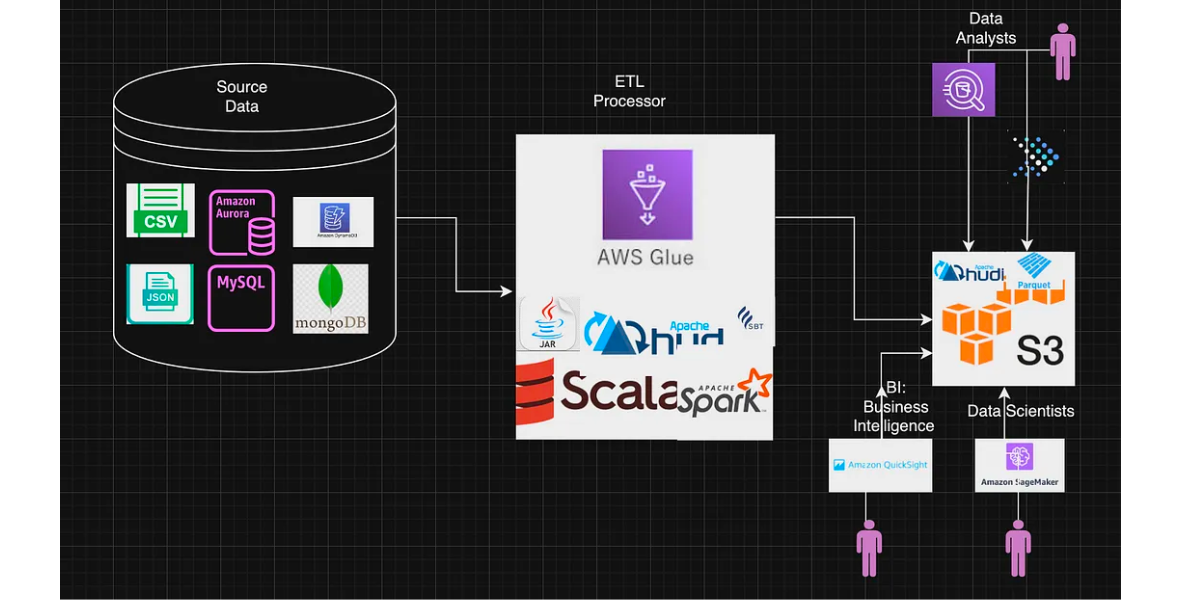
Migrating from Apache Hive Tables to Apache Hudi
Migrating from Parquet to Apache Hudi: A Practical Guide
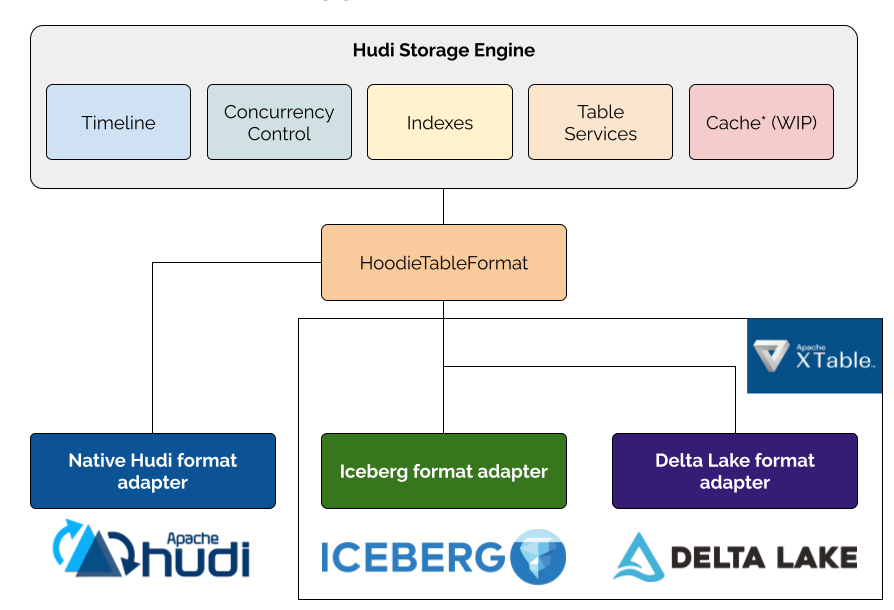
Using Apache Hudi with Apache Iceberg: Interoperability via Apache XTable
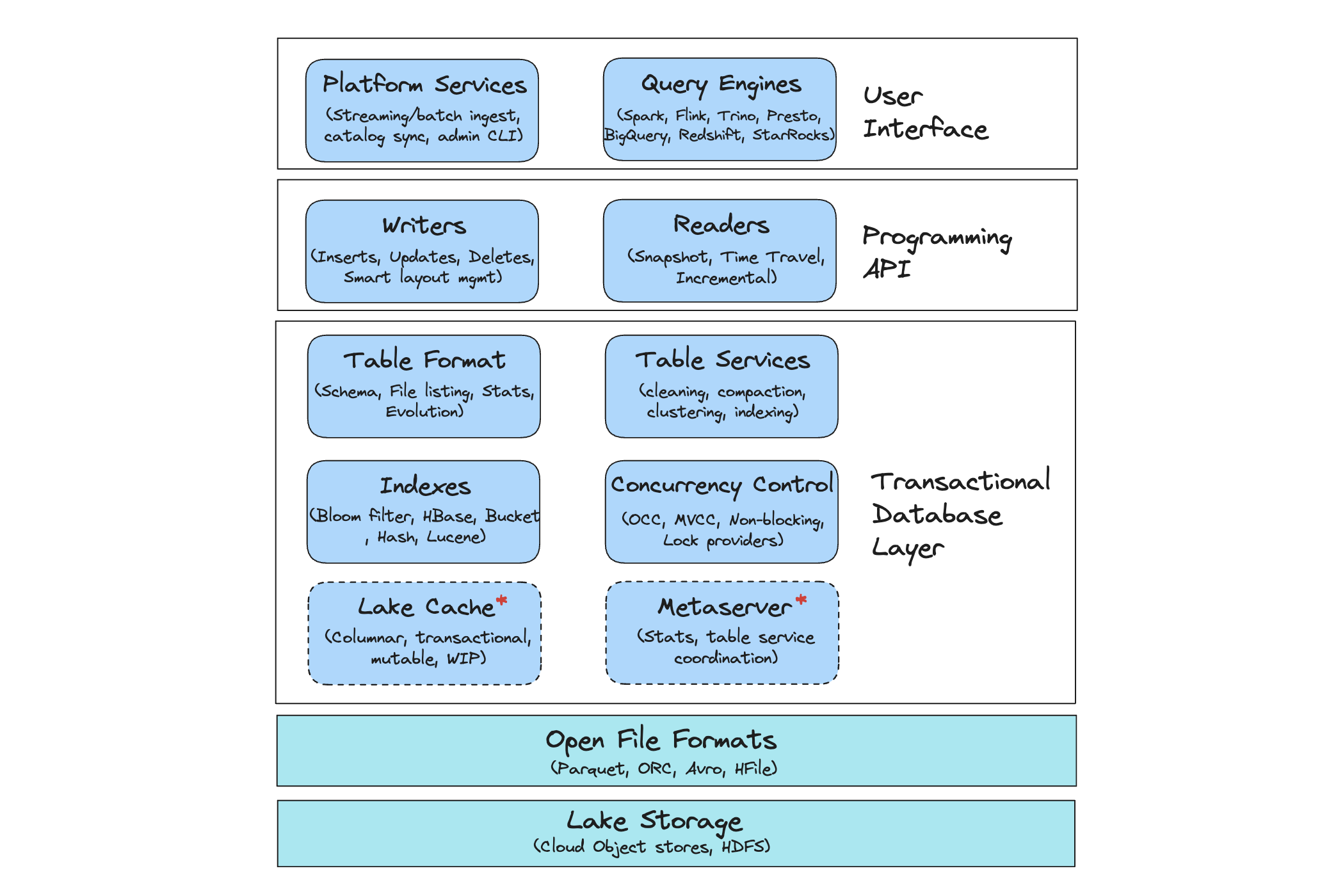
Open Table Format vs Data Lakehouse: What's the Difference?
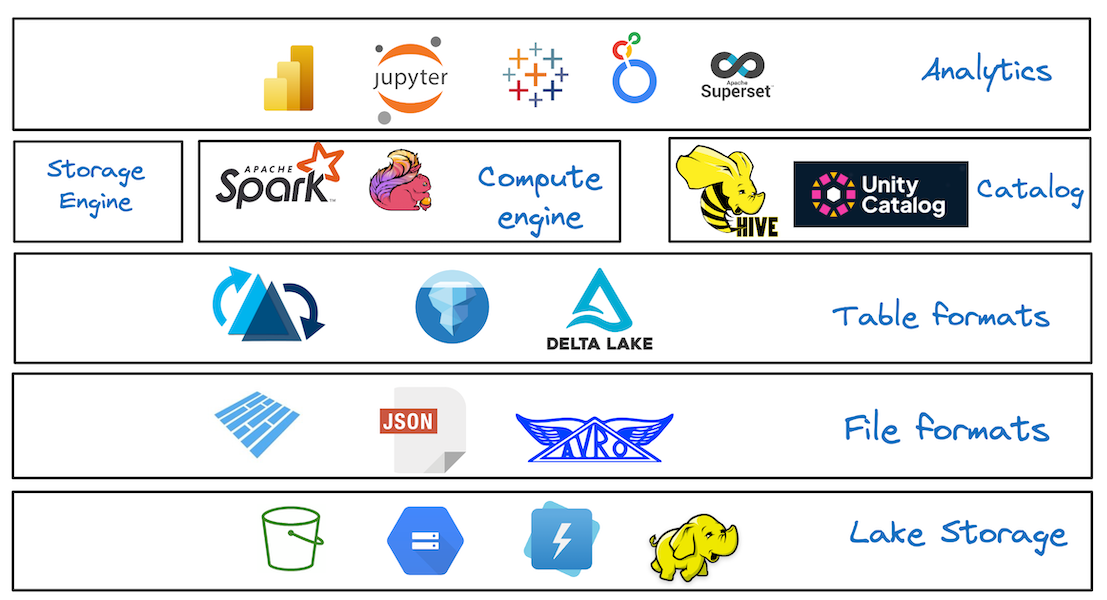
Data Lakehouse vs Data Warehouse vs Data Lake: What's the Difference?
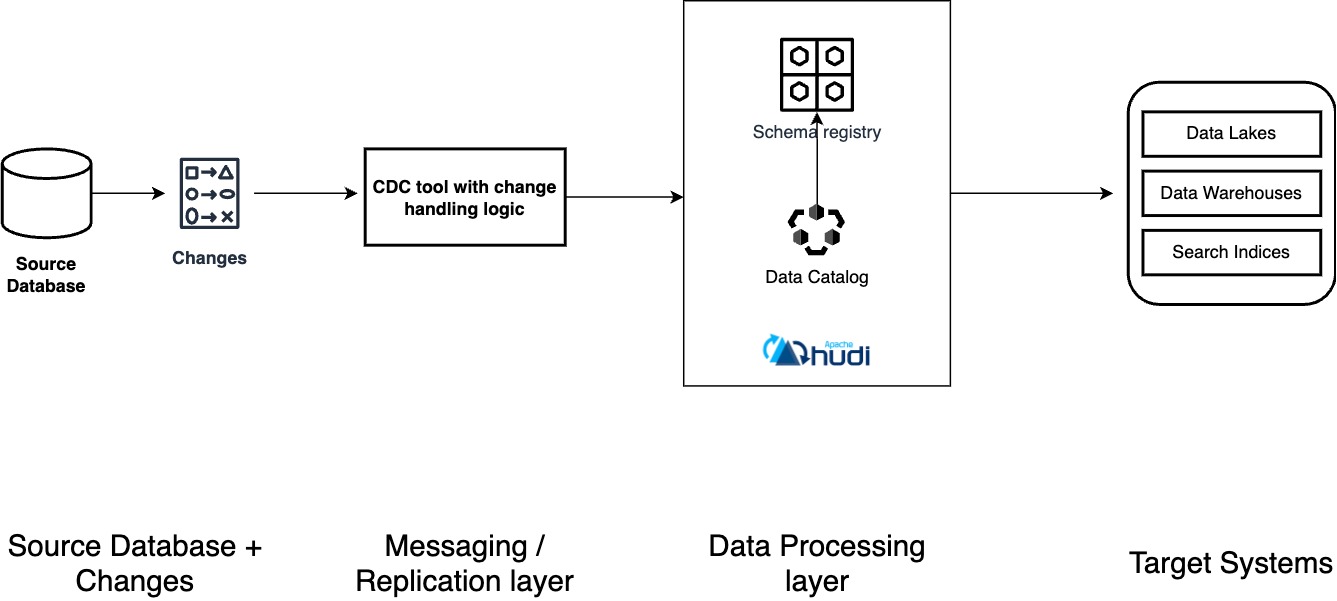
What is CDC on a Data Lake?

What is a Streaming Data Lake?
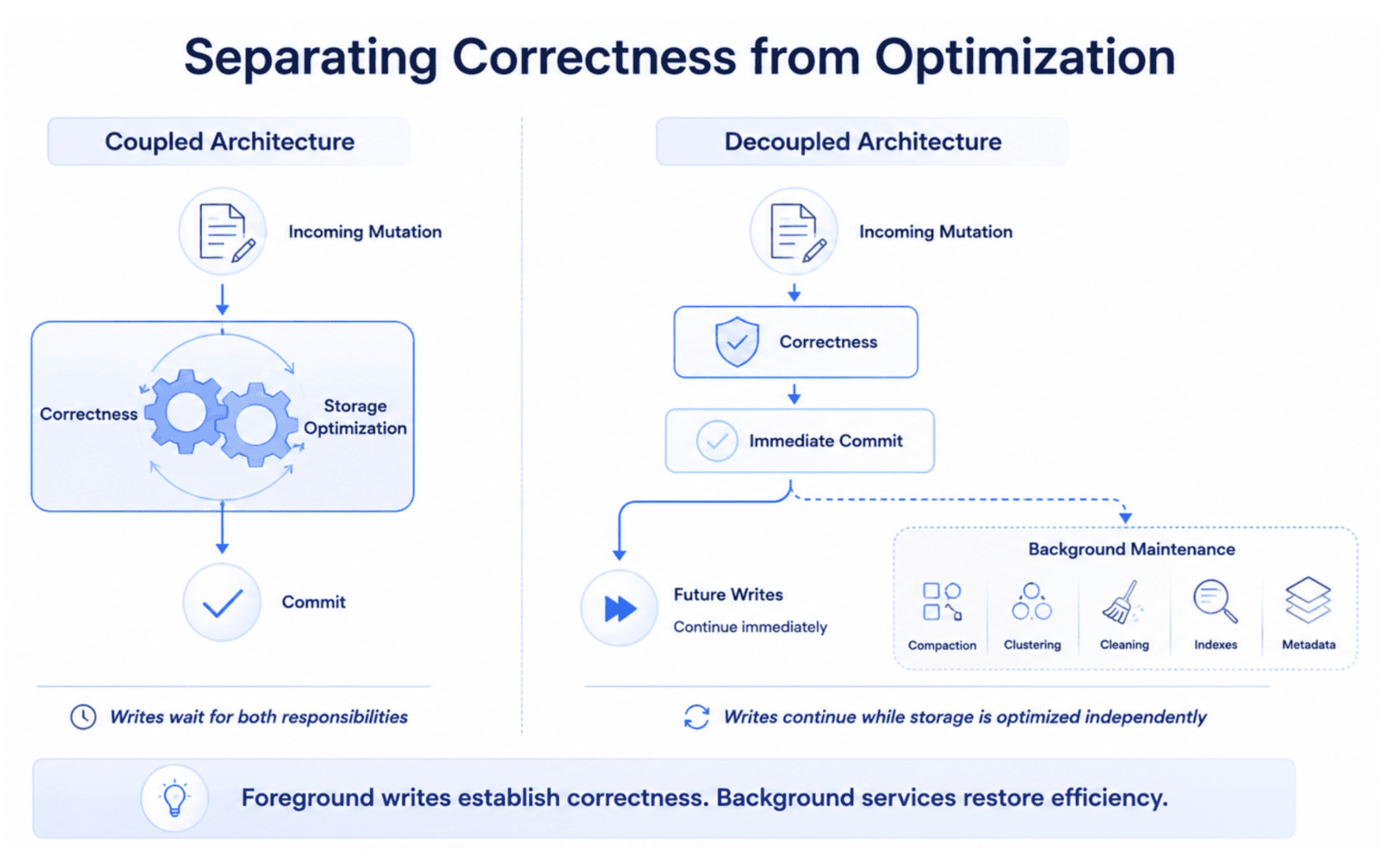
Can a Lakehouse Really Run Maintenance Without Blocking Writes?
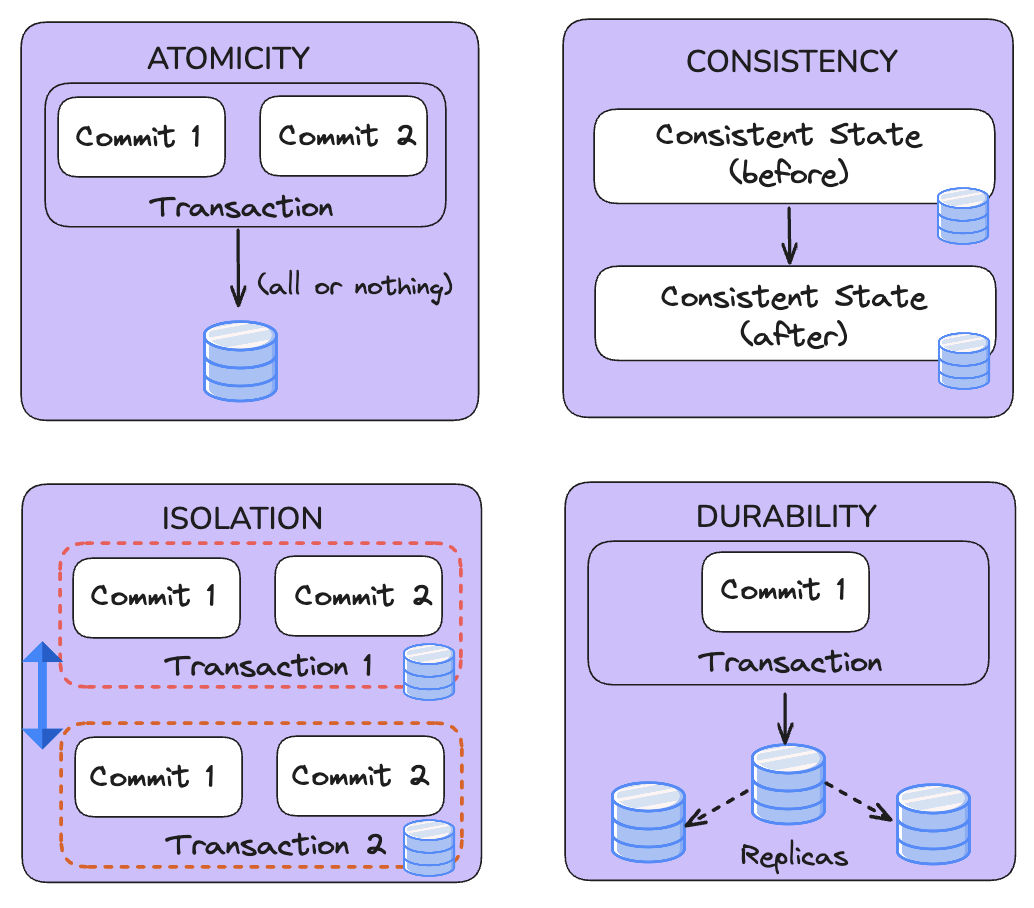
What is ACID on a Data Lake?
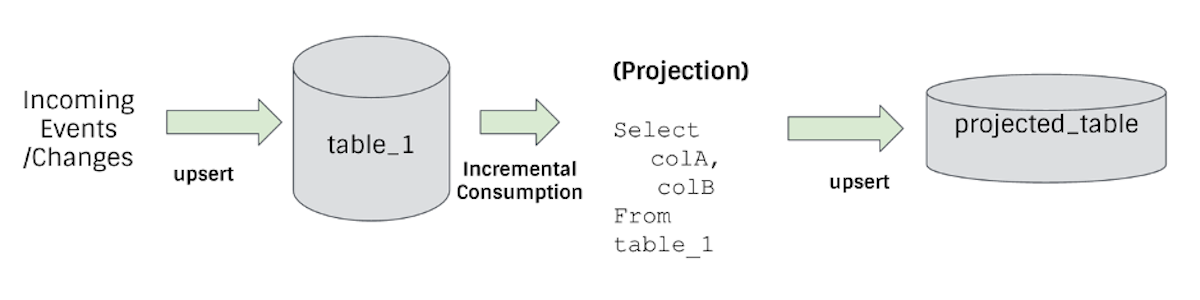
What is Incremental ETL on a Data Lake?

What is Upsert on a Data Lake?
What is an Open Table Format?
Showing 1-12 of 330 posts