Developer Setup
Pre-requisites
To contribute code, you need
- a GitHub account
- Git installed for version control
- a Linux (or) macOS development environment with Java JDK 11, Apache Maven (3.x+) installed
- Docker installed for running demo, integ tests or building website
- for large contributions, a signed Individual Contributor License Agreement (ICLA) to the Apache Software Foundation (ASF).
- (Recommended) Join our dev mailing list & slack channel, listed on community page.
Default Build Profiles
The following table summarizes the default build profiles and versions used by the Apache Hudi project.
| Component | Default Profile / Version | Notes |
|---|---|---|
| Spark | 3.5 | Default Spark 3 build profile |
| Scala | 2.12 | Default Scala version for Spark builds |
| Java | 11 | Required Java version for building the project |
| Flink | 1.20 | Default Flink streaming profile |
Useful Maven commands for developers
Listing out some of the maven commands that could be useful for developers.
- Compile/build entire project
mvn clean package -DskipTests -Dspark3.5 -Dflink1.20
Default profile is Spark 3.5 and Scala 2.12
- For continuous development, you may want to build only the modules of interest. for eg, if you have been working with Hudi Streamer, you can build using this command instead of entire project. Majority of time goes into building all different bundles we have like flink bundle, presto bundle, trino bundle etc. But if you are developing something confined to hudi-utilities, you can achieve faster build times.
mvn package -DskipTests -pl packaging/hudi-utilities-bundle/ -am
To enable multi-threaded building, you can add -T.
mvn -T 2C package -DskipTests -pl packaging/hudi-utilities-bundle/ -am
This command will use 2 parallel threads to build.
You can also confine the build to just one module if need be.
mvn -T 2C package -DskipTests -pl hudi-spark-datasource/hudi-spark -am
Note: "-am" will build all dependent modules as well. In local laptop, entire project build can take somewhere close to 7 to 10 mins. While building just hudi-spark-datasource/hudi-spark with multi-threaded, could get your compilation in 1.5 to 2 mins.
If you wish to run any single test class in java.
mvn test -Punit-tests -pl hudi-spark-datasource/hudi-spark/ -am -B -DfailIfNoTests=false -Dtest=TestCleaner -DwildcardSuites="abc" -Dspark3.5
-DwildcardSuites="abc" will assist in skipping all scala tests.
If you wish to run a single test method in java.
mvn test -Punit-tests -pl hudi-spark-datasource/hudi-spark/ -am -B -DfailIfNoTests=false -Dtest=TestCleaner#testKeepLatestCommitsMOR -DwildcardSuites="abc" -Dspark3.5
To filter particular scala test:
mvn -Dsuites="org.apache.spark.sql.hudi.ddl.TestSpark3DDL @Test Chinese table " -Dtest=abc -DfailIfNoTests=false test -pl packaging/hudi-spark-bundle -am -Dspark3.5
-Dtest=abc will assist in skipping all java tests. -Dsuites="org.apache.spark.sql.hudi.ddl.TestSpark3DDL @Test Chinese table " filters for a single scala test.
- Run an Integration Test
mvn -T 2C -Pintegration-tests -DfailIfNoTests=false -Dit.test=ITTestHoodieSanity#testRunHoodieJavaAppOnMultiPartitionKeysMORTable verify -Dspark3.5
verify phase runs the integration test and cleans up the docker cluster after execution. To retain the docker cluster use
integration-test phase instead.
Note: If you encounter unknown shorthand flag: 'H' in -H, this error occurs when local environment has docker-compose version >= 2.0.
The latest docker-compose is accessible using docker-compose whereas v1 version is accessible using docker-compose-v1 locally.
You can use alt def command to define different docker-compose versions. Refer alt.
Use alt use to use v1 version of docker-compose while running integration test locally.
Code & Project Structure
docker: Docker containers used by demo and integration tests. Brings up a mini data ecosystem locallyhudi-cli: CLI to inspect, manage and administer datasetshudi-client: Spark client library to take a bunch of inserts + updates and apply them to a Hudi tablehudi-common: Common classes used across moduleshudi-hadoop-mr: InputFormat implementations for ReadOptimized, Incremental, Realtime viewshudi-hive: Manage hive tables off Hudi datasets and houses the HiveSyncToolhudi-integ-test: Longer running integration test processeshudi-spark: Spark datasource for writing and reading Hudi datasets. Streaming sink.hudi-utilities: Houses tools like Hudi streamer, snapshot exporter, etcpackaging: Poms for building out bundles for easier drop in to Spark, Hive, Presto, Utilitiesstyle: Code formatting, checkstyle files
Code Walkthrough
Watch this quick video for a code walkthrough to get started.
IntelliJ Setup
IntelliJ is the recommended IDE for developing Hudi. To contribute, you would need to do the following
-
Fork the Hudi code on Github & then clone your own fork locally. Once cloned, we recommend building as per instructions on spark quickstart or flink quickstart.
-
In IntelliJ, select
File>New>Project from Existing Sources...and select thepom.xmlfile under your local Hudi source folder. -
In
Project Structure>Project, select Java 11 as the Project SDK.
Configure IDE Preferences and Settings
Make the following configuration in Preferences or Settings in newer IntelliJ so the Hudi code can compile in the IDE:
-
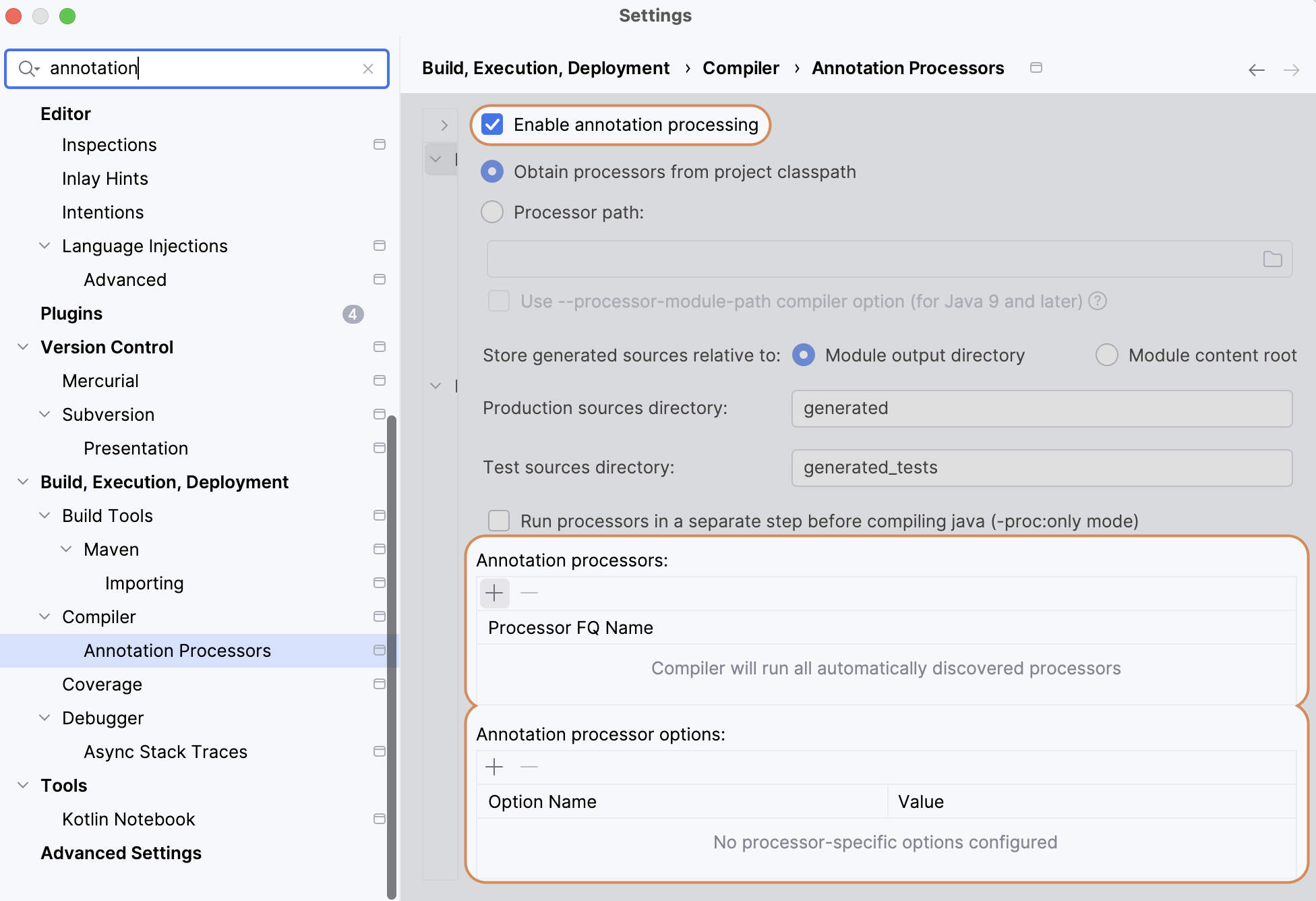
Enable annotation processing in compiler.
-
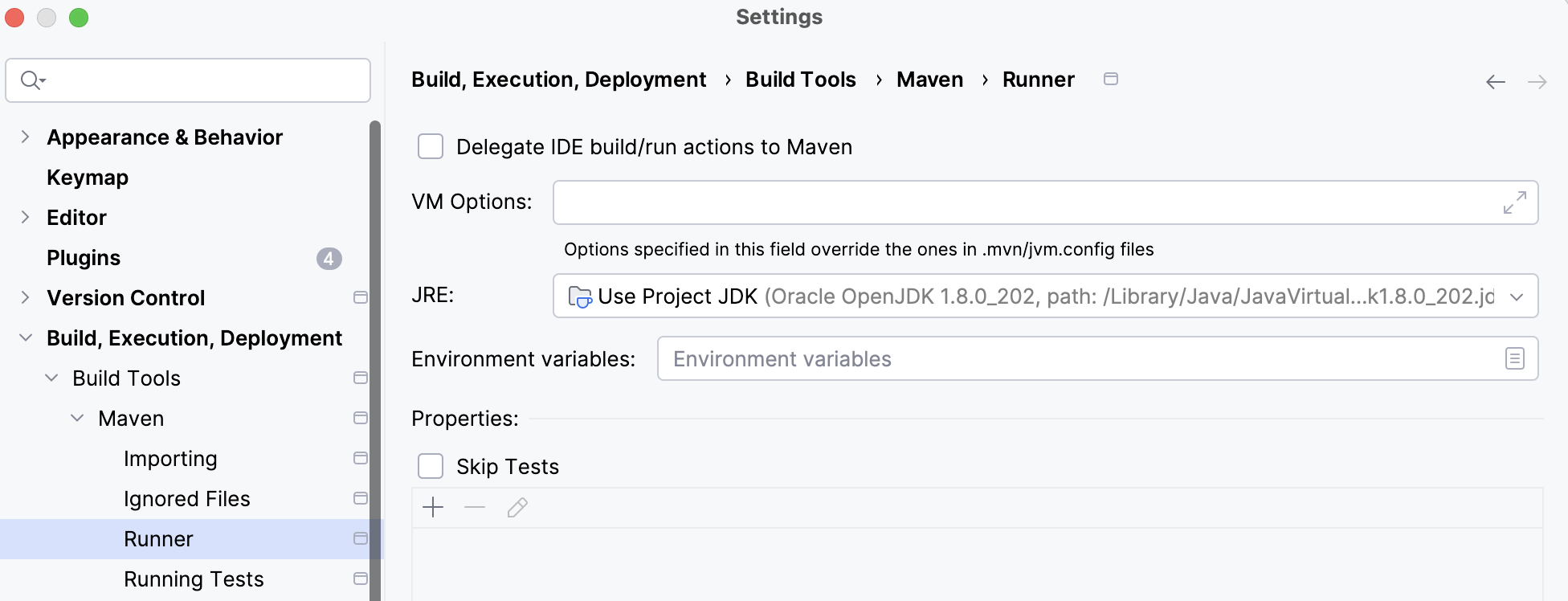
Configure Maven NOT to delegate IDE build/run actions to Maven so you can run tests in IntelliJ directly.
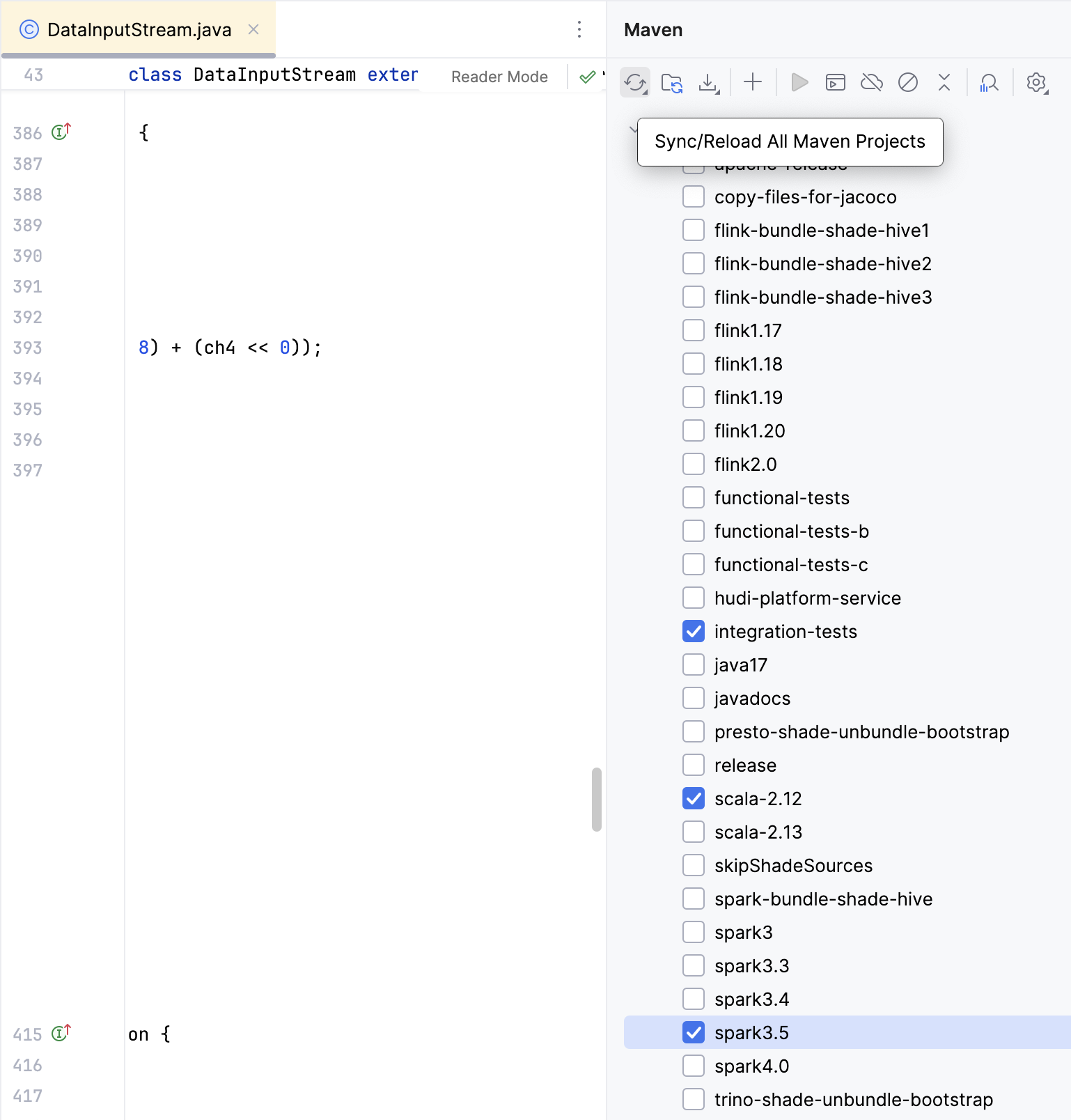
Reload Maven Projects After Profile Changes
If you switch maven build profile, e.g., to a different Spark version, you need to first build Hudi in the command line and then Reload All Maven Projects in IntelliJ like below,
so that IntelliJ re-indexes the code.
[Recommended] Set Up Code Style and CheckStyle
We have embraced the code style largely based on google format. Please set up your IDE with style files from <project root>/style/. These instructions have been tested on IntelliJ.
-
Open
Settingsin IntelliJ -
Install and activate CheckStyle plugin
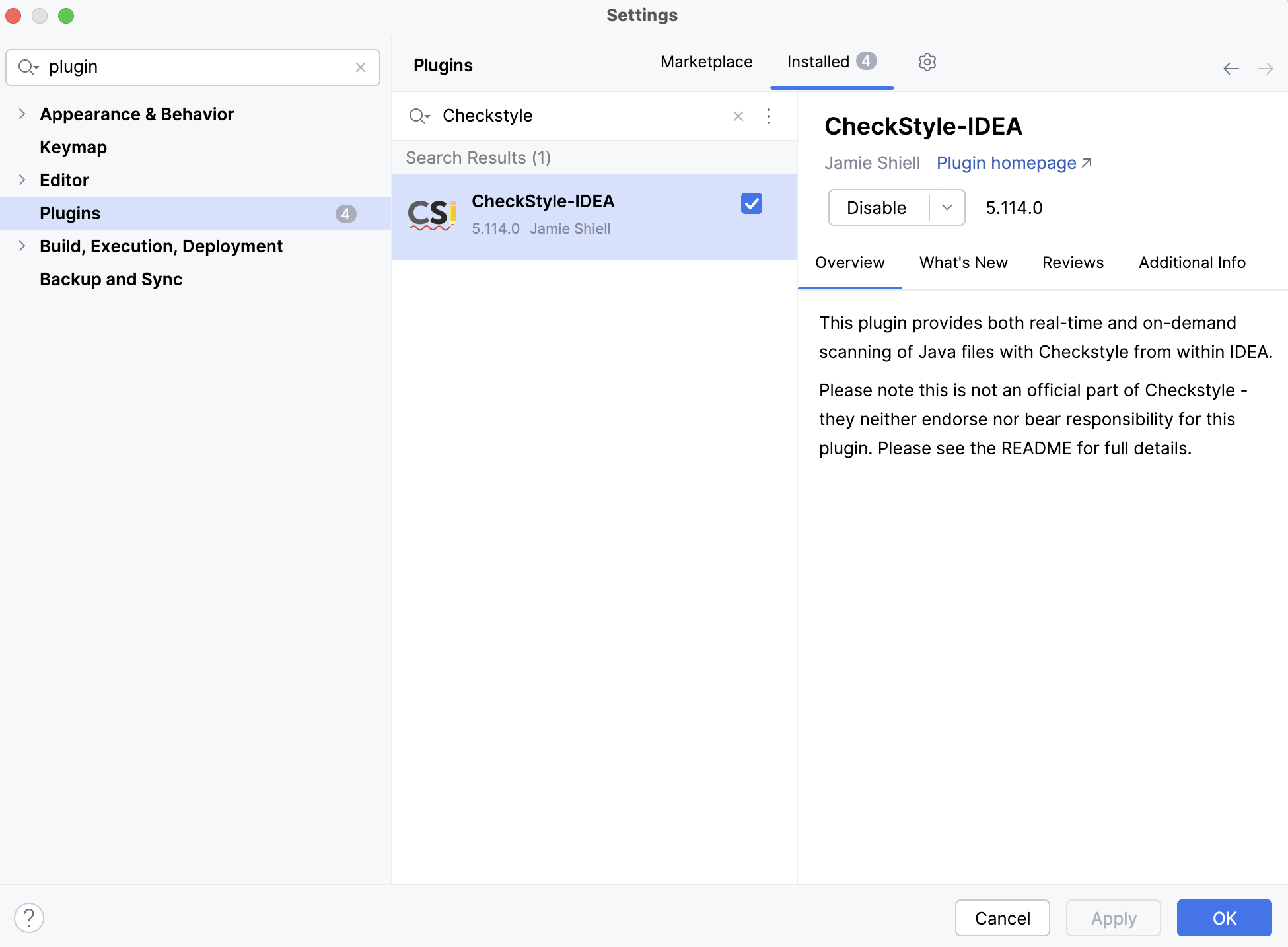
-
In
Settings>Tools>Checkstyle, use a recent version, e.g., 12.1.0 -
Click on
+, add the style/checkstyle.xml file, and name the configuration as "Hudi Checks"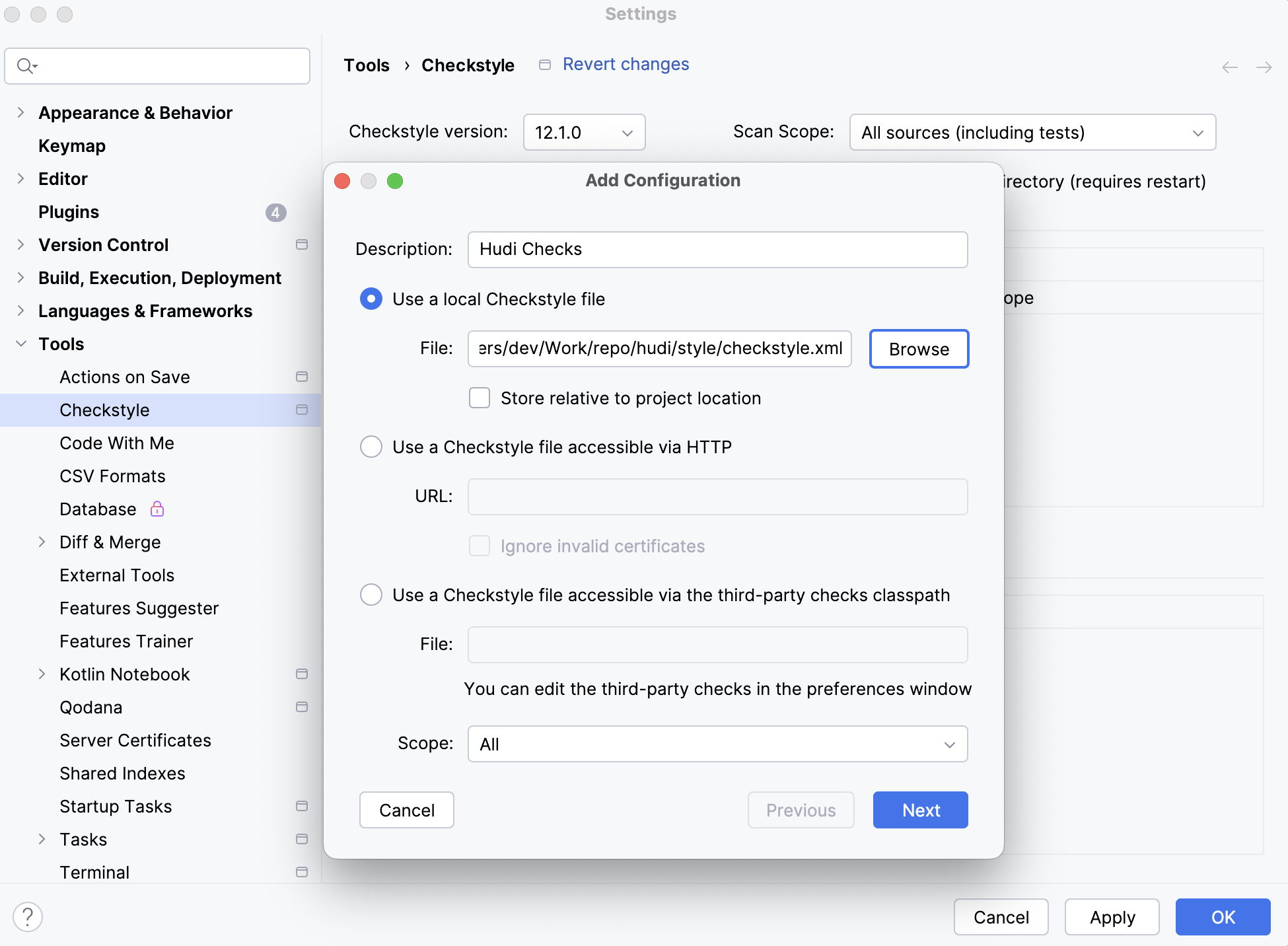
-
Activate the checkstyle configuration by checking
Active -
Open
Settings>Editor>Code Style>Java -
Select "Project" as the "Scheme". Then, go to the settings, open
Import Scheme>CheckStyle Configuration, selectstyle/checkstyle.xmlto load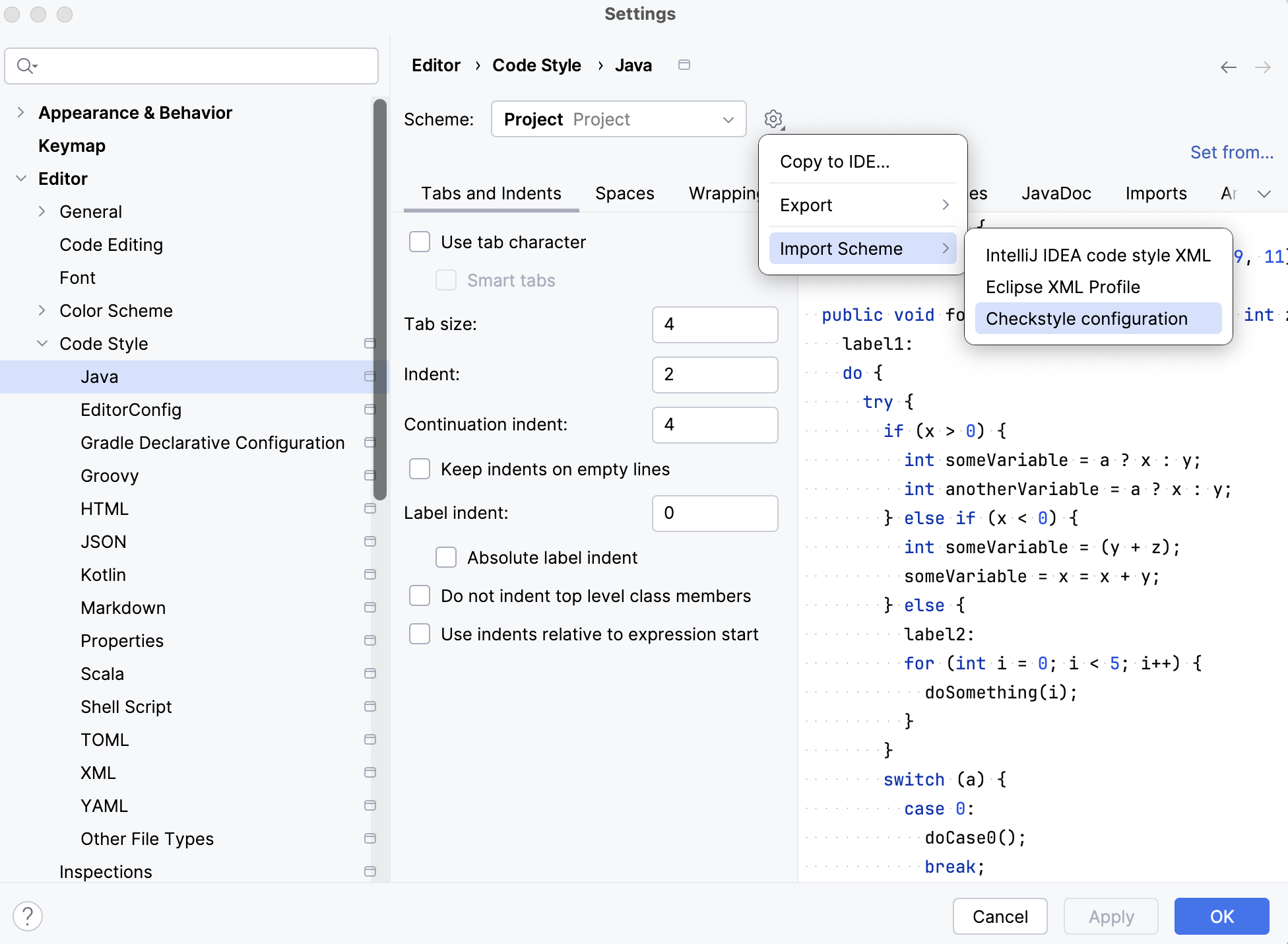
-
After loading the configuration, you should see that the
IndentandContinuation indentbecome 2 and 4, from 4 and 8, respectively -
Apply/Save the changes
[Recommended] Set Up Save Actions and Copyright
-
Set up the Save Action Plugin to auto format & organize imports on save. The Maven Compilation life-cycle will fail if there are checkstyle violations.
-
As it is required to add Apache License header to all source files, configuring "Copyright" settings as shown below will come in handy.
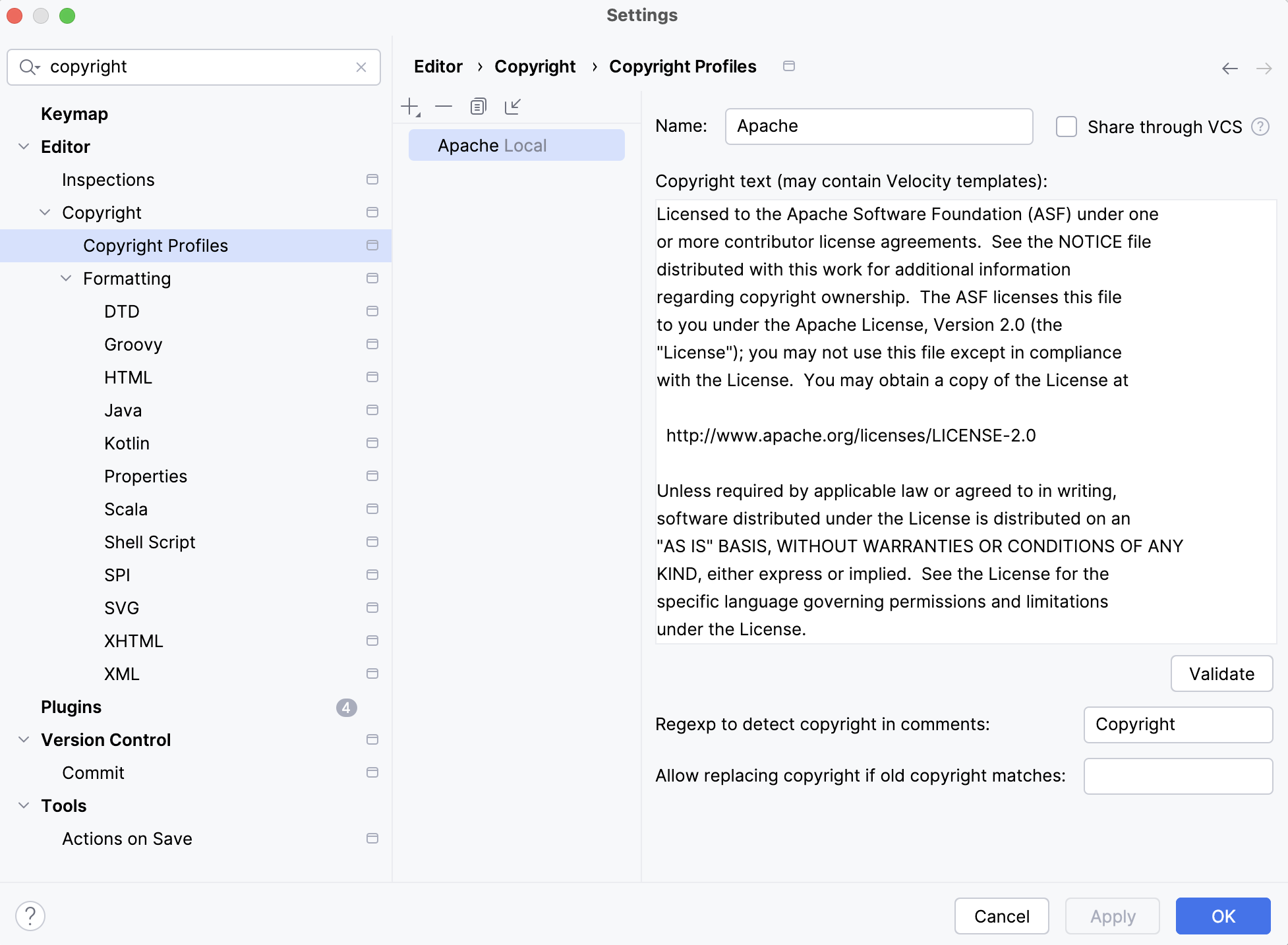
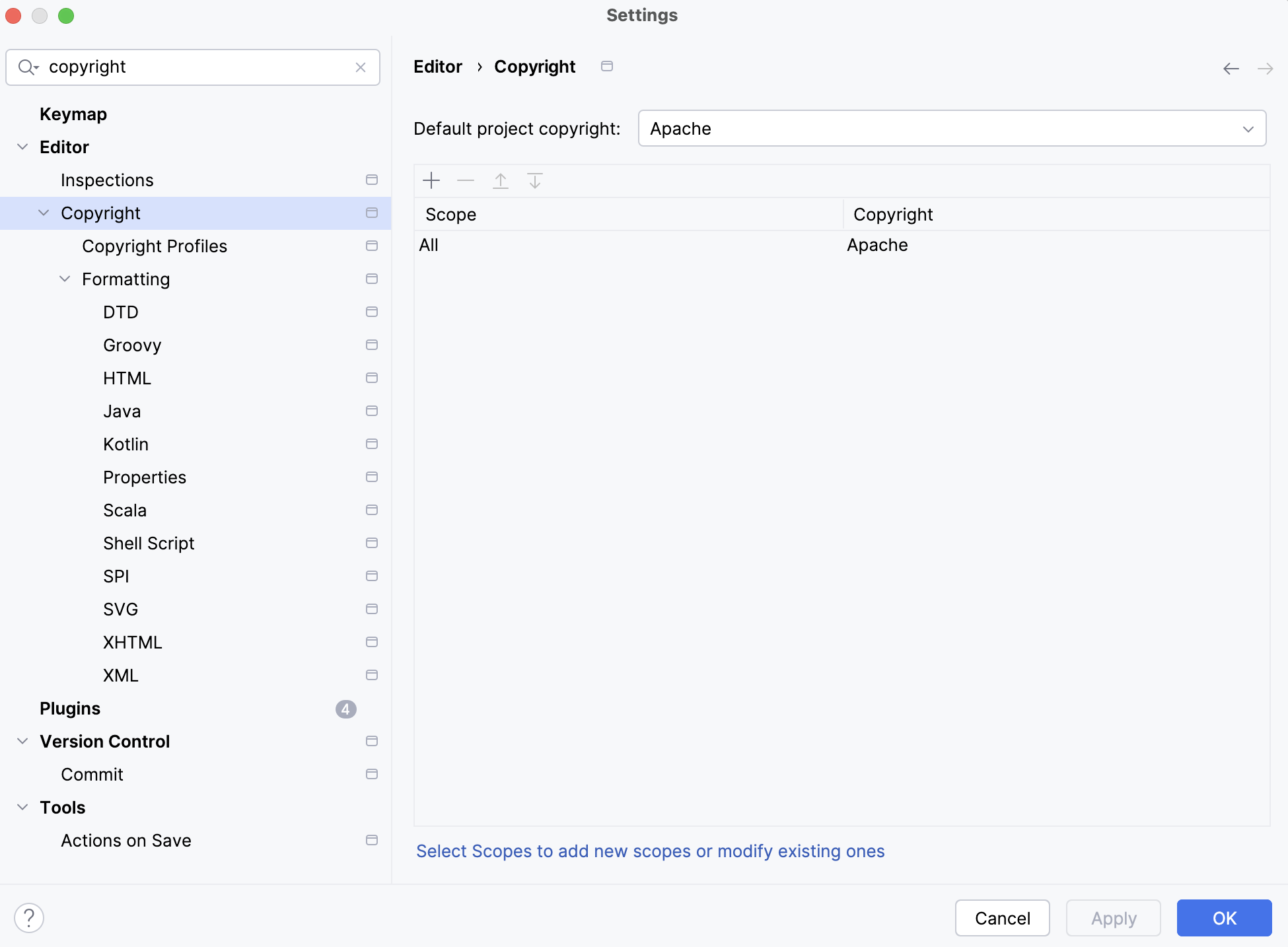
Running unit tests and local debugger via Intellij IDE
When submitting a PR please make sure to NOT commit the changes mentioned in these steps, instead once testing is done make sure to revert the changes and then submit a pr.
- Build the project with the intended profiles via the
mvncli, for example for spark 3.5 usemvn clean package -Dspark3.5 -Dscala-2.12 -Dflink1.20 -DskipTests. - Install the "Maven Helper" plugin from the Intellij IDE.
- Make sure IDEA uses Maven to build/run tests:
- You need to select the intended Maven profiles (using Maven tool pane in IDEA): select profiles you are targeting for example
spark3.5,scala-2.12etc. - Add
.mvn/maven.configfile at the root of the repo w/ the profiles you selected in the pane:-Dspark3.5-Dscala-2.12 - Add
.mvn/to the.gitignorefile located in the root of the project.
- You need to select the intended Maven profiles (using Maven tool pane in IDEA): select profiles you are targeting for example
- Make sure you change (temporarily) the
scala.binary.versionin the rootpom.xmlto the intended scala profile version. For example if running with spark3scala.binary.versionshould be2.12 - Finally right click on the unit test's method signature you are trying to run, there should be an option with a mvn symbol that allows you to
run <test-name>, as well as an option todebug <test-name>.- For debugging make sure to first set breakpoints in the src code see (https://www.jetbrains.com/help/idea/debugging-code.html)
Docker Setup
We encourage you to test your code on the docker cluster please follow this for docker setup.
Remote Debugging
If your code fails on the docker cluster you can remotely debug your code please follow the below steps.
Step 1 :- Run your Hudi Streamer Job with --conf as defined this will ensure to wait till you attach your intellij with Remote Debugging on port 4044
spark-submit \
--conf spark.driver.extraJavaOptions="-Dconfig.resource=myapp.conf -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=4044" \
--class org.apache.hudi.utilities.streamer.HoodieStreamer $HUDI_UTILITIES_BUNDLE \
--table-type COPY_ON_WRITE \
--source-class org.apache.hudi.utilities.sources.JsonKafkaSource \
--source-ordering-field ts \
--base-file-format parquet \
--target-base-path /user/hive/warehouse/stock_ticks_cow \
--target-table stock_ticks_cow --props /var/demo/config/kafka-source.properties \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider
Step 2 :- Attaching Intellij (tested on Intellij Version > 2019. these steps may change acc. to intellij version)
- Come to Intellij --> Edit Configurations -> Remote -> Add Remote -> Put Below Configs -> Apply & Save -> Put Debug Point -> Start.
- Name : Hudi Remote
- Port : 4044
- Command Line Args for Remote JVM : -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=4044
- Use Module ClassPath : select hudi
Website
Apache Hudi site is hosted on a special asf-site branch. Please follow the README file under docs on that branch for
instructions on making changes to the website.