Migrating from Parquet to Apache Hudi: A Practical GuideJuly 29, 2026 by Sivabalan Narayananmigrationbootstrapapache parquetapache sparkguide
Bringing Vector Search to the Lakehouse with Apache HudiJuly 6, 2026 by Rahil Chertara and Aditya Goenkavectorvector searchairaglakehousedata lakehouseapache sparkarchitecturequerying
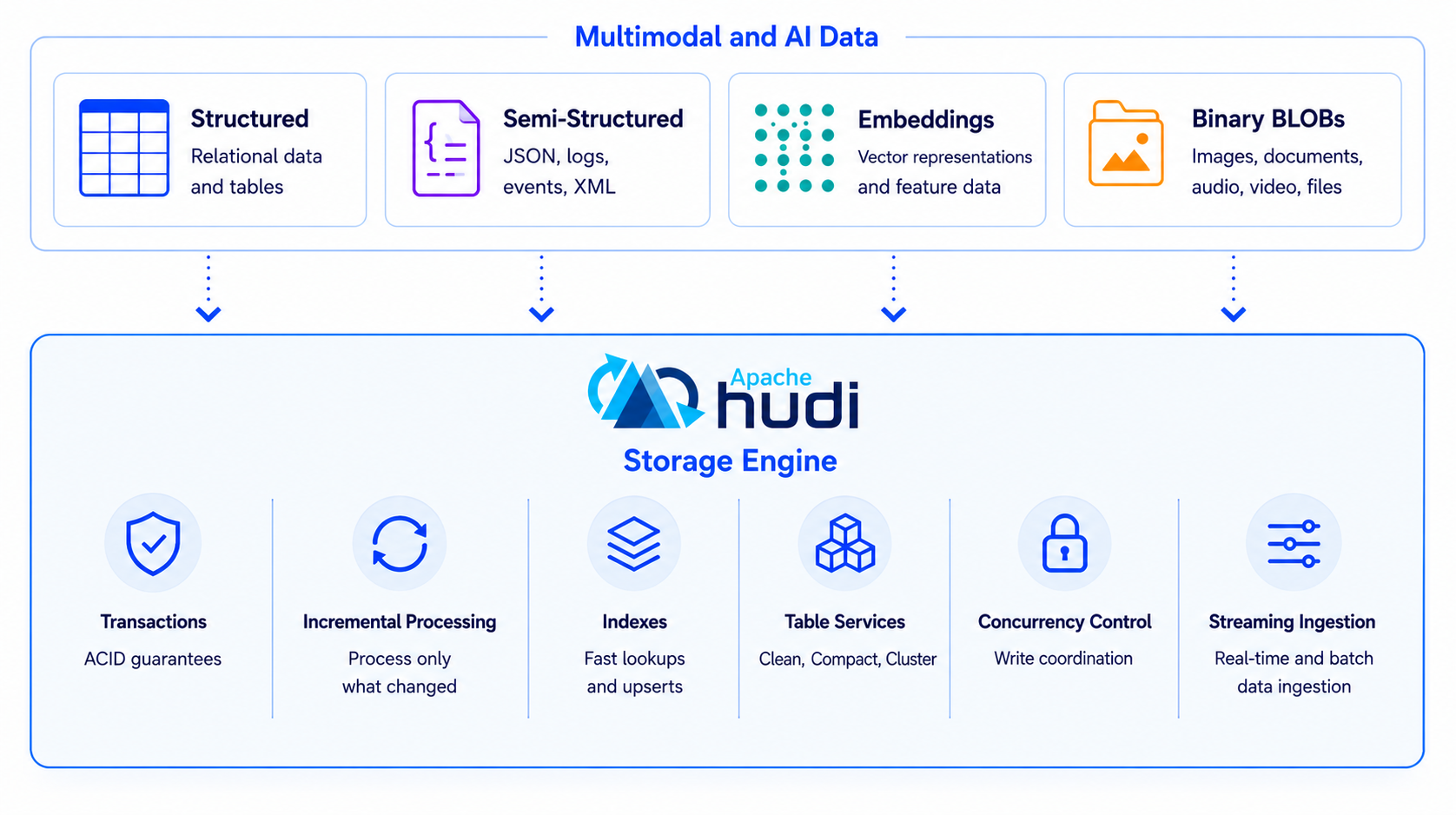
Apache Hudi 1.2: Expanding the Open Lakehouse for AI and Multimodal DataJune 7, 2026 by Rahil Chertara, Sivabalan Narayanan and Ethan Guoreleaseaimultimodalvectorvector searchblobvariantlanceragstreamingconcurrency controllakehouseapache flinkapache spark
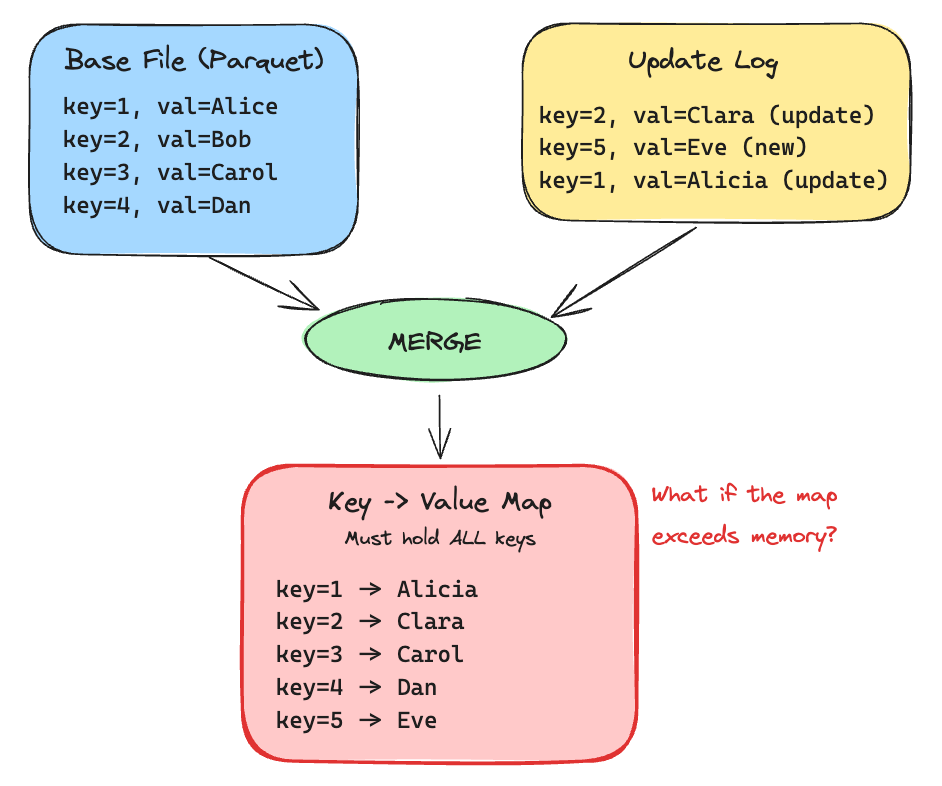
ExternalSpillableMap: Handle Maps Too Big for MemoryJanuary 13, 2026 by Yongkyunperformanceapache spark
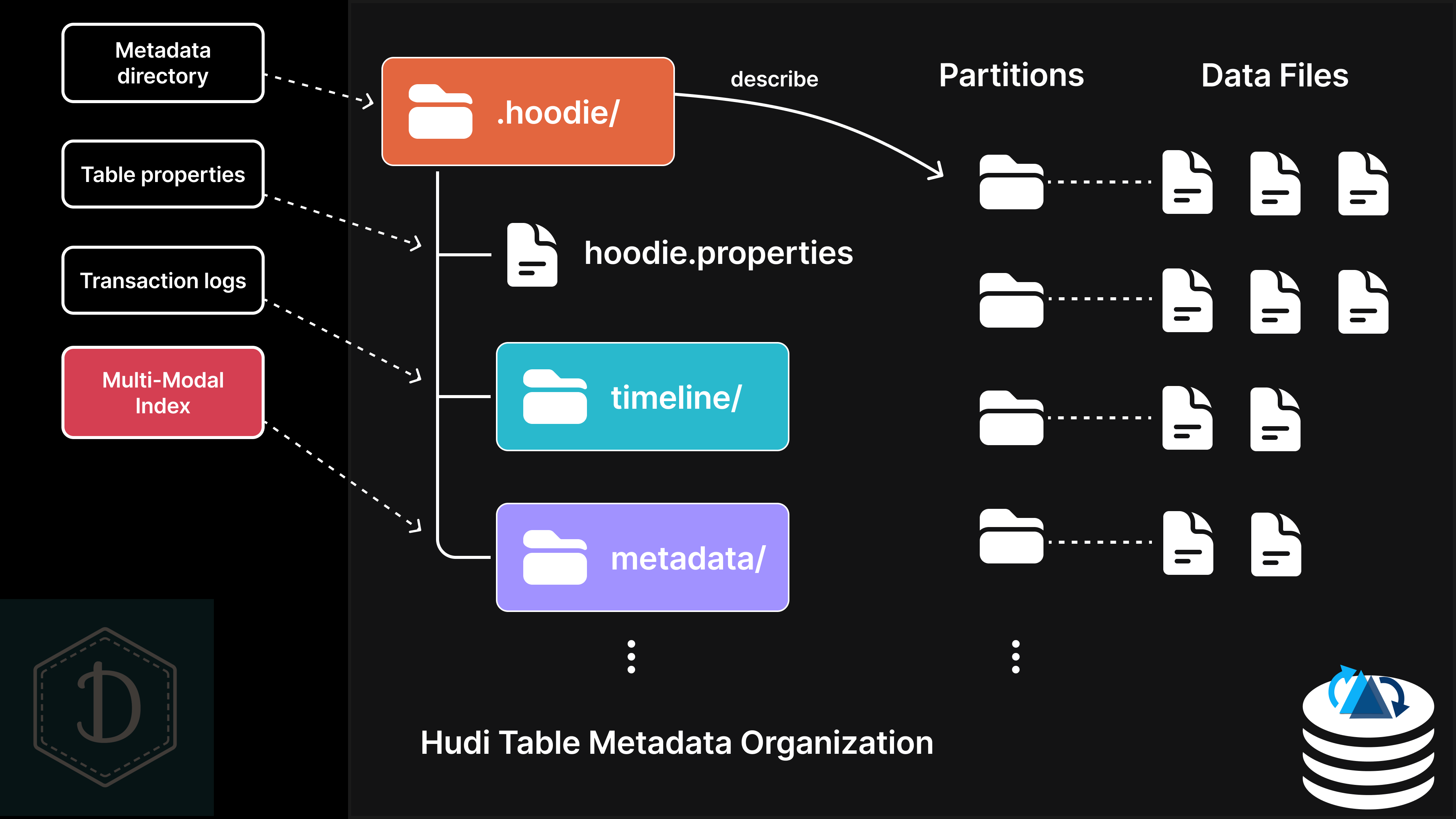
Apache Hudi does XYZ (1/10): File pruning with multi-modal indexJune 16, 2025 by Shiyan Xuapache sparkdata lakehouse
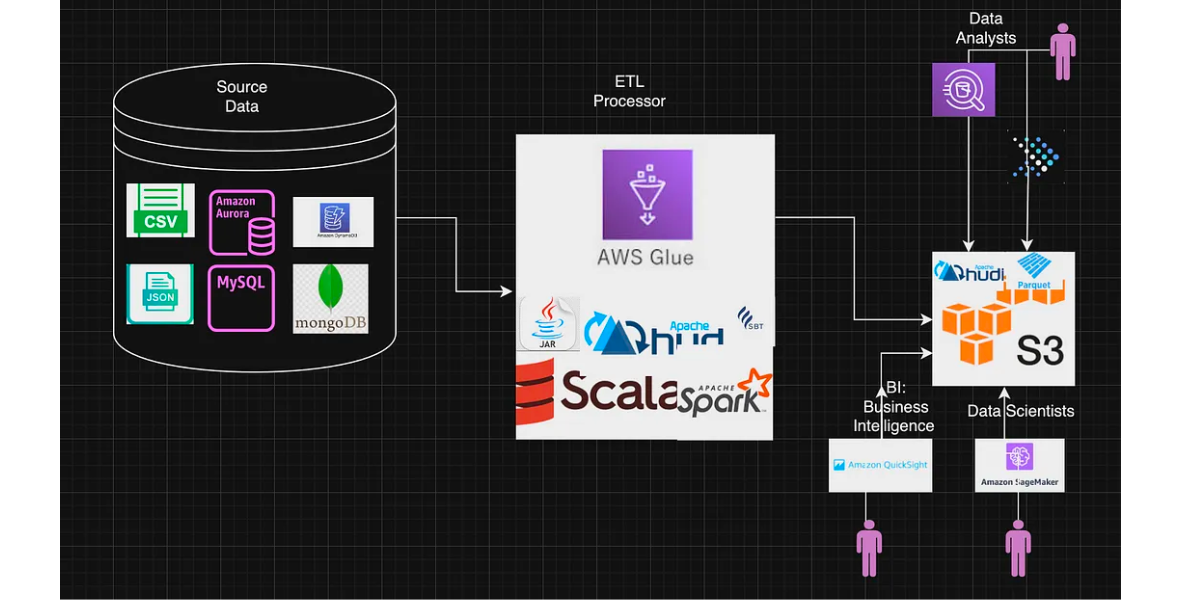
Use open table format libraries on AWS Glue 5.0 for Apache SparkDecember 4, 2024 by Sotaro Hikita and Noritaka Sekiyamaannouncementapache sparktable formataws
Mastering Slowly Changing Dimensions with Apache Hudi & Spark SQLOctober 7, 2024 by Sameer Shaikscdapache spark
Apache Hudi, Spark and Minio: Hands-on Lab in DockerOctober 2, 2024 by Sanjeet Shuklaapache sparkminiodocker
Developer Guide: How to Submit Hudi PySpark(Python) Jobs to EMR Serverless (7.1.0) with AWS Glue Hive MetaStoreSeptember 4, 2024 by Soumil Shahapache sparkpythonaws