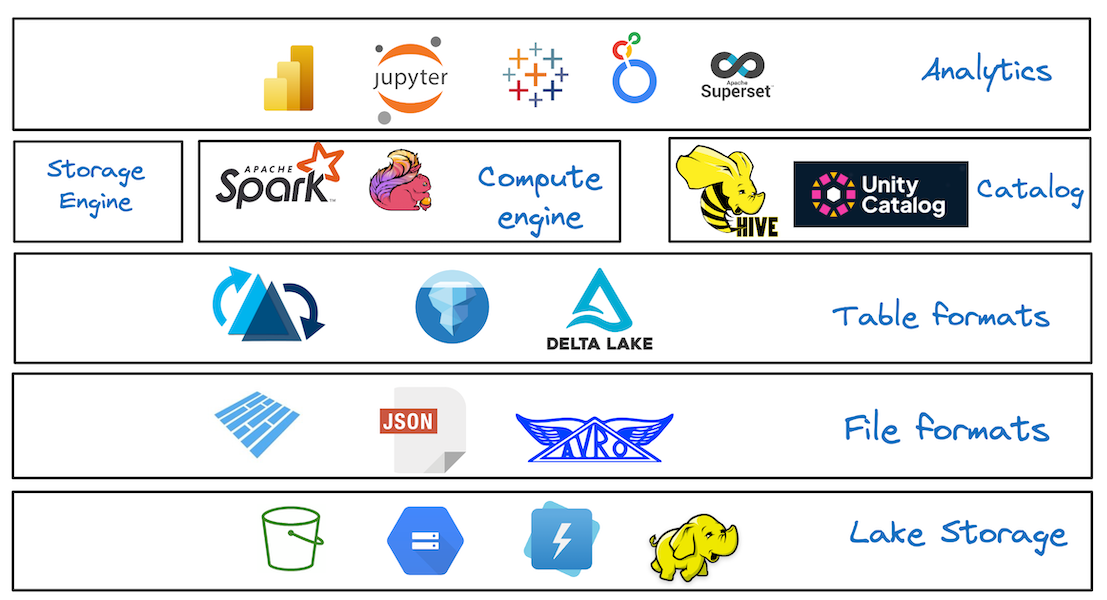
Open Table Format vs Data Lakehouse: What's the Difference?July 24, 2026 by Vinoth Chandartable formatdata lakehouseopen architecturearchitecture
Data Lakehouse vs Data Warehouse vs Data Lake: What's the Difference?July 23, 2026 by Vinoth Chandardata lakehousedata warehousecomparisonopen architecture
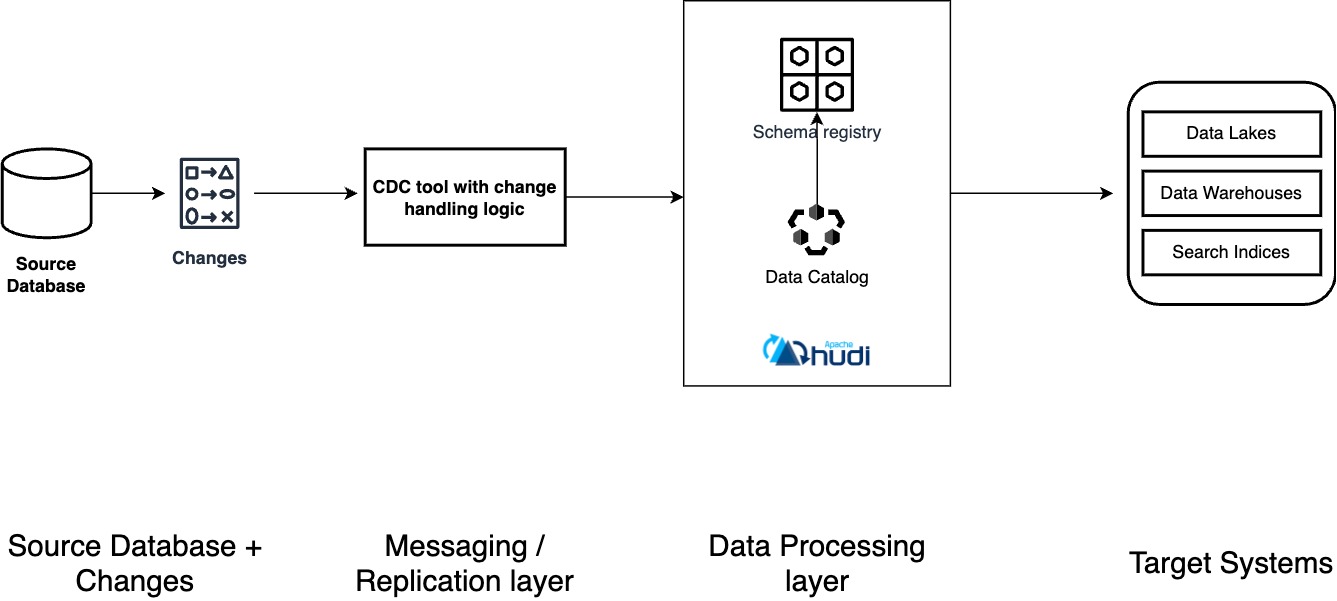
What is CDC on a Data Lake?July 22, 2026 by Sivabalan Narayanancdcstreamingdebeziumdata lakehousebeginner
What is a Streaming Data Lake?July 21, 2026 by Vinoth Chandarstreamingdata lakehousemorcdcincremental processing
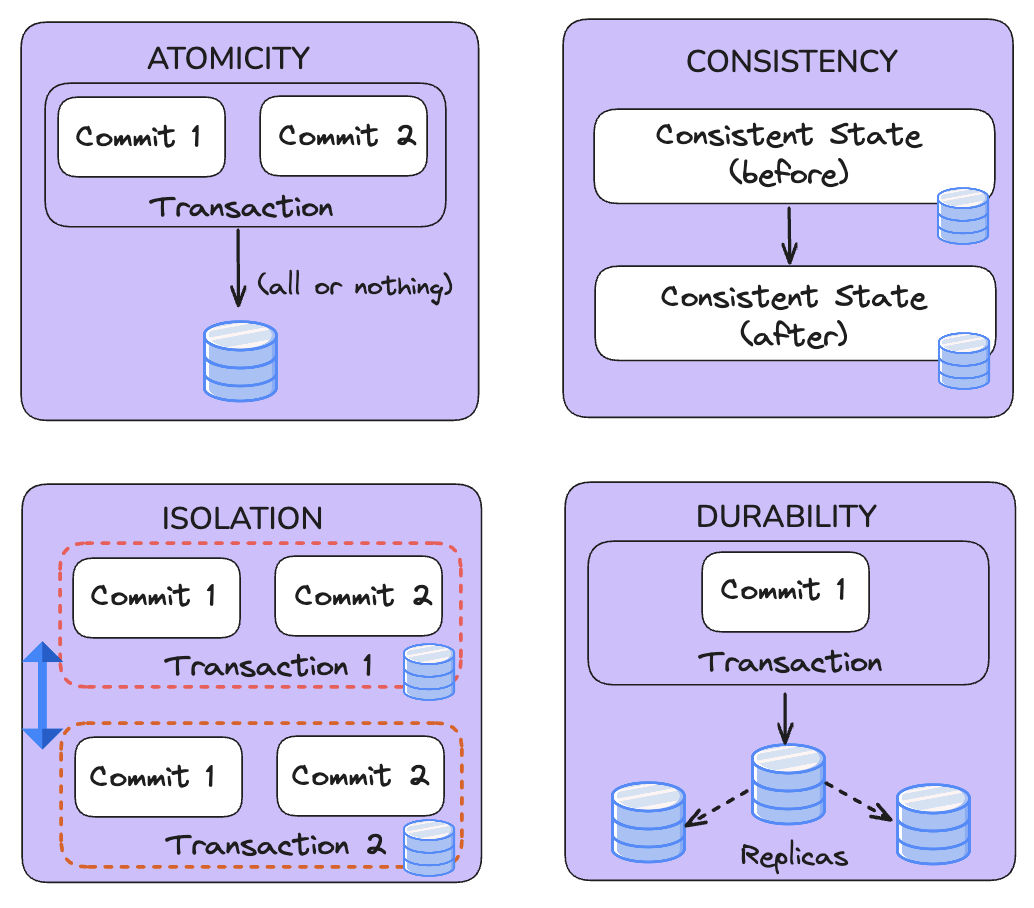
What is ACID on a Data Lake?July 17, 2026 by Sivabalan Narayananacidconcurrency controlhudi timelinedata lakehouse
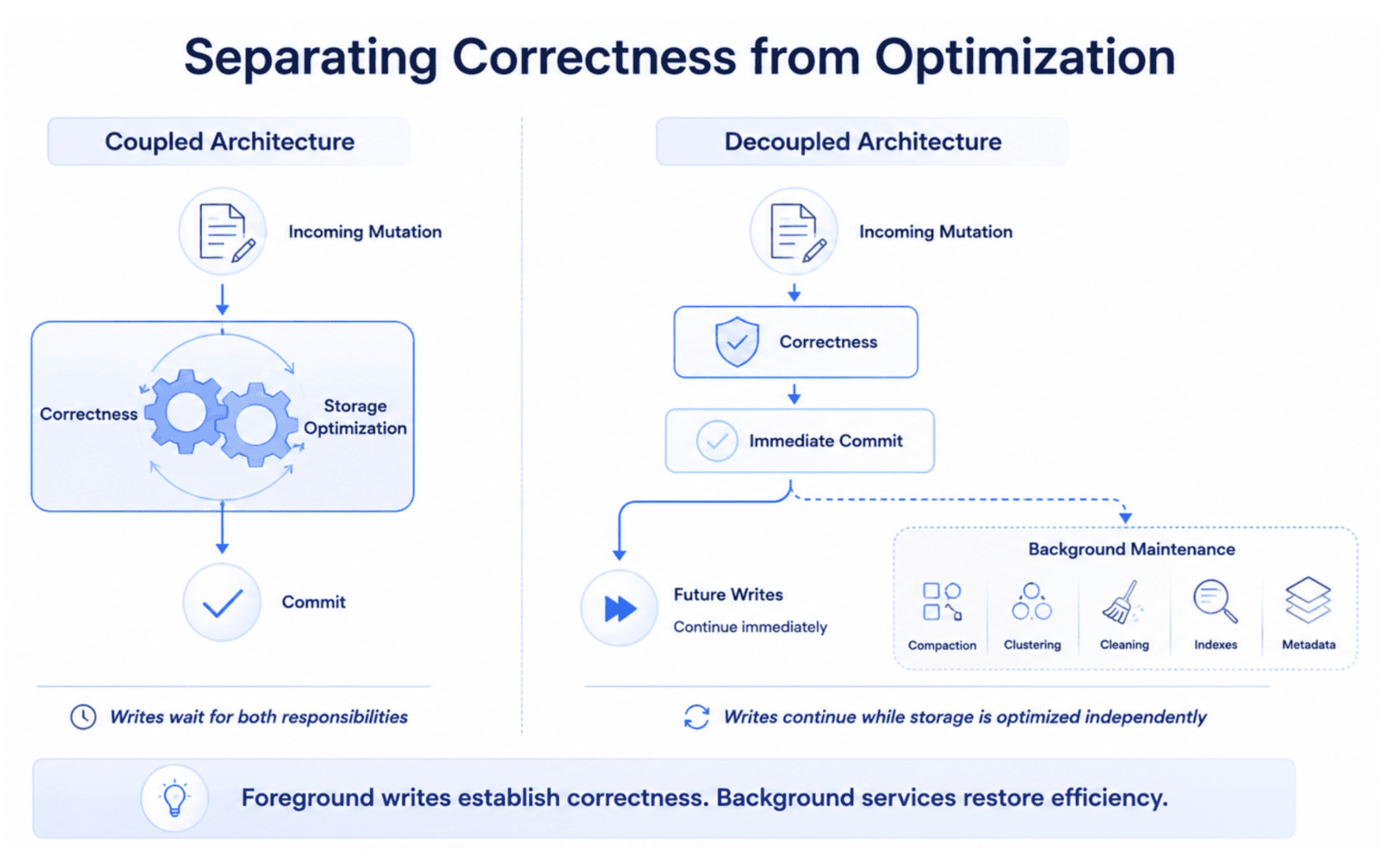
Can a Lakehouse Really Run Maintenance Without Blocking Writes?July 17, 2026 by Sivabalan Narayananmormerge on readcompactionarchitecturedata lakehousemetadataclustering
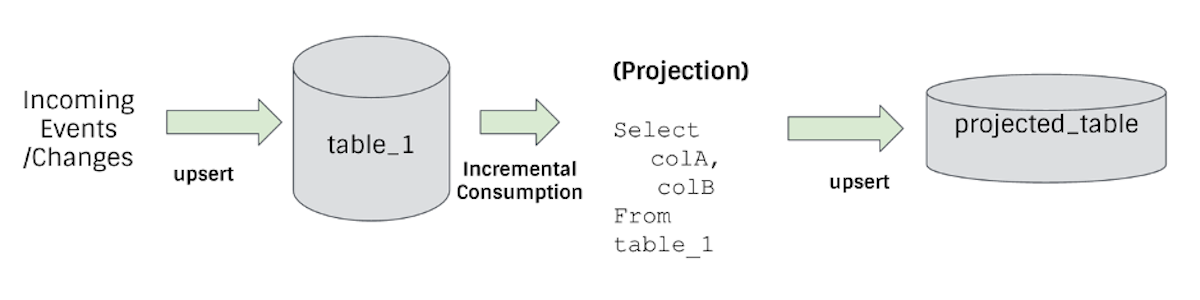
What is Incremental ETL on a Data Lake?July 16, 2026 by Vinoth Chandarincremental processingetlstreamingdata lakehousecdc
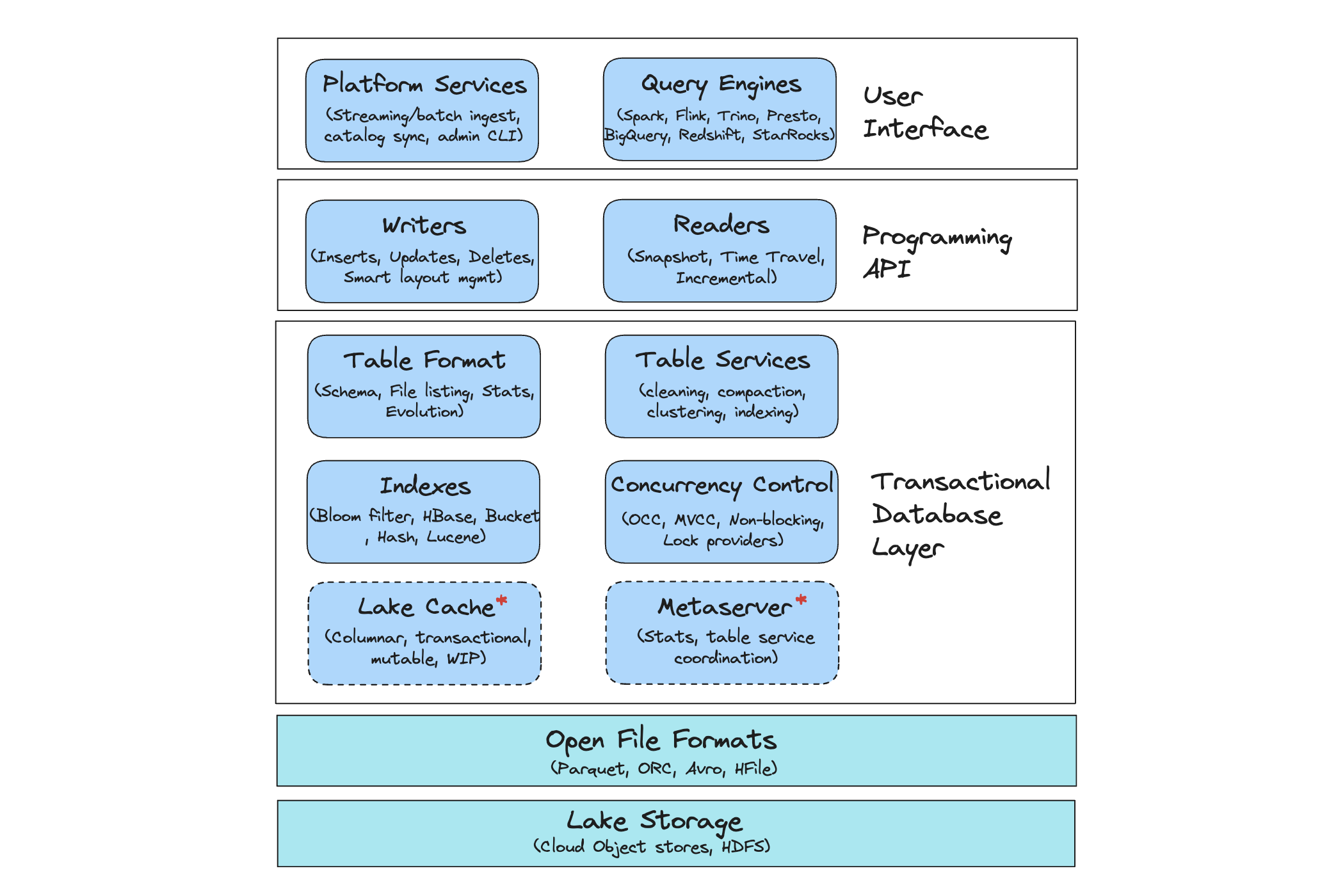
What is an Open Table Format?July 14, 2026 by Vinoth Chandartable formatdata lakehouseapache icebergdelta lakeopen architectureapache xtable
Bringing Vector Search to the Lakehouse with Apache HudiJuly 6, 2026 by Rahil Chertara and Aditya Goenkavectorvector searchairaglakehousedata lakehouseapache sparkarchitecturequerying
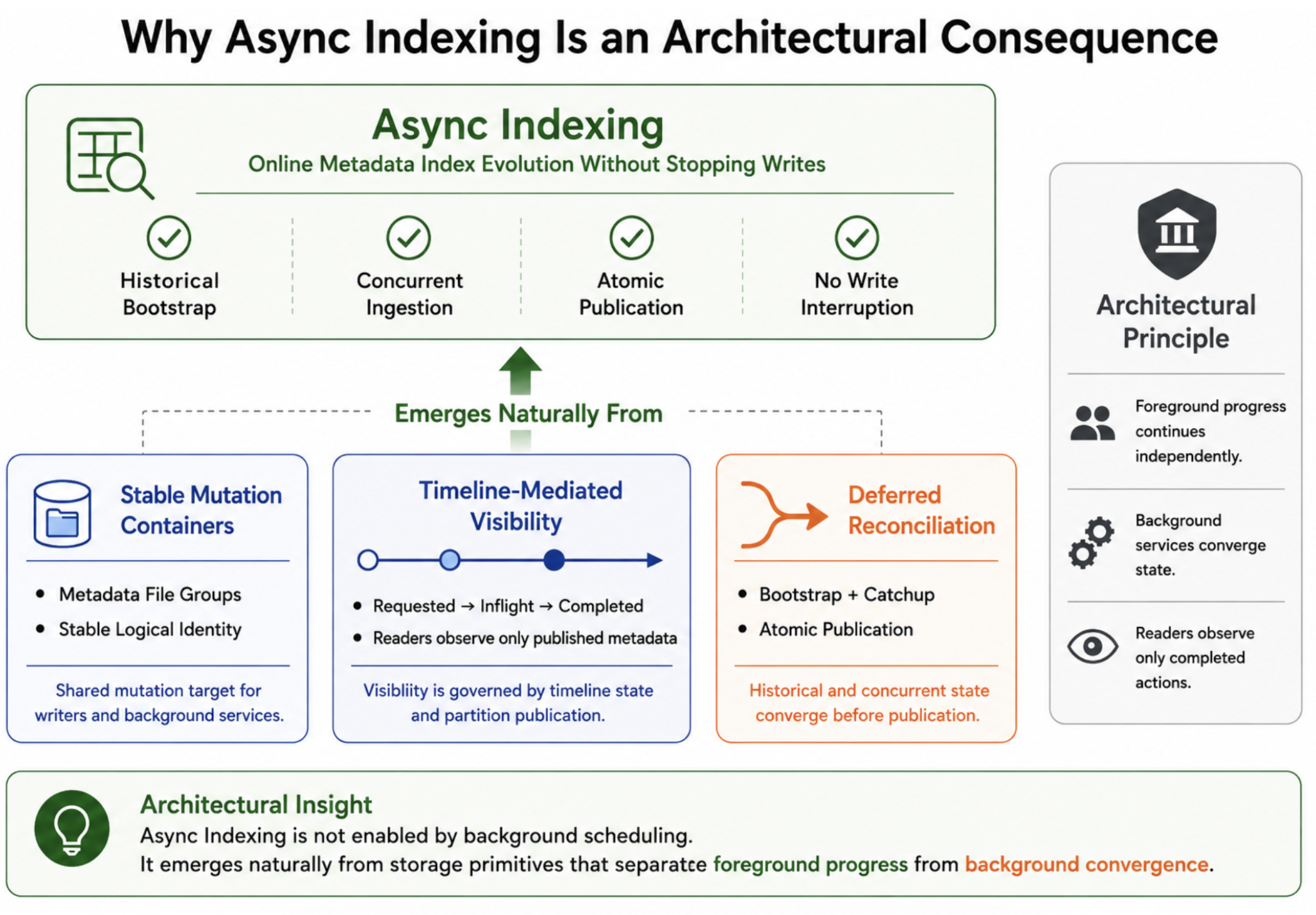
Building Indexes on a Moving TargetJune 25, 2026 by Sivabalan Narayananmormerge on readindexingasync indexingmetadataarchitecturedata lakehouse
Accelerating Data Operations: Metica's Journey with Apache HudiJune 15, 2026 by The Hudi Communitydata lakehousemeticaclusteringstarrocks