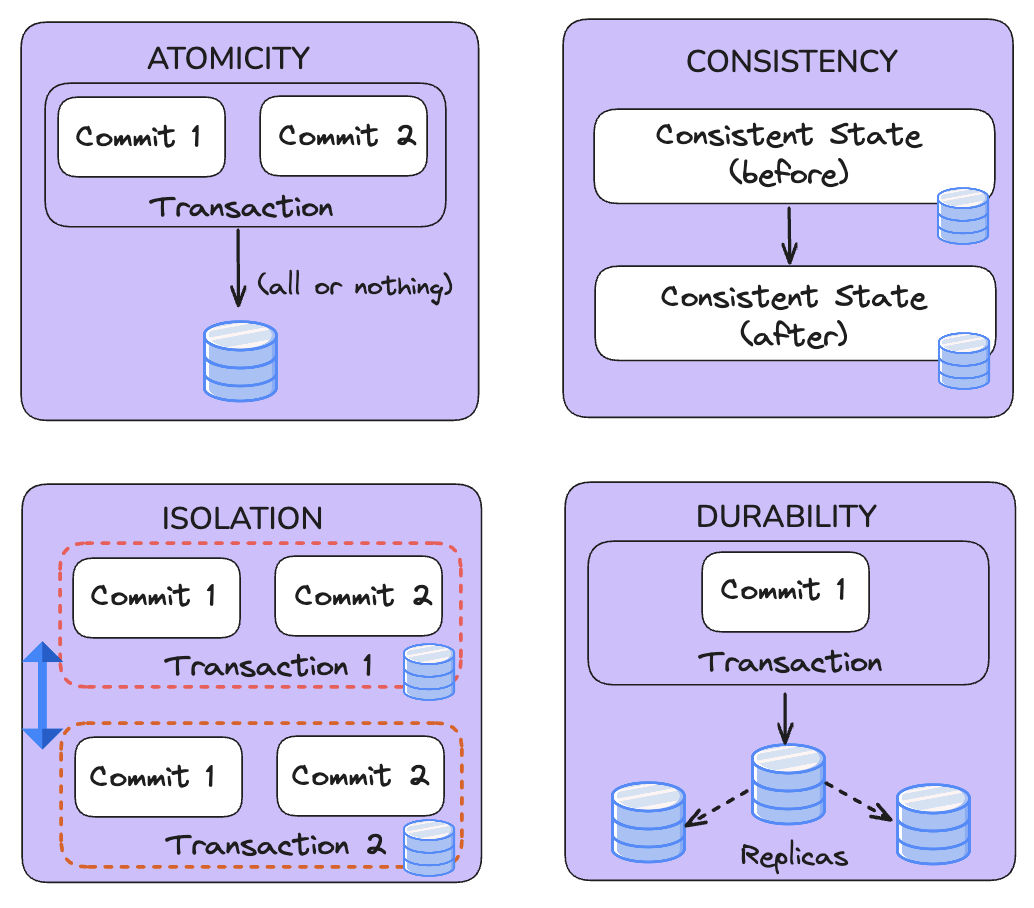
What is ACID on a Data Lake?July 17, 2026 by Sivabalan Narayananacidconcurrency controlhudi timelinedata lakehouse
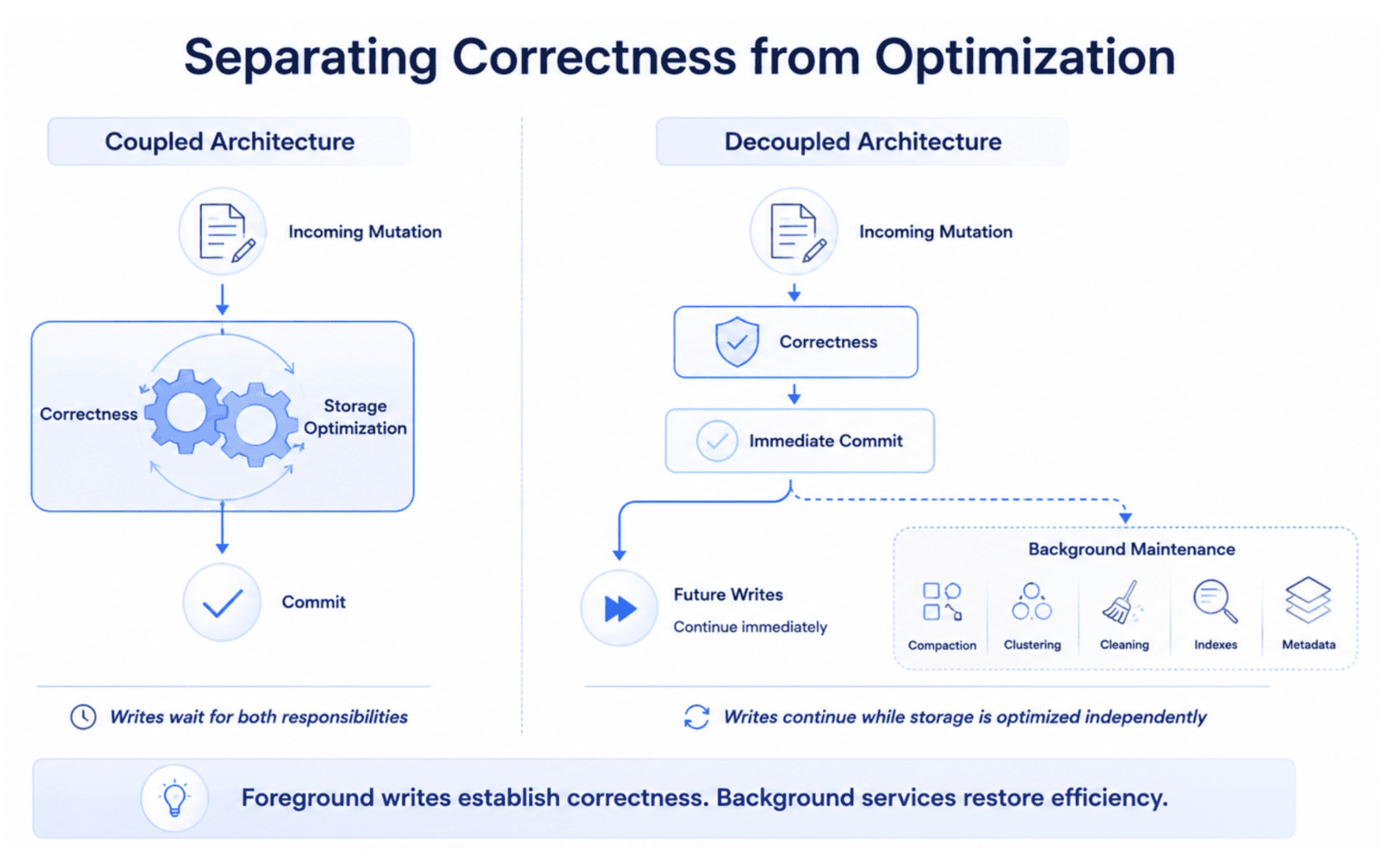
Can a Lakehouse Really Run Maintenance Without Blocking Writes?July 17, 2026 by Sivabalan Narayananmormerge on readcompactionarchitecturedata lakehousemetadataclustering
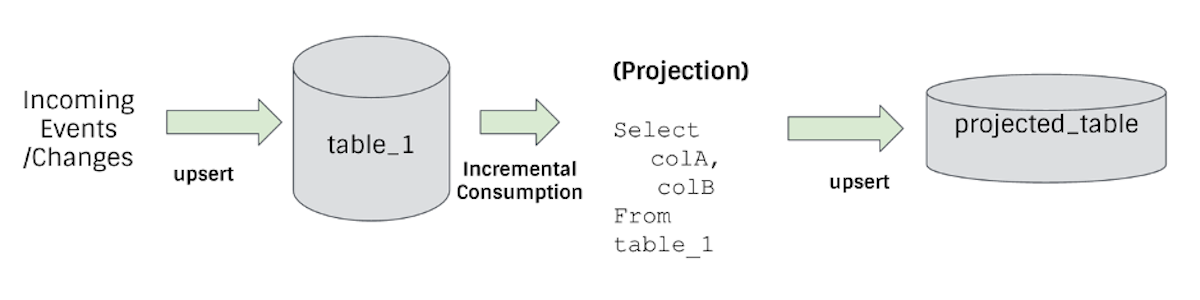
What is Incremental ETL on a Data Lake?July 16, 2026 by Vinoth Chandarincremental processingetlstreamingdata lakehousecdc
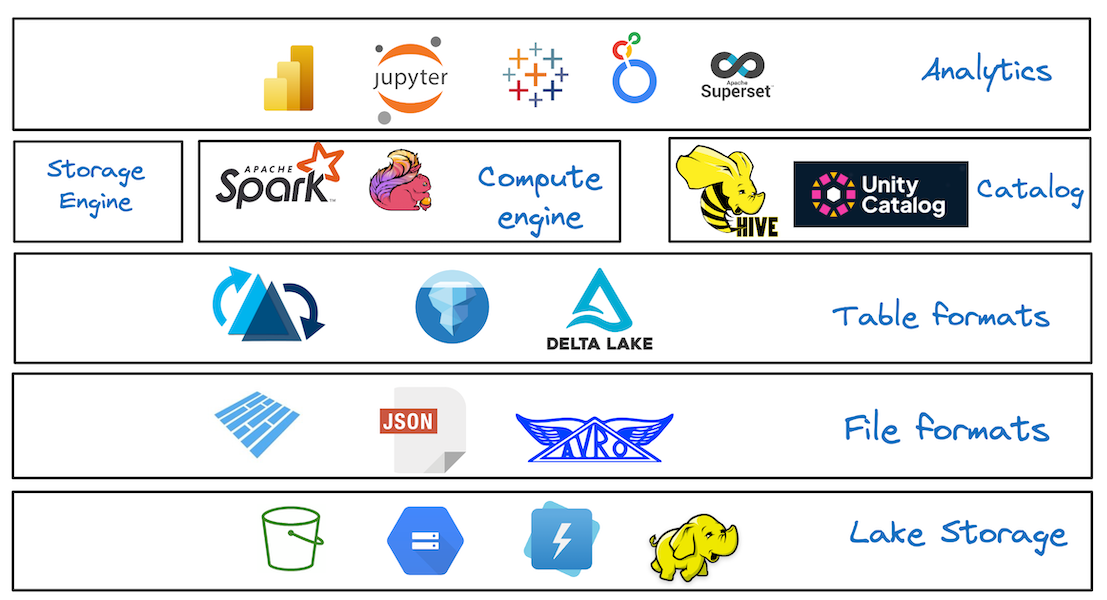
What is an Open Table Format?July 14, 2026 by Vinoth Chandartable formatdata lakehouseapache icebergdelta lakeopen architectureapache xtable
Bringing Vector Search to the Lakehouse with Apache HudiJuly 6, 2026 by Rahil Chertara and Aditya Goenkavectorvector searchairaglakehousedata lakehouseapache sparkarchitecturequerying
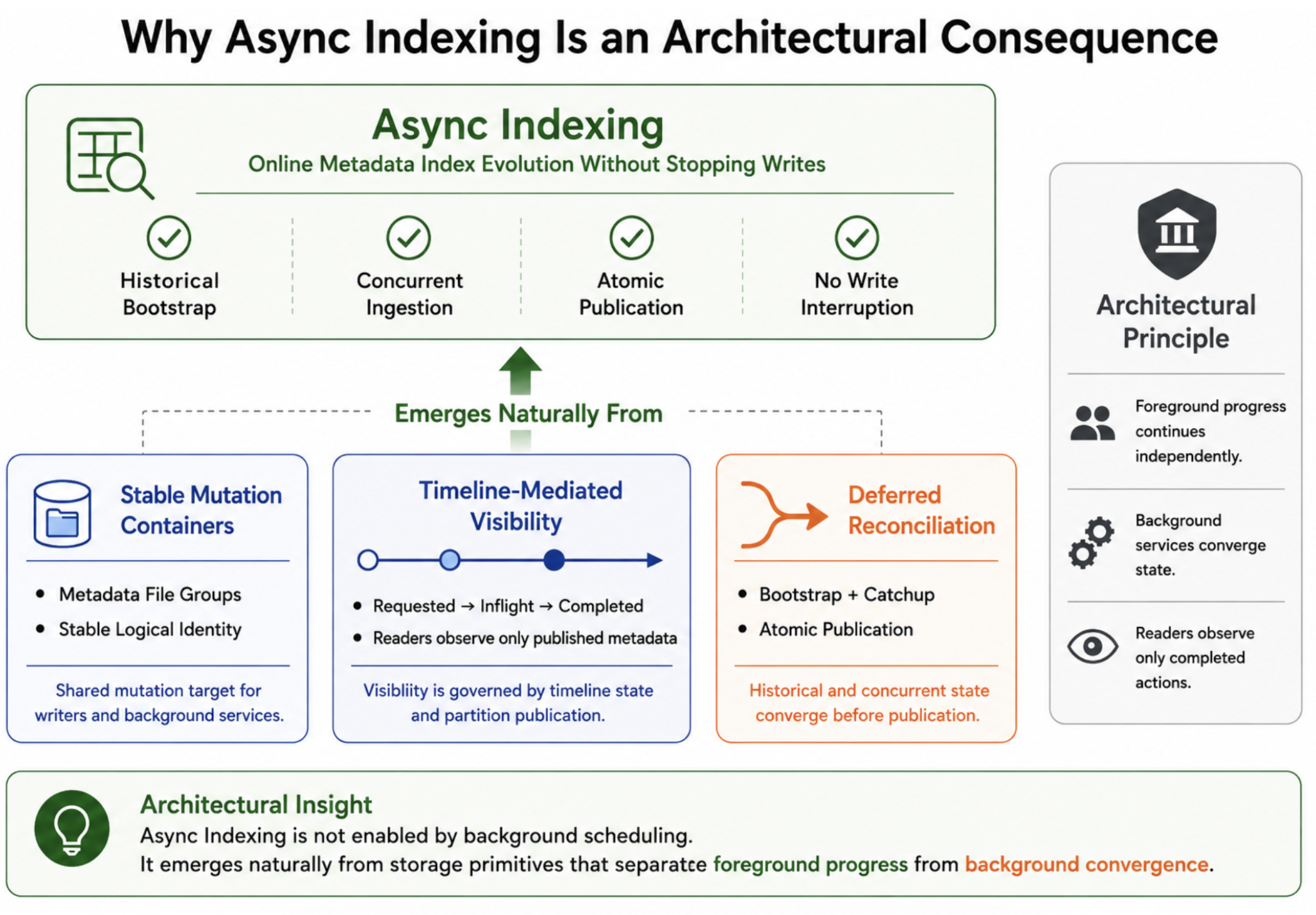
Building Indexes on a Moving TargetJune 25, 2026 by Sivabalan Narayananmormerge on readindexingasync indexingmetadataarchitecturedata lakehouse
Accelerating Data Operations: Metica's Journey with Apache HudiJune 15, 2026 by The Hudi Communitydata lakehousemeticaclusteringstarrocks
From Concept to Reality: Apache Hudi at the Foundation of Penn Entertainment's Data PlatformJune 15, 2026 by The Hudi Communitydata lakehousepenn interactive
Modernizing Data Infrastructure at Southwest with Apache HudiJune 15, 2026 by The Hudi Communitydata lakehousesouthwest airlines
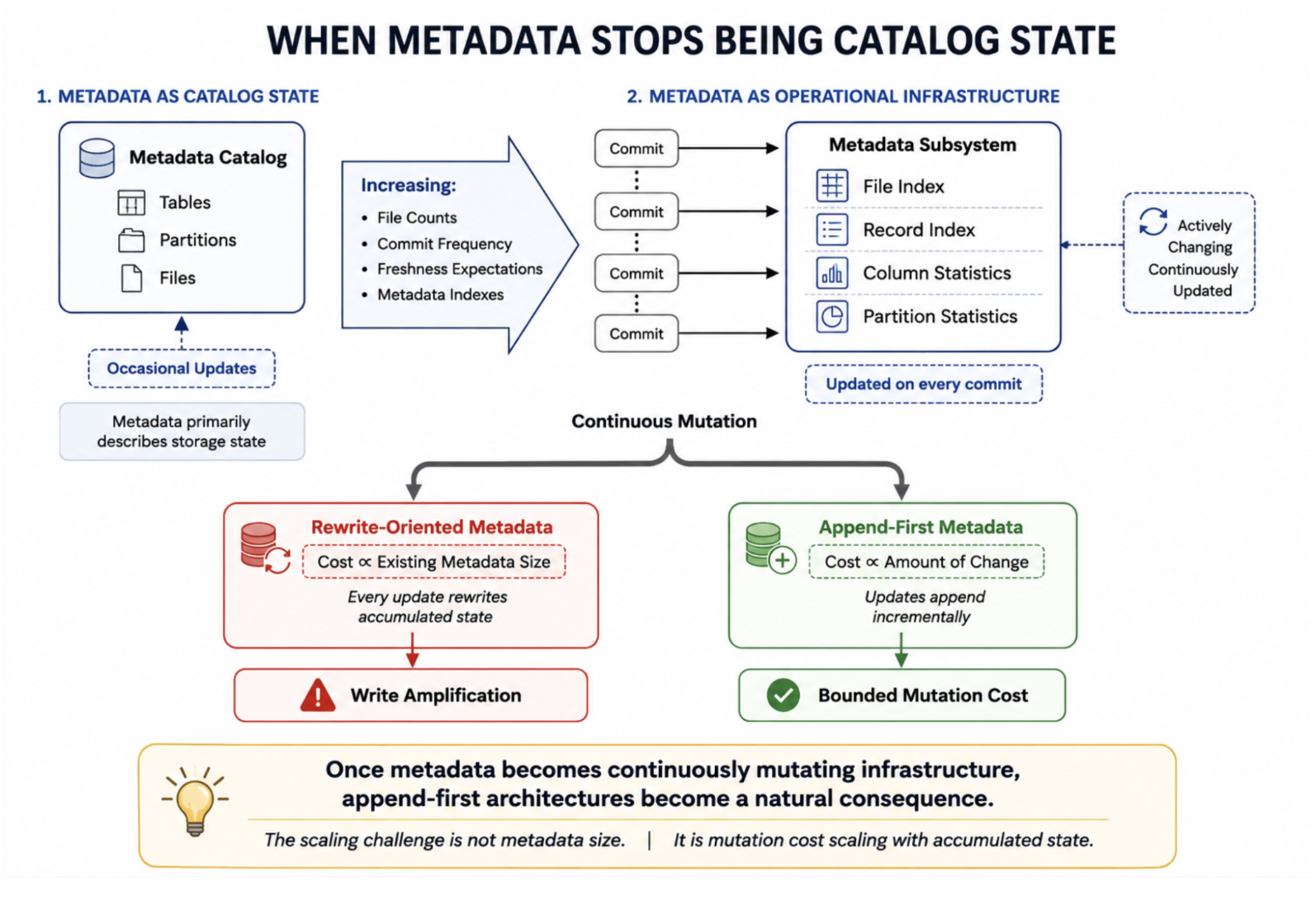
Why Metadata Has to Be Mutation-FriendlyJune 5, 2026 by Sivabalan Narayananmetadatamormerge on readindexingarchitecturedata lakehousestreaming
Scaling Autonomous Vehicle Data Infrastructure with Apache Hudi at Applied IntuitionJanuary 22, 2026 by The Hudi Communitydata lakehouseapplied intuition