uber's Data LakeDecember 12, 2025 by Uber Engineeringstreamingapache flinkdata lakehouseuber
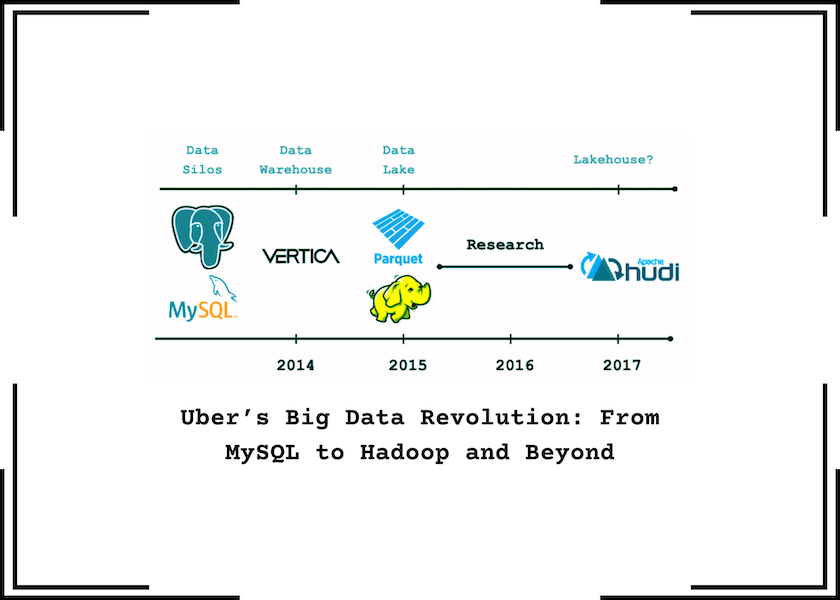
Why Uber Built Hudi: The Strategic Decision Behind a Custom Table FormatJuly 3, 2025 by ThamizhElango Natarajanapache icebergdata lakehouseuber
Scaling Complex Data Workflows at Uber Using Apache HudiJune 30, 2025 by Ankit Shrivastava in collaboration with Dipankaruber
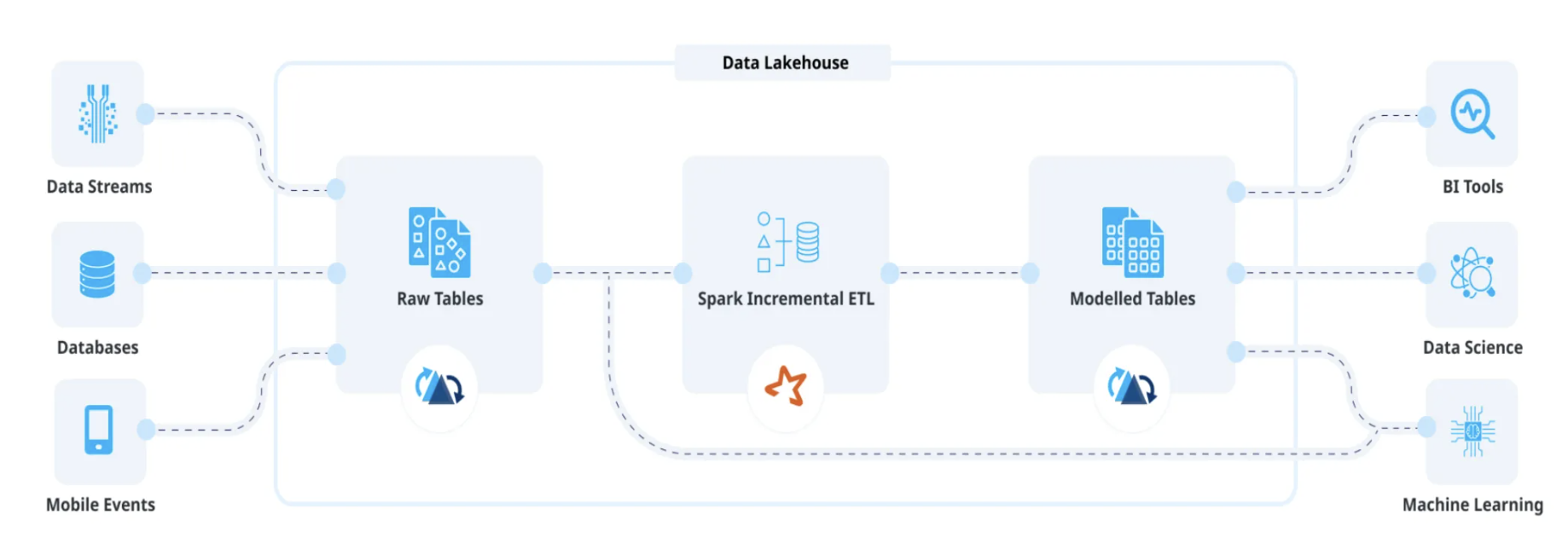
Setting Uber’s Transactional Data Lake in Motion with Incremental ETL Using Apache HudiMarch 16, 2023 by Vinoth Govindarajan, Saketh Chintapalli, Yogesh Saswade and Aayush Barejaincremental processingdata lakehouseuber
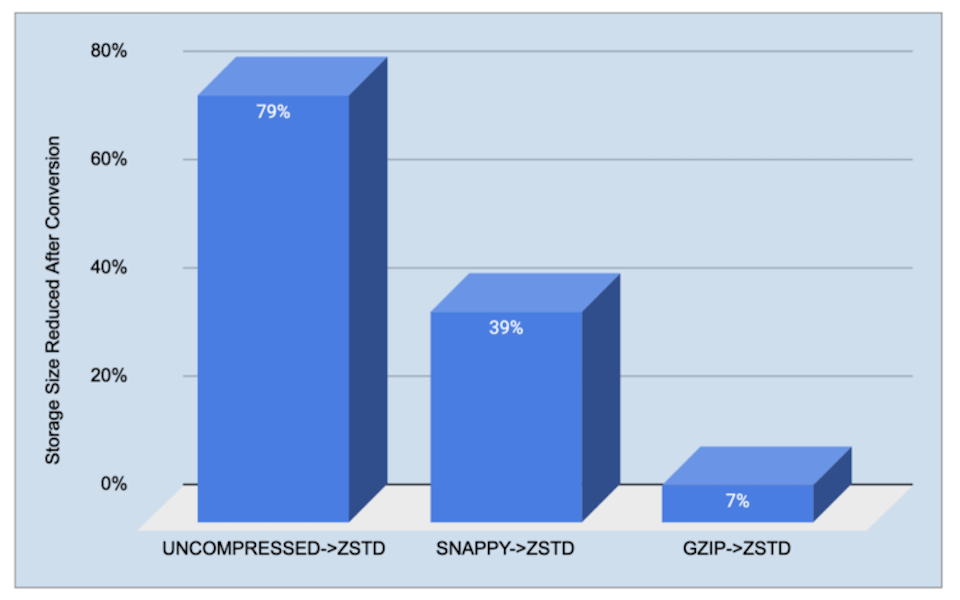
Cost Efficiency @ Scale in Big Data File FormatJanuary 25, 2022 by Xinli Shang, Kai Jiang, Zheng Shao and Mohammad Islamperformancecompressionbiuber
Cost-Efficient Open Source Big Data Platform at UberAugust 11, 2021 by Zheng Shao and Mohammad Islamperformancedata platformincremental processinguber
Building a Large-scale Transactional Data Lake at Uber Using Apache HudiJune 9, 2020 by Nishith Agarwaldata lakehousebiuber
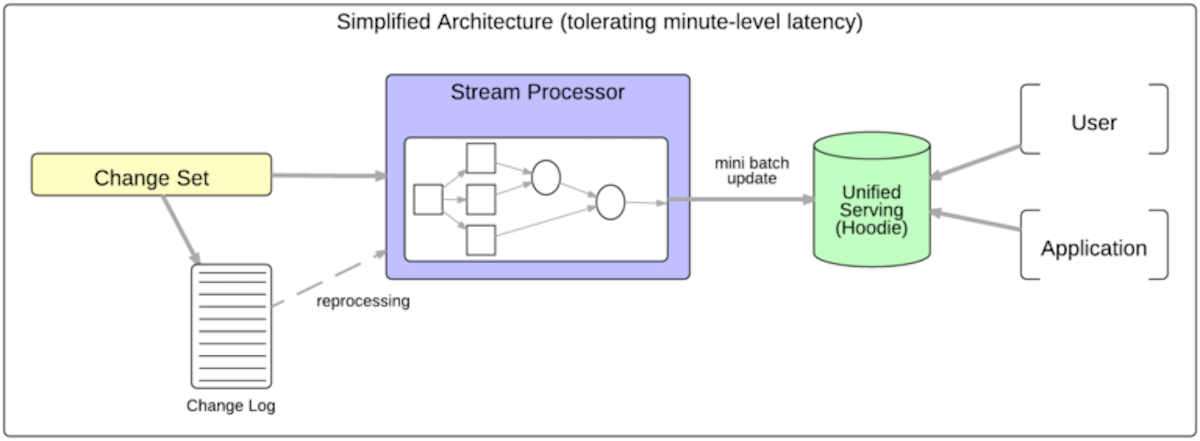
Hoodie: Uber Engineering's Incremental Processing Framework on HadoopMarch 12, 2017 by Prasanna Rajaperumal and Vinoth Chandarincremental processinguber