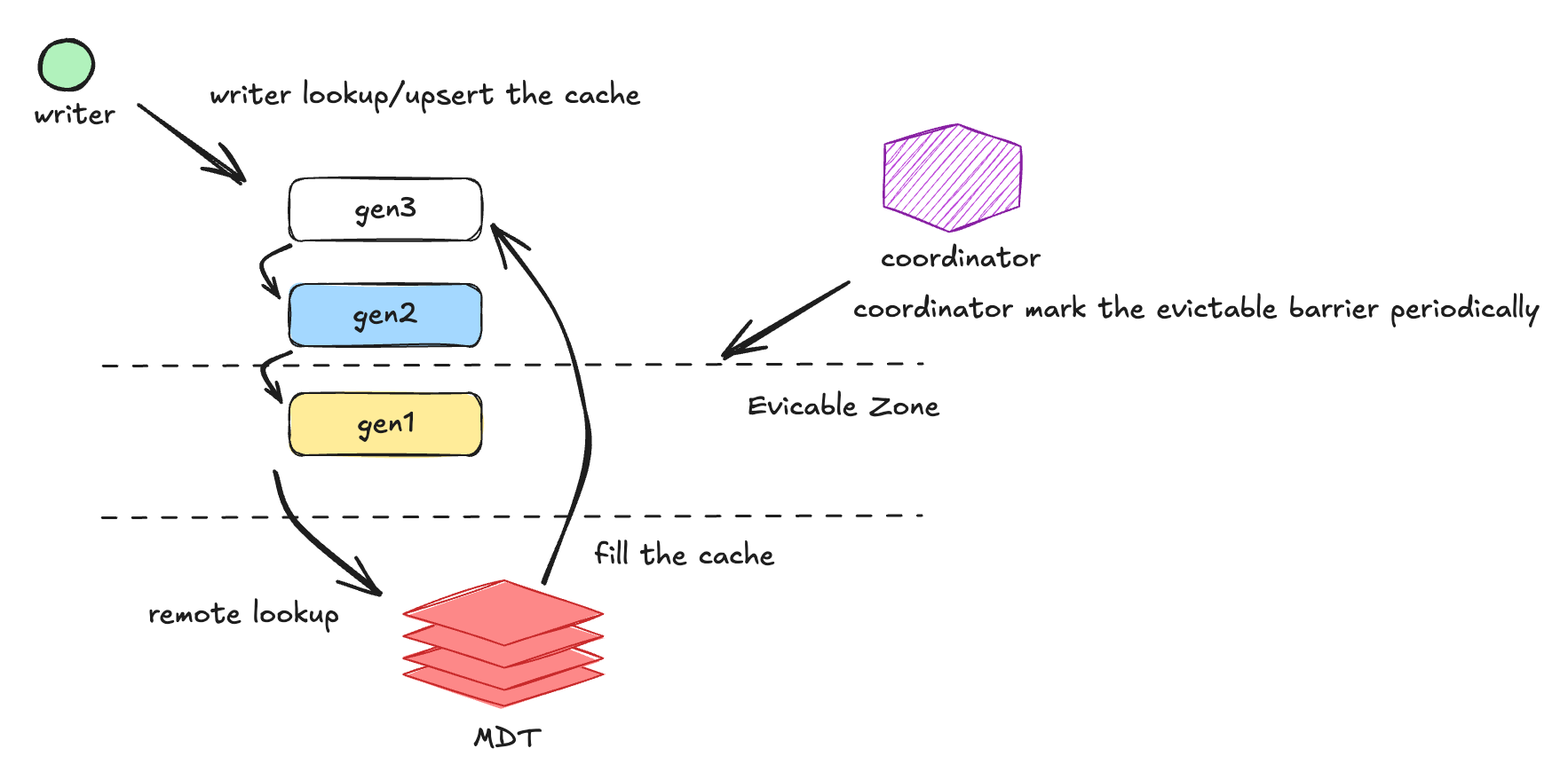
Stateless Global Upserts for Flink Streaming in Apache Hudi 1.2.0June 10, 2026 by Danny Chan and Shuo Chengapache flinkindexingrecord level indexrlistreamingmetadataperformancerelease
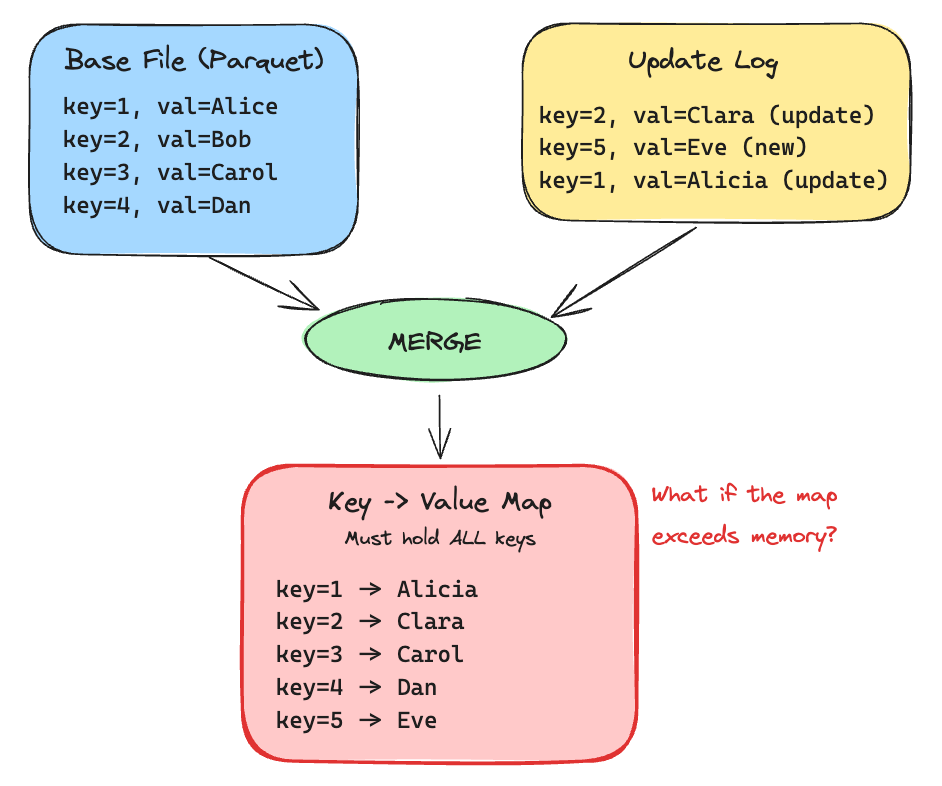
ExternalSpillableMap: Handle Maps Too Big for MemoryJanuary 13, 2026 by Yongkyunperformanceapache spark
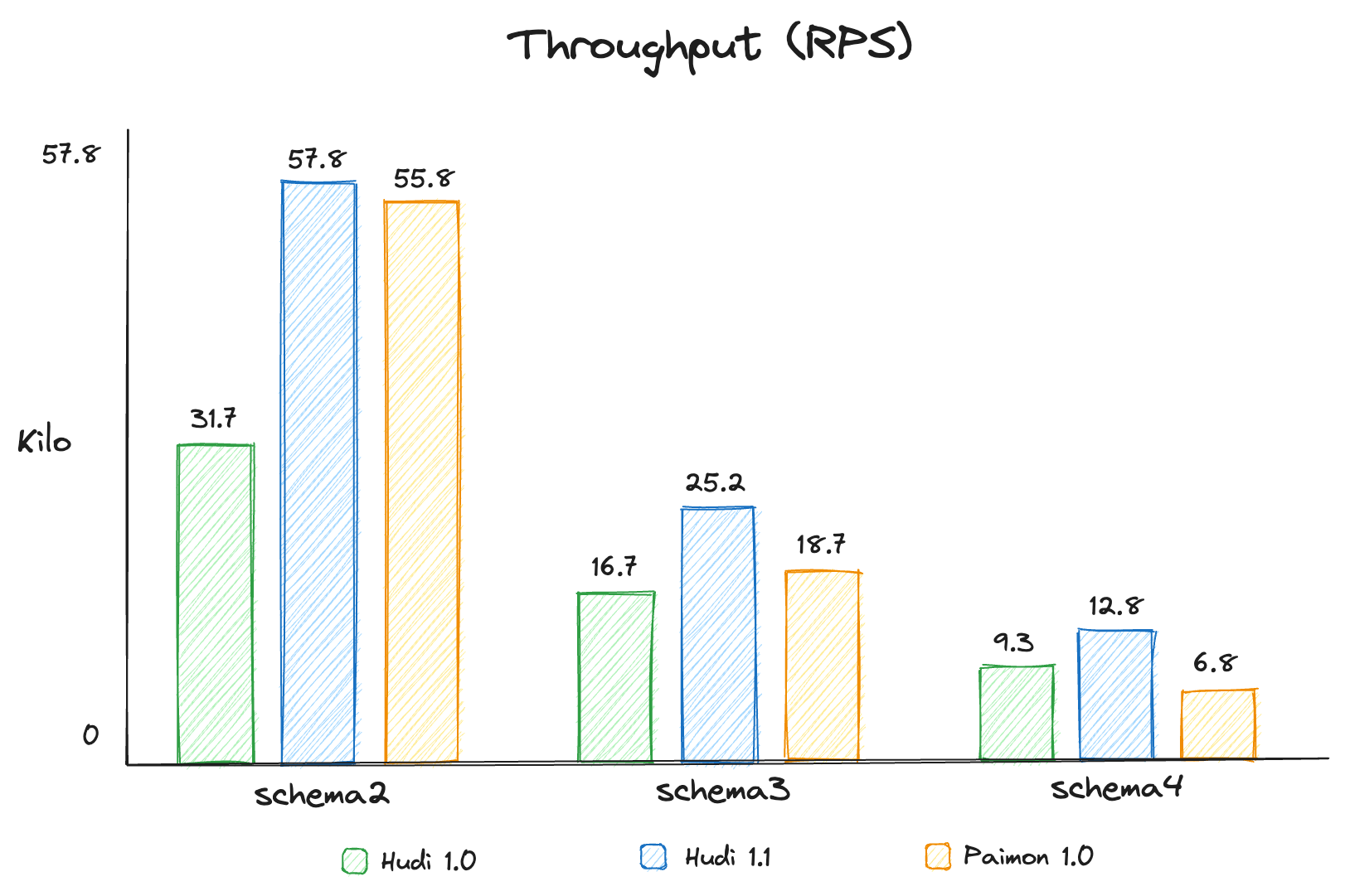
Apache Hudi 1.1 Deep Dive: Optimizing Streaming Ingestion with Apache FlinkDecember 10, 2025 by Shuo Chengapache flinkapache paimonperformance
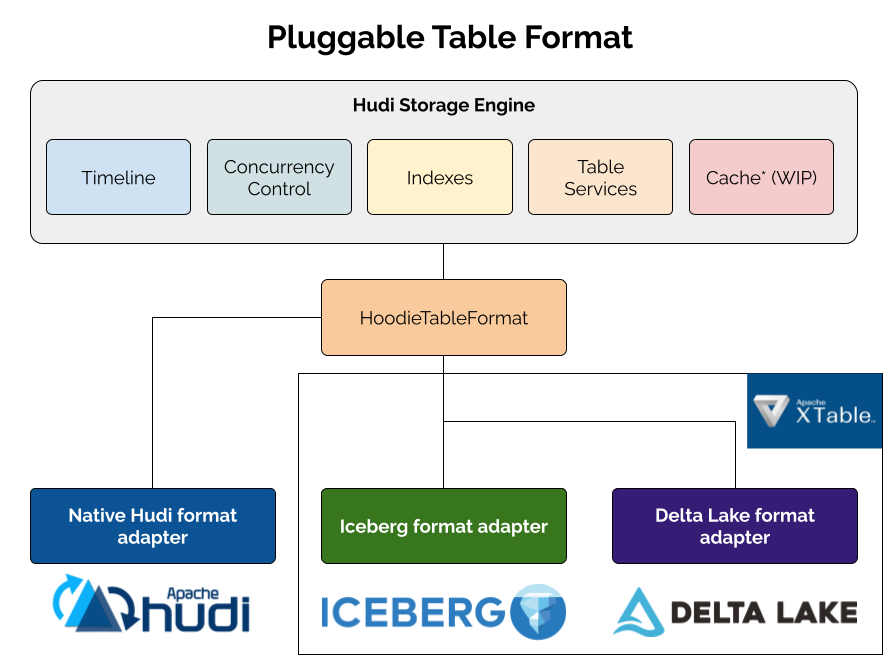
Apache Hudi 1.1 is Here—Building the Foundation for the Next Generation of LakehouseNovember 25, 2025 by Shiyan Xureleaseperformanceapache xtable
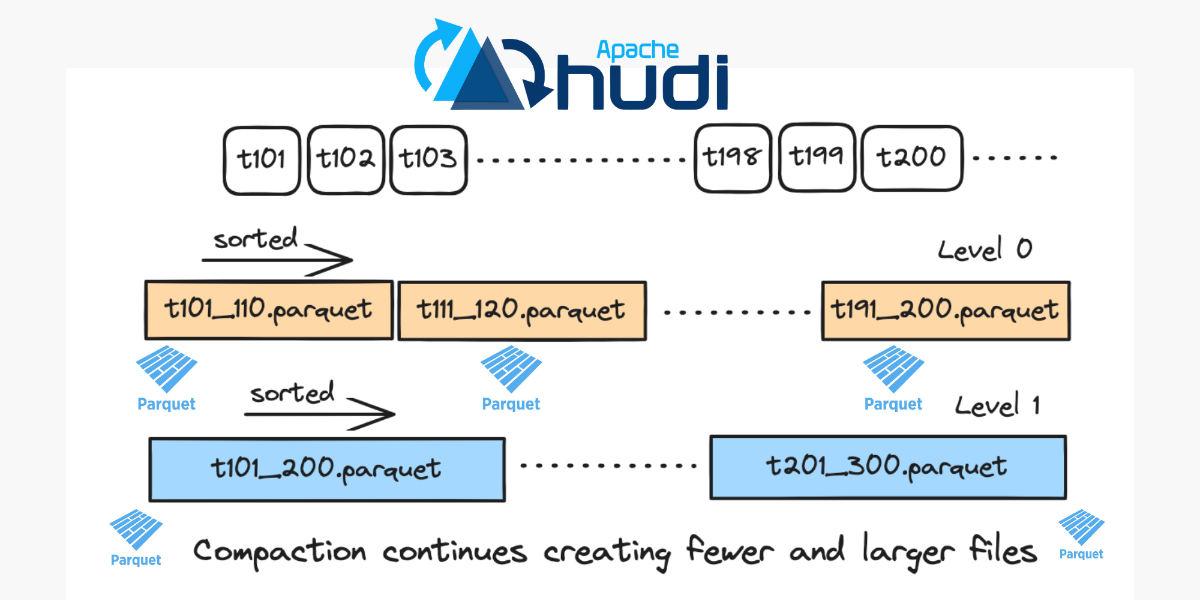
Exploring Apache Hudi’s New Log-Structured Merge (LSM) TimelineMay 29, 2025 by Dipankar Mazumdarlsm treeperformanceconcurrency control
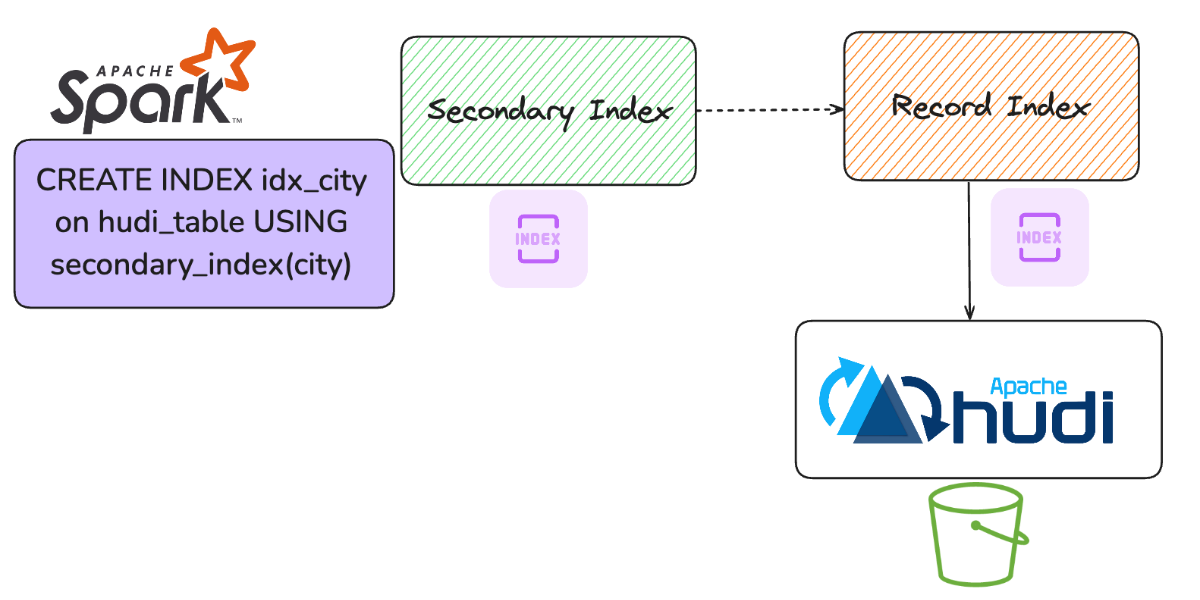
Introducing Secondary Index in Apache Hudi Lakehouse PlatformApril 2, 2025 by Dipankar Mazumdar and Aditya Goenkaindexingperformance
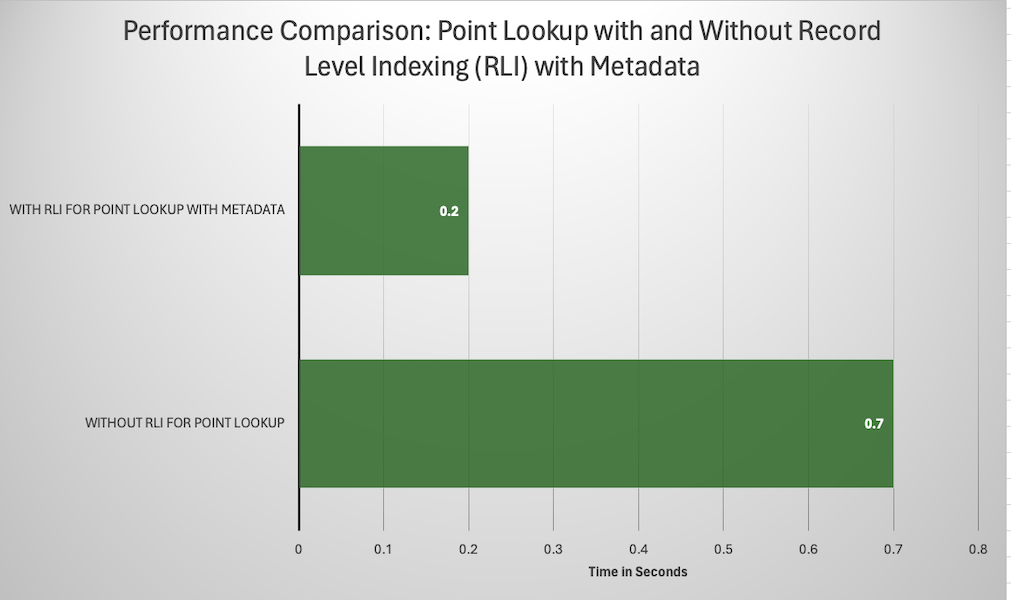
Record Level Indexing in Apache Hudi Delivers 70% Faster Point LookupsMarch 30, 2024 by Soumil Shahindexingperformance
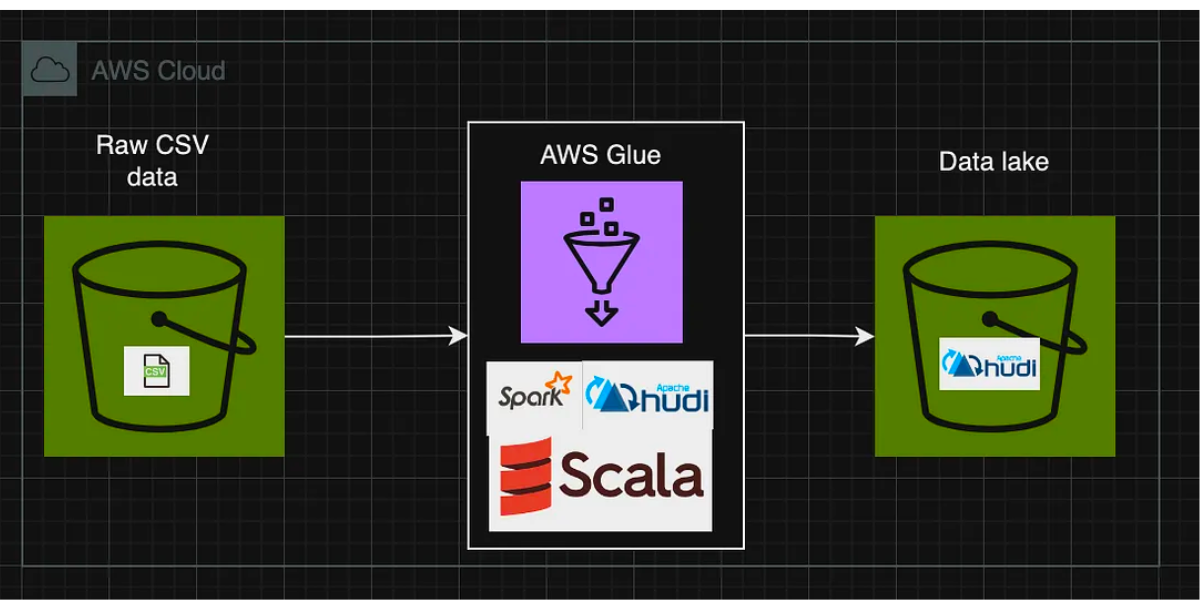
Cost Optimization Strategies for scalable Data LakehouseMarch 22, 2024 by Suresh Hasundiawsapache sparkdata lakehouseperformancehalodoc
Leverage Partition Paths of your data lake tables to Optimize Data Retrieval Costs on the cloudJanuary 30, 2024 by Krishna Prasadawsperformanceapache spark
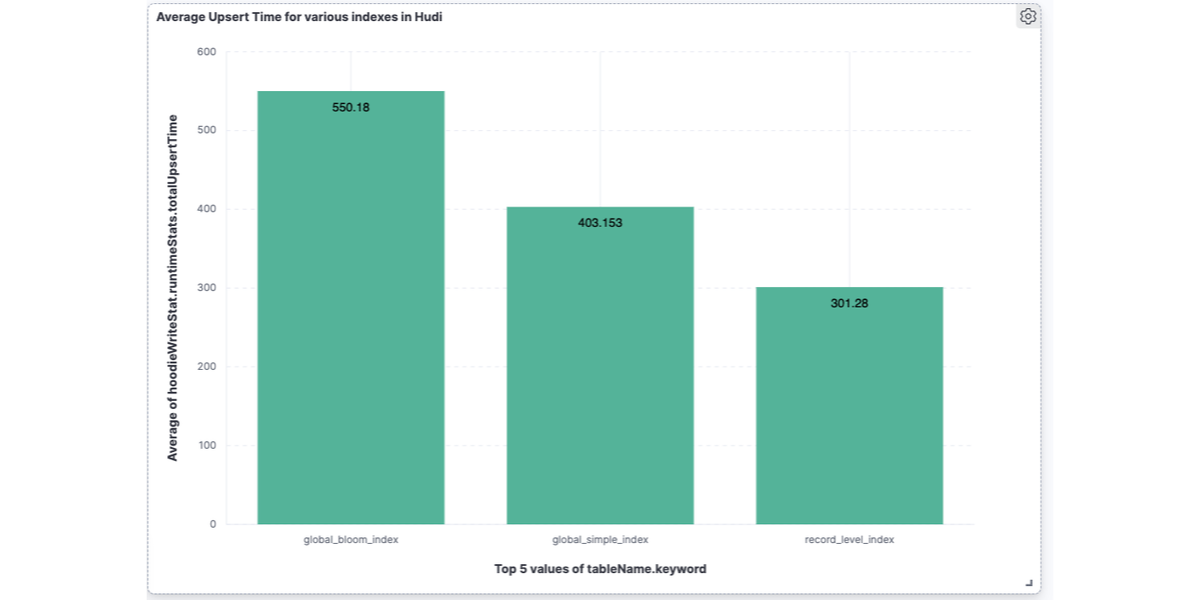
UPSERT Performance Evaluation of Hudi 0.14 and Spark 3.4.1: Record Level Index vs. Global Bloom & Global Simple IndexesOctober 29, 2023 by Soumil Shahqueryingindexingperformance
StarRocks query performance with Apache Hudi and OnehouseOctober 11, 2023 by Albert Wongstarrocksperformance
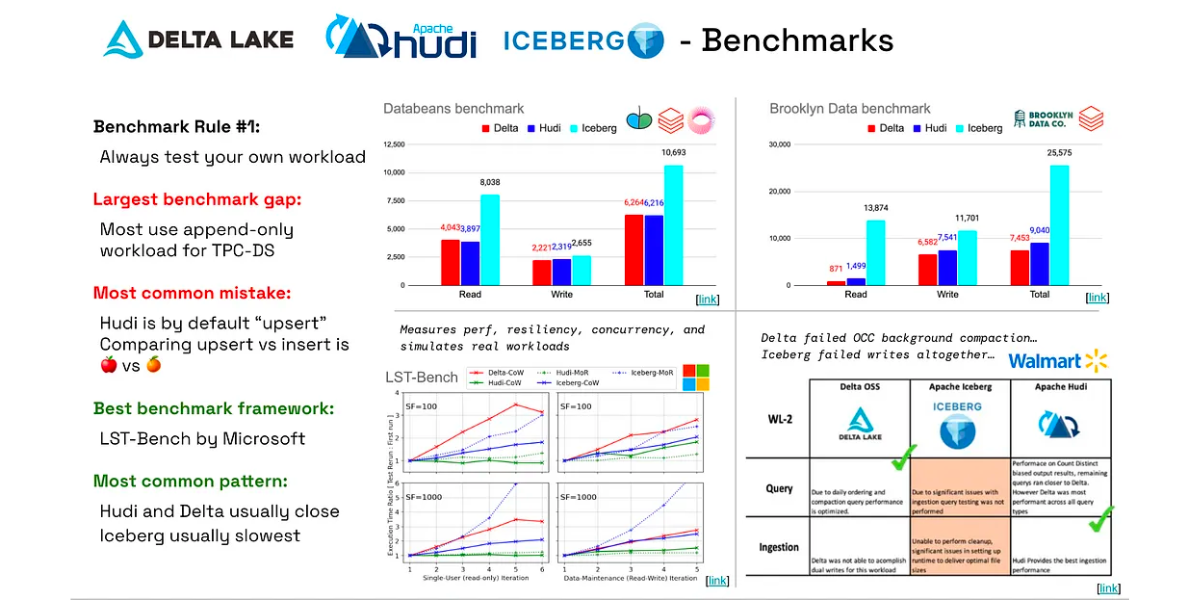
Delta, Hudi, Iceberg — A Benchmark CompilationAugust 28, 2023 by Kyle Wellerperformancedelta lakeapache iceberg