Deep Dive Into Hudi's Indexing Subsystem (Part 2 of 2)

In part 1, we explored how Hudi's metadata table functions as a self-managed, multimodal indexing subsystem. We covered its internal architecture—a partitioned Hudi Merge-on-Read (MOR) table using HFile format for efficient key lookups—and how the files, column stats, and partition stats indexes work together to implement powerful data skipping. These indexes dramatically reduce I/O by pruning partitions and files that don't contain the data your query needs.
Now in part 2, we'll dive into more specialized indexes that handle different query patterns. We'll look at the record and secondary indexes, which provide exact file locations for equality-matching predicates rather than just skipping irrelevant files. We'll explore expression indexes that optimize queries with inline transformations like from_unixtime() or substring(). Finally, we'll cover async indexing, which lets you build resource-intensive indexes in the background without blocking your active read and write operations.
Equality Matching with Record and Secondary Indexes
Queries may contain equality-matching predicates like A = X or B IN (X, Y, Z). While data skipping indexes such as column stats and partition stats help here too, record-level indexing goes further by pinpointing the exact data files containing those values.
Hudi’s multimodal indexing subsystem implements the record index and secondary index to meet this need:
- Record index: Stores mappings between record keys and the file locations that contain them.
- Secondary index: Stores mappings between non-record-key column values and their corresponding record keys to support mapping to file locations.
Note that the record index is located at the record_index/ partition of the metadata table. You can create multiple secondary indexes, each for a chosen column, stored under a dedicated partition (prefixed with secondary_index_) in the metadata table.
The record index is a high-performance, general-purpose index that works on both the writer and reader sides. As described in this blog, its direct record-location lookup allows Hudi writers to efficiently route updates and deletes to their corresponding file groups in a Hudi table. The secondary index leverages the record index to look up non-record-key columns efficiently. The remainder of this section focuses on the reader side to show how these two indexes optimize equality-matching predicates.
The lookup process
Similar to the data skipping process, the query engine parses equality-matching predicates and pushes them down to the Hudi integration component. This component then performs the index lookup and returns the file locations to scan.
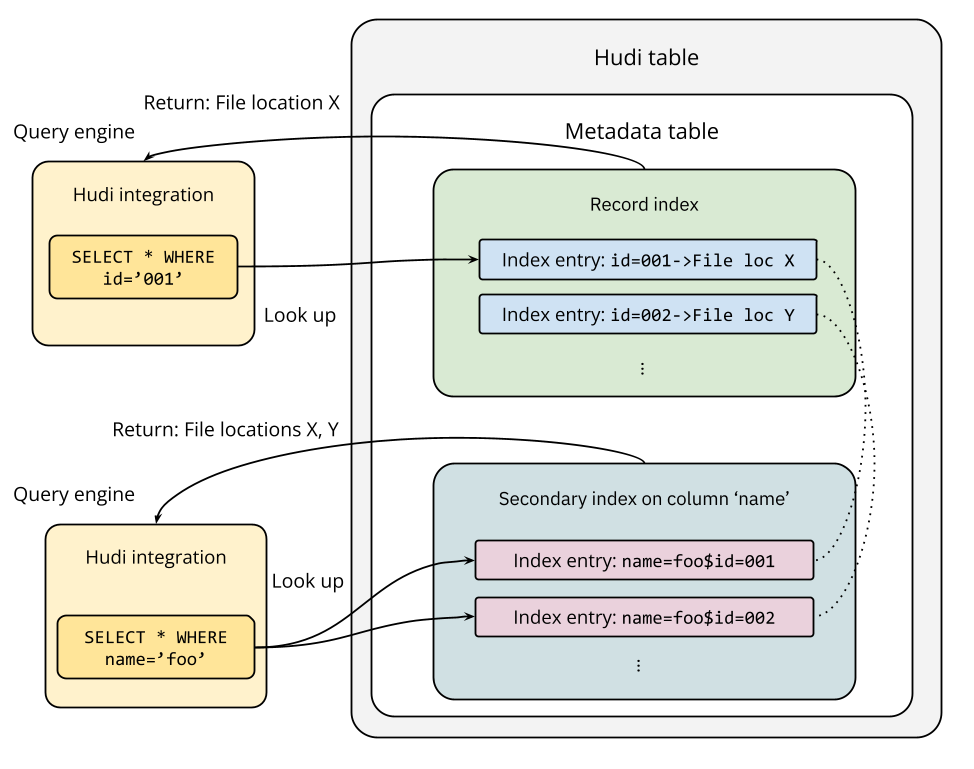
First, let's consider the record index. When a query with an equality filter like id = '001' runs against a Hudi table where id is the record key, the engine uses the record index to find the exact file locations for that key. The index returns these locations to the query engine, which then plans the read execution.
This direct lookup dramatically optimizes the query by ensuring only the relevant file locations are scanned. For example, on a 400 GB synthetic Hudi table with 20,000 file groups, a query filtering on a single record key saw its execution time drop from 977 seconds to just 12 seconds—a 98% reduction—when using the record index.
Now, let's consider the case when the equality filter is name = 'foo' where name is not a record key field. A secondary index built for the column name will be used for the lookup process. Entries in the secondary index contain mappings of all name values and their corresponding record keys. Because multiple distinct records can have the same name value, the lookup may return multiple record keys. The next step is to look up these returned record keys in the record index to find the enclosing file locations for scanning. As you can tell, the record index must be enabled for using the secondary index.
A recent TPCDS benchmarking shows that, by using the secondary index, query performance improved by about 45% on average, and the amount of data scanned was reduced by 90%.
SQL examples
You can specify hoodie.metadata.record.index.enable during table creation to enable the record index for the table:
CREATE TABLE trips (
ts BIGINT,
id STRING,
rider STRING,
driver STRING,
fare DOUBLE,
city STRING,
state STRING
) USING hudi
OPTIONS(
primaryKey = 'id',
hoodie.metadata.record.index.enable = 'true' -- enable record index
)
PARTITIONED BY (city, state);
To create a secondary index on a specific column, you can use CREATE INDEX like this:
CREATE INDEX driver_idx ON trips (driver); -- enable secondary index on column `driver`
When you write data to the example table, index data gets written to the record index and secondary index partitions in the metadata table, which then accelerates query execution during reads. Check out the SQL DDL page for more examples.
Expression Index
Query predicates often contain expressions that perform inline transformations on columns, such as from_unixtime() or substring(). These expressions prevent a direct match with standard column indexes like column stats or partition stats. To optimize such queries, Hudi provides the expression index that operates on transformed column values. A full list of supported expressions is available in the documentation.
Hudi currently supports two types of expression indexes:
- Column stats type: Stores file-level statistics (min, max, null count, value count) for the transformed values after applying the expression.
- Bloom filter type: Stores a file-level bloom filter built from the transformed values after applying the expression.
Each expression index—defined by its type, the expression used, and the target column—occupies a dedicated partition within the metadata table, identified by an expr_index_ prefix in its partition path.
The column stats expression index functions similarly to a standard column stats index and is effective for data skipping. As the diagram below illustrates, a predicate containing a from_unixtime() expression is processed for lookup, and the corresponding expression index prunes the file list for the query engine.
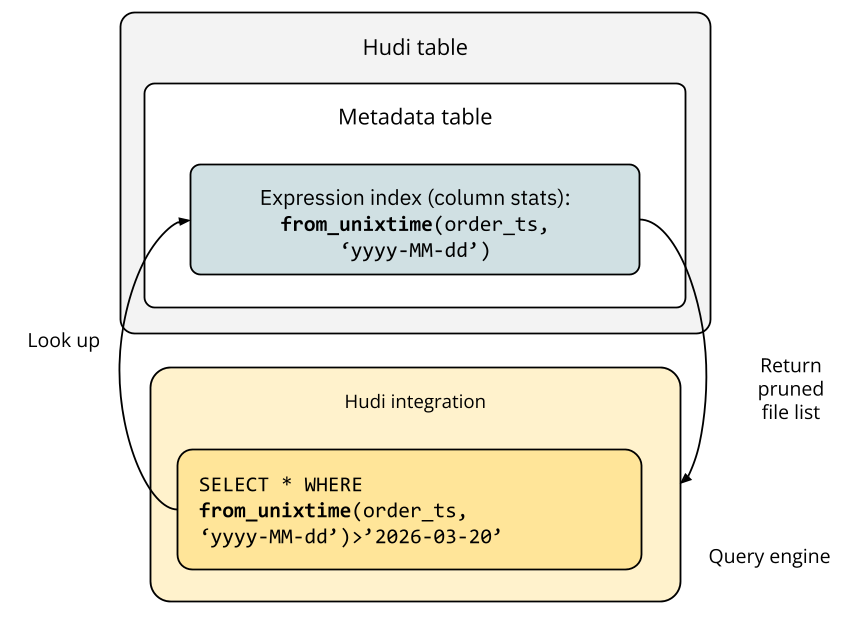
The bloom filter expression index is designed for equality-matching predicates. Unlike the record and secondary indexes, which provide exact file locations, this index uses a bloom filter—a space-efficient data structure for quick presence checks—to prune files. The query planner can skip a file if the bloom filter indicates a target value is definitively not present.
The bloom filter expression index is most effective for high-cardinality columns, where the probability of a "not present" result is higher, allowing more files to be skipped. For low-cardinality columns, the proposed bitmap index would be more efficient and represents a valuable future extension to Hudi's indexing subsystem.
SQL examples
Similar to creating a secondary index, you can create an expression index (column stats type) like this:
CREATE INDEX ts_date ON trips
USING column_stats(ts)
OPTIONS(expr='from_unixtime', format='yyyy-MM-dd');
This example creates a column stats expression index on the column ts with the expression from_unixtime that transforms an epoch timestamp into a date string, allowing effective data skipping based on dates.
You can create a bloom filter expression index similarly:
CREATE INDEX bloom_idx_rider ON trips
USING bloom_filters(rider)
OPTIONS(expr='lower');
This example builds a bloom filter expression index using the lowercase values of column rider, optimizing for predicates that match lowercase rider names. Check out the SQL DDL page for more examples.
Building Indexes Efficiently with the Async Indexer
Hudi provides flexible mechanisms for managing indexes. You can use SQL DDL commands—such as CREATE INDEX, DROP INDEX, and SHOW INDEXES—or programmatically set writer configurations via the Spark DataSource and Flink DataStream APIs. For example, setting hoodie.metadata.index.partition.stats.enable=false during a write operation drops the partition stats index. This action deletes the corresponding partition from the metadata table and skips indexing computations for subsequent writes until the configuration is re-enabled.
Creating a new index can be a resource-intensive operation, particularly for large tables and for indexes with high space complexity. For instance, the space complexity of the column stats index is O(columns × files), while the record index requires O(records) space. When adding such an index to a large table via DDL or a writer configuration, the time-consuming index initialization process must not block ongoing read and write operations.
To address this challenge, Hudi's index management is designed with two key goals: index creation should not block concurrent reads and writes, and once built, an index must serve consistent data up to the latest table commit. Hudi meets these requirements with its async indexing (illustrated below), which builds indexes in the background without interrupting active writers and readers.
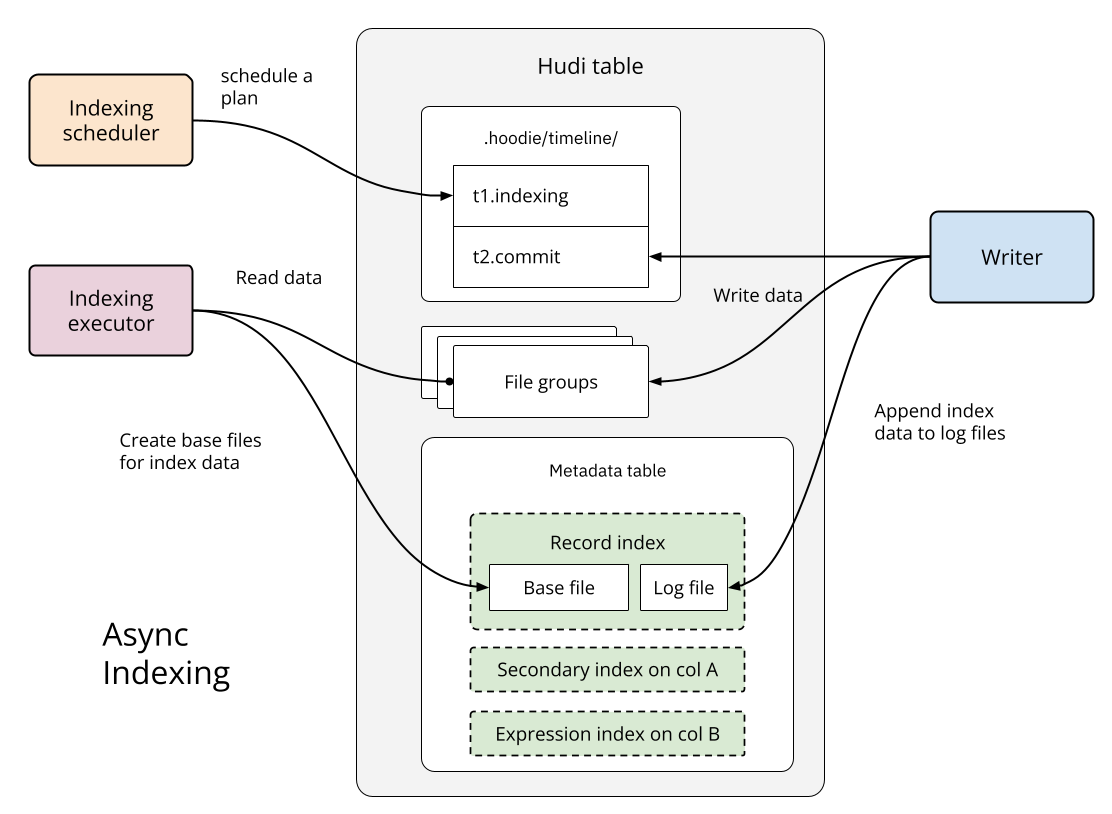
The async indexing process consists of two phases: scheduling and execution. First, the scheduler creates an indexing plan that covers data up to the latest data table commit. Next, the executor reads the required file groups from the data table and writes the corresponding index data to the metadata table. While this process runs, concurrent writers can continue ingesting data. The async indexing executor writes index data to base files in the target index partitions in the metadata table, while the ongoing writer append new index data to log files in those partitions. Hudi uses a conflict resolution mechanism to determine if an indexing operation needs to be retried due to concurrent write conflicts.
To manage this concurrency, a lock provider must be configured for both the indexer and the data writers. Upon successful completion, the operation is marked by a completed indexing commit in the Hudi table’s timeline. For future improvements, the metadata table will employ non-blocking concurrency control to gracefully absorb conflicting updates from both indexing and write operations, thus avoiding wasteful retries. You can find configuration examples in the documentation.
Summary
Throughout this two-part series, we've explored how Hudi's indexing subsystem brings database-grade performance to the data lakehouse. In part 1, we examined the metadata table's architecture and how files, column stats, and partition stats indexes work together to skip irrelevant data. In part 2, we covered specialized indexes—record, secondary, and expression indexes—that provide exact file locations for equality matching and handle transformed predicates. We also looked at async indexing, which lets you add resource-intensive indexes without blocking ongoing operations.
Here's a quick guide for choosing the right indexes for your workload:
- Files: Always enabled in the metadata table—provides partition and file lists in the table to facilitate common indexing processes
- Column stats and partition stats: Enable by default and configure
hoodie.metadata.index.column.stats.column.listto include only the columns you frequently filter on. These indexes are essential for range predicates and data skipping - Record index: Enable when you have frequent point lookups on record keys or when you need secondary indexes. The record index also optimizes Hudi's write path by efficiently routing updates and deletes
- Secondary index: Create secondary indexes for non-record-key columns that appear in equality predicates. Each secondary index adds maintenance overhead, so focus on high-value columns
- Expression index: Use expression indexes when queries contain predicates with inline transformations. Choose column stats type for range queries on transformed values, or bloom filter type for equality matching on high-cardinality columns
- Async indexing: Use async indexing when adding indexes to large tables. The async indexer builds indexes in the background, keeping your writers and readers unblocked
All indexes are maintained transactionally alongside data writes, ensuring consistency without sacrificing performance. The metadata table uses HFile format for fast point lookups and periodic compaction to keep reads efficient. This design makes Hudi's indexing subsystem both powerful and practical—ready to handle lakehouse-scale data while remaining simple to configure and operate.
As Hudi continues to evolve, the indexing subsystem is designed for extensibility. Upcoming features like the bitmap index for low-cardinality columns and vector search index for AI workloads will further expand its capabilities. By understanding these indexing patterns and following the configuration guidelines in this series, you can build lakehouse tables that deliver the query performance your analytics and data pipelines demand.