Introducing Secondary Index in Apache Hudi Lakehouse Platform


A secondary index in Apache Hudi is an index on any column other than the record key (primary key), introduced in Hudi 1.0, that maps secondary key values to record keys so queries filtering on non-primary-key fields can skip irrelevant data files instead of scanning the whole table.
Apache Hudi 1.0 introduces Secondary Indexes, enabling faster queries on non-primary key fields. This improves data retrieval in Lakehouse architectures by reducing data scans. Hudi also offers asynchronous indexing for scalability and efficient index maintenance without disrupting data ingestion. By the end of this blog, you'll understand how these features enhance Hudi's capabilities as a high-performance lakehouse platform.
Indexes are a fundamental data structure that enables efficient data retrieval by eliminating the need to scan the entire dataset for every query. In the context of a Lakehouse, where records are written as immutable data files (such as Parquet) at scale, indexing becomes crucial in reducing lookup times. Otherwise, a lot of time will be spent by the compute engine on finding out where exactly a particular record exists amongst thousands of files in the data lake storage, which is computationally expensive at scale. Indexing is not only important for reads in a lakehouse architecture, but also for writes, such as upserts and deletes, as you need to know where the record is to update it.
One of the standout design choices in Apache Hudi that separates it from other lakehouse formats is its indexing capability, which has been central to its architecture from the beginning. Hudi is heavily optimized to handle mutable change streams with varying write patterns, and indexing plays a pivotal role in making upserts and deletes efficient.
Hudi's indexing mechanism is designed to efficiently manage record lookups and updates by maintaining a structured mapping between records and file groups. Here's how it works:
-
The first time a record is ingested into Hudi, it is assigned to a File Group - a logical grouping of files. This assignment typically remains unchanged throughout the record's lifecycle. However, in cases such as clustering or cross-partition updates, the record may be remapped to a different file group. Even in such scenarios, Hudi ensures that a given record key is associated with exactly one file group at any completed instant on the timeline
-
Hudi maintains a mapping between the incoming record’s key (unique identifier) and the File Group where it resides.
-
The index is responsible for quickly locating records based on this File Group mapping, eliminating the need for full dataset scans.
This strategy allows Hudi to determine whether a record exists and pinpoint its exact location, enabling faster upserts and deletes.
For a comprehensive tour of how secondary indexes fit into Hudi 1.x's broader indexing subsystem, see Deep Dive Into Hudi's Indexing Subsystem Part 2.
Apache Hudi's Multi-Modal Indexing System
While Hudi’s indexes have set a benchmark for fast writes, bringing those advantages to queries was equally important. This led to the design of a generalized indexing subsystem that enhances performance in the lakehouse. Hudi’s multi-modal indexing redefines indexing in data lakes by employing multiple index types, each optimized for different workloads and query patterns. It is built on scalable metadata that supports multiple index types without extra overhead, ACID-compliant updates to keep indexes in sync with the data table, and optimized lookups that minimize full scans for low-latency queries on large datasets.
At the core of Hudi’s indexing design is its metadata table, a specialized Merge-on-Read table that houses multiple index types as separate partitions. These indexes serve various purposes, improving the efficiency of reads, writes, and upserts.
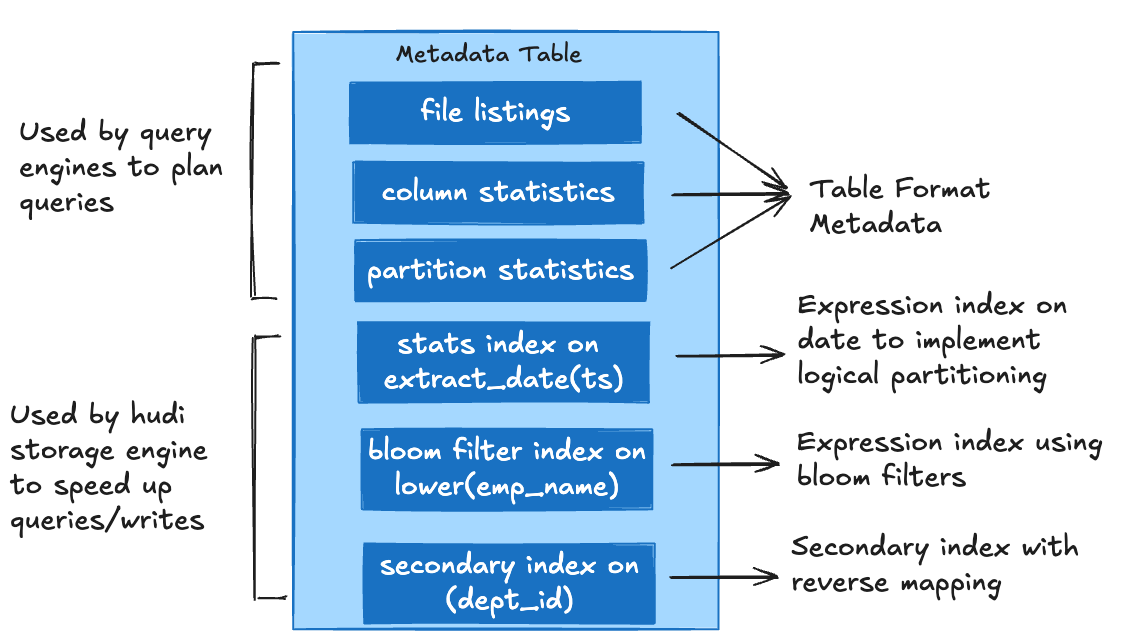
Some key indexes within Hudi’s metadata table include:
- File Index - Stores a compact listing of files, reducing the overhead of expensive file system operations.
- Column Stats Index - Tracks min/max statistics for each column, enabling more effective data pruning.
- Bloom Filter Index - Stores precomputed bloom filters for all data files, optimizing record lookups.
- Partition Stats Index - Stores aggregated partition-related information which helps in efficient partition pruning by skipping entire folders very quickly.
- Record-Level Index - Maintains direct mappings to individual records, facilitating faster upserts and deletes.
- Secondary Index - Allow users to create indexes on columns that are not part of record key columns in Hudi tables.
By structuring these indexes as individual partitions within the metadata table, Hudi ensures efficient retrieval, quick lookups, and scalability, even as the data volume grows. In this blog, we will focus on secondary indexes and understand how it can help accelerate query performance in a lakehouse.
Introducing Secondary Index
A secondary index is an indexing mechanism commonly used in database systems to provide efficient access to records based on non-primary key attributes. Unlike primary indexes, which enforce uniqueness and define the main data layout, secondary indexes serve as auxiliary data structures that accelerate lookups on fields that are frequently queried but are not the primary key.
For example, in an OLTP (Online Transaction Processing) database, a primary index might be defined on a unique order_id, whereas a secondary index could be created on customer_id to quickly fetch all orders placed by a specific customer. Secondary indexes enhance query performance by reducing the need for full table scans, especially in analytical workloads that involve complex filtering or joins.
With Hudi 1.0, Apache Hudi introduces secondary indexes, bringing database-style indexing capabilities to the Lakehouse. Secondary indexes allow queries to scan significantly fewer files, reducing query latency and compute costs. This is especially beneficial for cloud-based query engines (such as AWS Athena), where pricing is based on the amount of data scanned. A secondary index in Hudi allows users to index any column beyond the record key (primary key), making queries on non-primary key fields much faster. This extends Hudi’s existing record-level index, which optimizes writes and reads based on the record key.
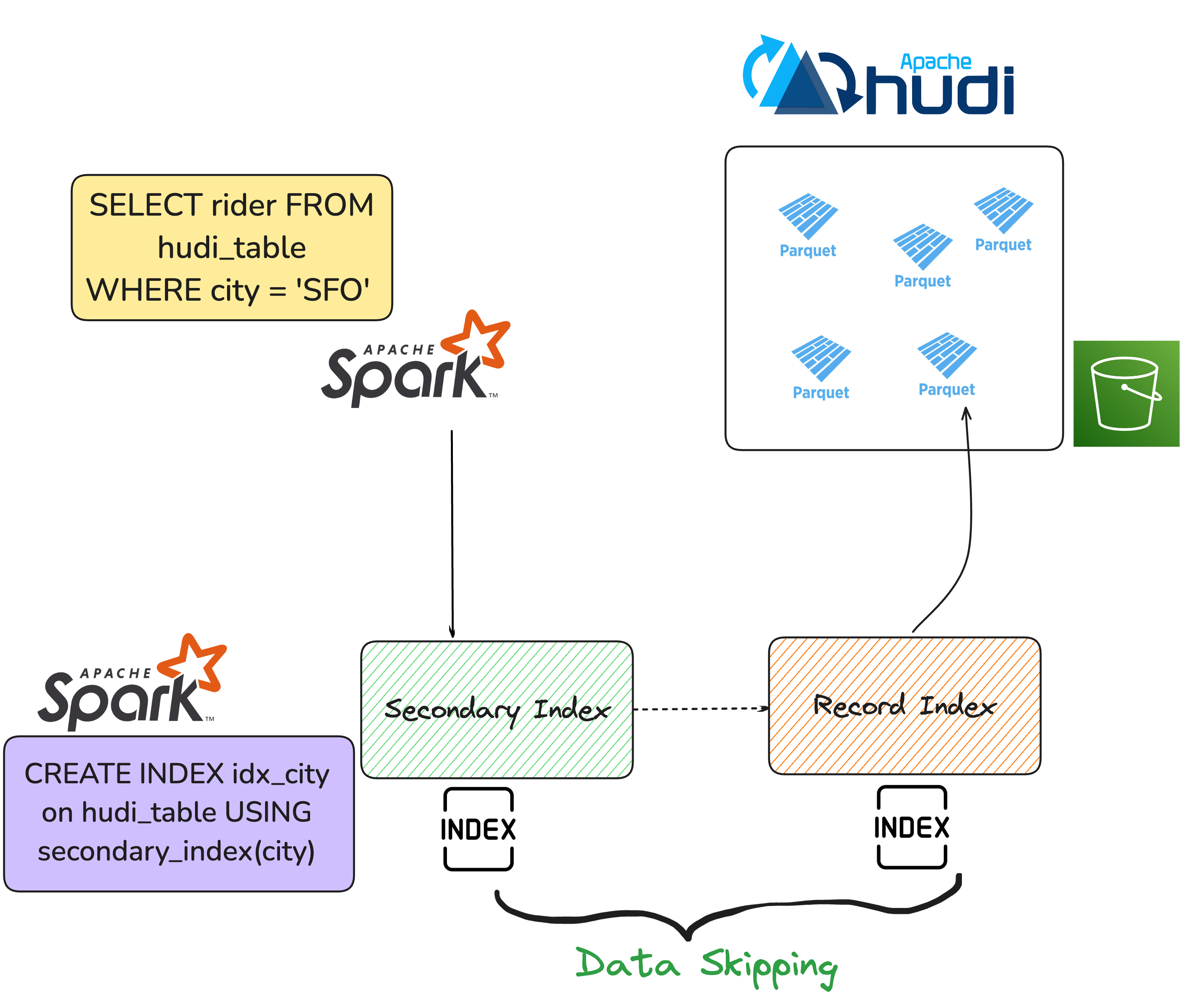
Here is how the secondary index works in Hudi.
- Indexes Non-Primary Key Columns: Unlike the record-level index, which tracks record keys, secondary indexes help accelerate queries on fields outside the primary key.
- Stores Mappings Between Secondary and Primary Keys: Hudi maintains a mapping between secondary keys (e.g., city, driver) and record keys, enabling fast lookups for non-primary key queries.
- Minimizes Data Scans via Index-Aware Query Execution: During query execution, the secondary index enables data skipping, allowing Hudi to prune unnecessary files before scanning.
- SQL-Based Index Management: Users can create, drop, and manage indexes using SQL, making secondary indexes easily accessible.
Hudi supports hash-based secondary indexes, which are horizontally scalable by distributing keys across shards for fast writes and lookups.
If you are interested in the implementation details of secondary indexes, you can read more here.
Creating a Secondary Index in Hudi
In Hudi 1.0, secondary indexes are supported currently in Apache Spark, with future support planned for Flink, Presto, and Trino in Hudi 1.1.
Let’s see an example of creating a Hudi table with a secondary index.
First, let’s create a table with a record index enabled. The record index maintains mappings of record keys (id) to file groups, enabling fast updates, deletes, and lookups.
DROP TABLE IF EXISTS hudi_table;
CREATE TABLE hudi_table (
ts BIGINT,
id STRING,
rider STRING,
driver STRING,
fare DOUBLE,
city STRING,
state STRING
) USING hudi
OPTIONS (
primaryKey = 'id',
hoodie.metadata.record.index.enable = 'true', -- Enable record index
hoodie.write.record.merge.mode = "COMMIT_TIME_ORDERING" -- Only Required for 1.0.0 version
)
PARTITIONED BY (city, state)
LOCATION 'file:///tmp/hudi_test_table';
Now we can create a secondary index on the city field to optimize queries filtering on this column.
CREATE INDEX idx_city ON hudi_table(city);
Now, when executing a query such as:
SELECT rider FROM hudi_table WHERE city = 'SFO';
✅ Hudi first checks the secondary index to determine which records match the filter condition.
✅ It then uses the record index to locate the exact file group for retrieval.
✅ Data skipping is applied, reducing the number of files read from cloud storage.
Users can also create secondary indexes using the Spark DataSource API by setting the following configurations:
| Config Name | Default | Description |
|---|---|---|
hoodie.metadata.index.secondary.enable | true | Enables secondary index maintenance. When true, Hudi writers automatically maintain all secondary indexes within the metadata table. When disabled, secondary indexes must be created manually using SQL. |
hoodie.datasource.write.secondarykey.column | (N/A) | Specifies the columns to be used as secondary keys. Supports dot notation for nested fields (e.g., customer.region). |
Asynchronous Indexing in Hudi
A notable thing about Hudi’s indexing system is that it offers asynchronous indexing as a service. Traditional indexing approaches often introduce performance bottlenecks, as index maintenance needs to be performed synchronously with writes. Hudi’s asynchronous indexing service eliminates the performance bottlenecks of traditional indexing by decoupling index maintenance from ingestion. Instead of requiring synchronous updates that slow down writes, Hudi builds indexes in the background, ensuring ingestion remains uninterrupted.
A key aspect of this design is timeline-consistent indexing, where a new indexing action is introduced in Hudi’s transactional timeline. The indexer service schedules indexing by adding an indexing.requested instant, moves it to inflight during execution, and finally marks it completed once indexing is done, without locking index file writes. This enables a scalable indexing framework, allowing indexes to be dynamically added or removed without downtime as datasets grow. Async indexing also supports multiple index types, including secondary indexes.
Benchmarking
We ran a simple benchmark using the TPCDS 1TB dataset, created the index on one of the fact table web_sales and ran a complex join query with lookup on customer id.
Setup:
- Uses 1TB TPCDS public dataset.
- Apache Spark version - 3.5.5 installed on EMR cluster
- Apache Hudi version - 1.0.1
- Table on which secondary index is created -
web_sales - Column on which Secondary Index is created -
ws_ship_customer_sk - Cluster Configurations
- Nodes: m5.xlarge (10 executors)
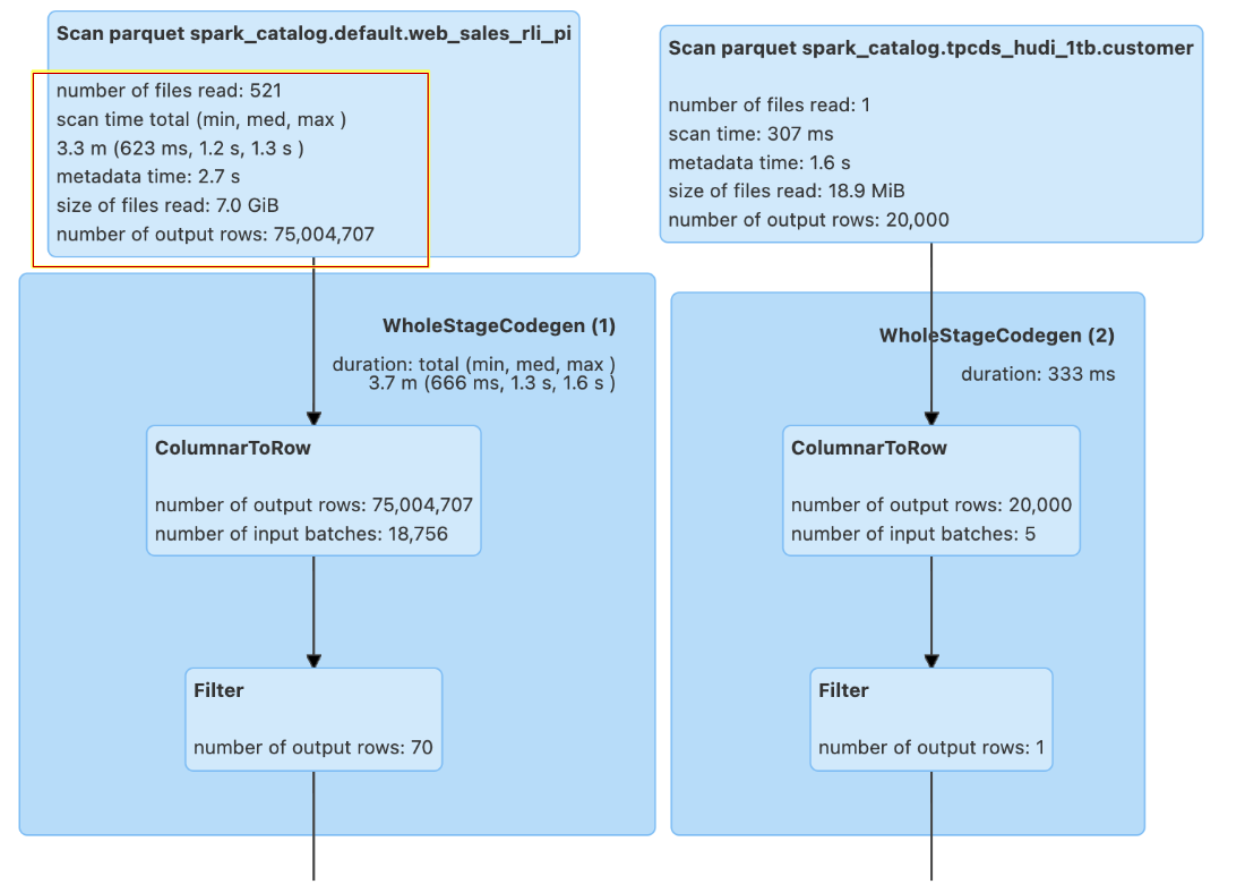
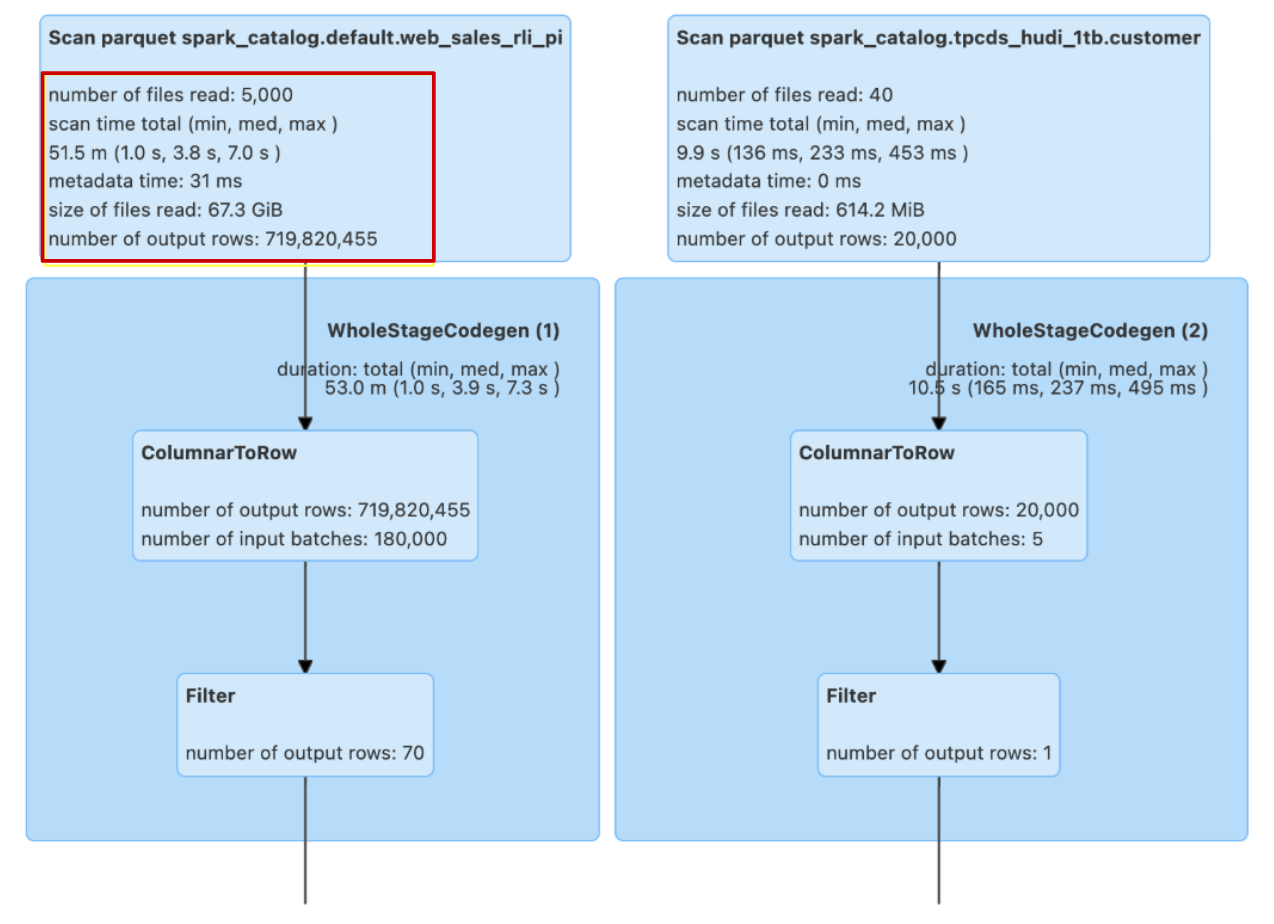
To evaluate performance, we executed the same query multiple times within the same Spark session. The table below demonstrates an approximately 33% improvement in the first run and a 58% improvement in the second run. Additionally, the amount of data scanned was reduced by 90% when using the secondary index.
| Run 1 | Run 2 | Files Read | File Size Read | Rows Scanned | |
|---|---|---|---|---|---|
| Without Secondary index | 32 sec | 14 sec | 5000 | 67 GB | 719 M |
| With Secondary Index | 22 sec | 6 sec | 521 | 7 GB | 75 M |
Read Query used for Benchmarking:
SELECT
ws.ws_order_number,
ws.ws_item_sk,
ws.ws_quantity,
ws.ws_sales_price,
c.c_customer_id,
c.c_first_name,
c.c_last_name,
d.d_date,
wp.wp_web_page_id
FROM
web_sales ws
JOIN
tpcds_hudi_1tb.customer c ON ws.ws_ship_customer_sk = c.c_customer_sk
JOIN
tpcds_hudi_1tb.date_dim d ON ws.ws_ship_date_sk = d.d_date_sk
JOIN
tpcds_hudi_1tb.web_page wp ON ws.ws_web_page_sk = wp.wp_web_page_sk
WHERE
ws.ws_ship_customer_sk = '647632'
ORDER BY
ws.ws_order_number
As shown in the DAG below, there is a significant difference in the amount of data scanned and other metrics (see the highlighted part) for the websales table, both with and without the secondary index.
Spark SQL Stats with Secondary index
Spark SQL Stats without Secondary index
Conclusion
Indexing has been a core component of Apache Hudi since its inception, enabling efficient upserts and deletes at scale. With Hudi 1.0, the introduction of secondary indexing expands these capabilities by allowing queries to efficiently filter and retrieve records based on non-primary key fields, significantly reducing data scans and improving query performance. Looking ahead, secondary indexing in Hudi opens new possibilities for further optimizations, such as accelerating complex joins and MERGE INTO operations.
Additionally, to ensure that index maintenance does not introduce bottlenecks, Hudi’s asynchronous indexing service decouples index updates from ingestion, enabling seamless scaling while keeping indexes timeline-consistent and ACID-compliant. These advancements further solidify Hudi’s role as a high-performance lakehouse platform, making data structures such as secondary indexes more accessible.
FAQ
What is a secondary index in Apache Hudi?
A secondary index, introduced in Hudi 1.0, lets users index columns that are not part of the record key. Hudi stores mappings between secondary key values and record keys in its metadata table, so queries filtering on non-primary-key fields can prune files via data skipping instead of scanning the full table.
How do I create a secondary index in Hudi?
On a table with the record index enabled, run a SQL statement such as CREATE INDEX idx_city ON hudi_table(city). Secondary indexes can also be configured through the Spark DataSource API using hoodie.metadata.index.secondary.enable and hoodie.datasource.write.secondarykey.column.
How much does a secondary index improve query performance?
In a TPCDS 1TB benchmark with an index on the web_sales table, the same join query ran about 33% faster on the first run and 58% faster on the second, while the data scanned dropped by roughly 90%, from 67GB across 5000 files to 7GB across 521 files.
Which query engines support Hudi secondary indexes?
Secondary-index-based pruning is available through Apache Spark today. Other engines such as Trino can query Hudi tables but do not currently apply secondary-index pruning, since Trino dropped Hudi metadata table reads in Trino 419. Reduced data scans particularly benefit cloud query engines like AWS Athena that price by data scanned.
Does maintaining a secondary index slow down ingestion?
It does not have to. Hudi's asynchronous indexing service decouples index building from ingestion by scheduling an indexing action on the transactional timeline, so indexes are built in the background while remaining timeline-consistent and ACID-compliant. Indexes can be added or dropped without downtime.