Stateless Global Upserts for Flink Streaming in Apache Hudi 1.2.0


Motivation
Apache Hudi 1.2.0 introduces Record Level Index (RLI) support for Flink writers, bringing scalable global upserts to streaming ingestion for the first time.
Until now, Flink users had to choose between two indexing options. The bucket index is fast and scalable, but only within a partition. The flink_state index can perform global lookups, but its index lives entirely inside Flink state, growing with table cardinality and becoming increasingly expensive to checkpoint, recover, and migrate.
At large scale, the problem is not lookup correctness. It is operational sustainability. As tables grow to hundreds of millions or billions of records, index state can reach hundreds of gigabytes, turning savepoints, upgrades, and failover recovery into major operational events.
Spark users have long addressed this problem with Hudi's Record Level Index (RLI), which stores record locations in the Metadata Table (MDT). With Hudi 1.2.0, Flink gains the same capability: a global index that is part of the table itself rather than part of a single streaming job.
A concrete example: the orders table
Take a typical e-commerce orders table:
-
Partition column: datestr (order creation date)
-
Record key: order_id
Inserts naturally land in the latest partition. But updates like status changes, fulfillment events, returns usually arrive without the original datestr. The upstream system knows the order_id changed; it doesn't always know which day's partition that order originally lived in.
Without a global index, the writer has two bad choices:
- Bucket index: assume the update belongs to today's partition and write a duplicate. The original row in the older partition is now stale, and the table has two rows for the same order_id.
- flink_state index: works correctly, but every order_id the table has ever seen must live in Flink state. For a table with hundreds of millions of historical orders, this is a multi-hundred-GB state blob attached to the Flink job, and rebuilding it on recovery (or on migrating to a new pipeline) takes hours.
This is exactly the gap that Record Level Index (RLI) closes. Instead of storing record locations inside a single Flink job, RLI stores the global key-to-location mapping in Hudi's Metadata Table. Any writer can resolve an order_id to its current location regardless of partition, while keeping the index independent of Flink state.
Flink RLI
RLI stores the key-to-file-group mapping in the Hudi metadata table (MDT), as a dedicated record_index partition. The mapping is:
- Global: partition-agnostic; an update for any order_id resolves to the correct file group regardless of partition. - Engine-agnostic: Spark writes and reads RLI today; Flink now does too. A table indexed by Spark RLI can be picked up by a Flink streaming job, and vice versa, with no rebuild. - Decoupled from the writer's lifecycle: the index is part of the table, not part of the Flink job's keyed state. New pipelines can attach immediately; savepoints stay small; recovery doesn't replay the index. - Shardable: RLI is partitioned into N file groups (you choose), each holding a slice of the key space. Lookups and writes parallelize naturally.
High level design
Incoming records are grouped by the same record-key layout the metadata table uses, so each Flink task only needs the relevant RLI shards. (A “shard” here is one RLI file group in the metadata table; the number of shards equals the configured RLI file-group count.) Flink then looks up record locations in mini-batches, uses a small local cache for records still in flight, and sends each record to the right write target (Figure 1).
After routing, the data path and index path move together. The writer persists the data change and sends a compact record-location update to the metadata table. Hudi then commits the data and index results under the same instant, so the table and its index advance as one consistent unit.
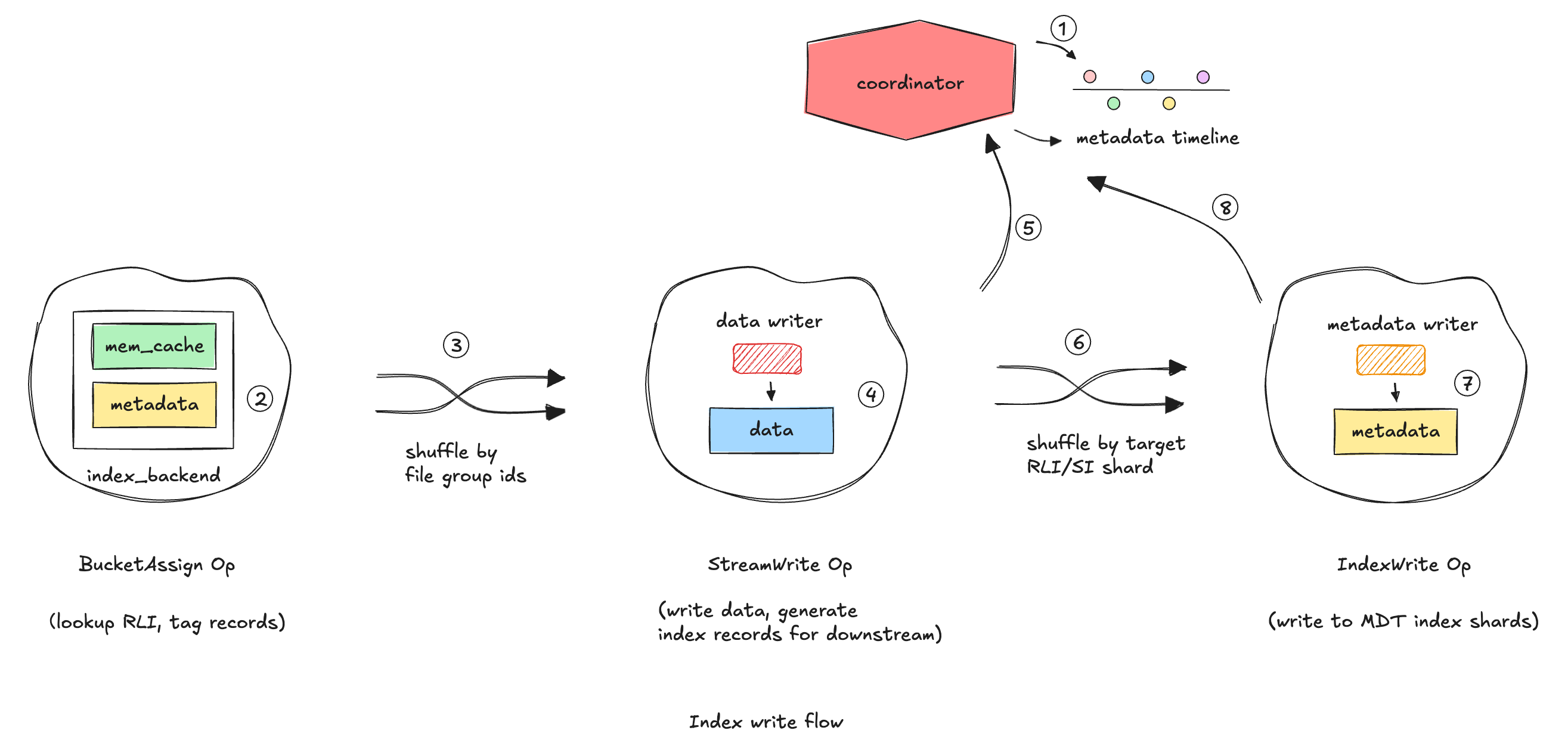
Detailed Design
How Flink Finds Existing Records
When global RLI is enabled, Flink switches from a per-task state lookup to a mini-batched metadata-table lookup. Records are routed to the task responsible for the relevant record-index shard, so each task reads only the slice of the metadata table it needs. This keeps lookup work local and avoids asking every task to scan every shard (Figure 2).
During streaming upserts and deletes, Flink buffers a small batch of records before consulting RLI. It first checks the local in-flight cache, then asks the metadata table for any missing record locations. Once each record’s previous location is known, the normal assignment logic can decide whether to update an existing file or write the record as a new insert.
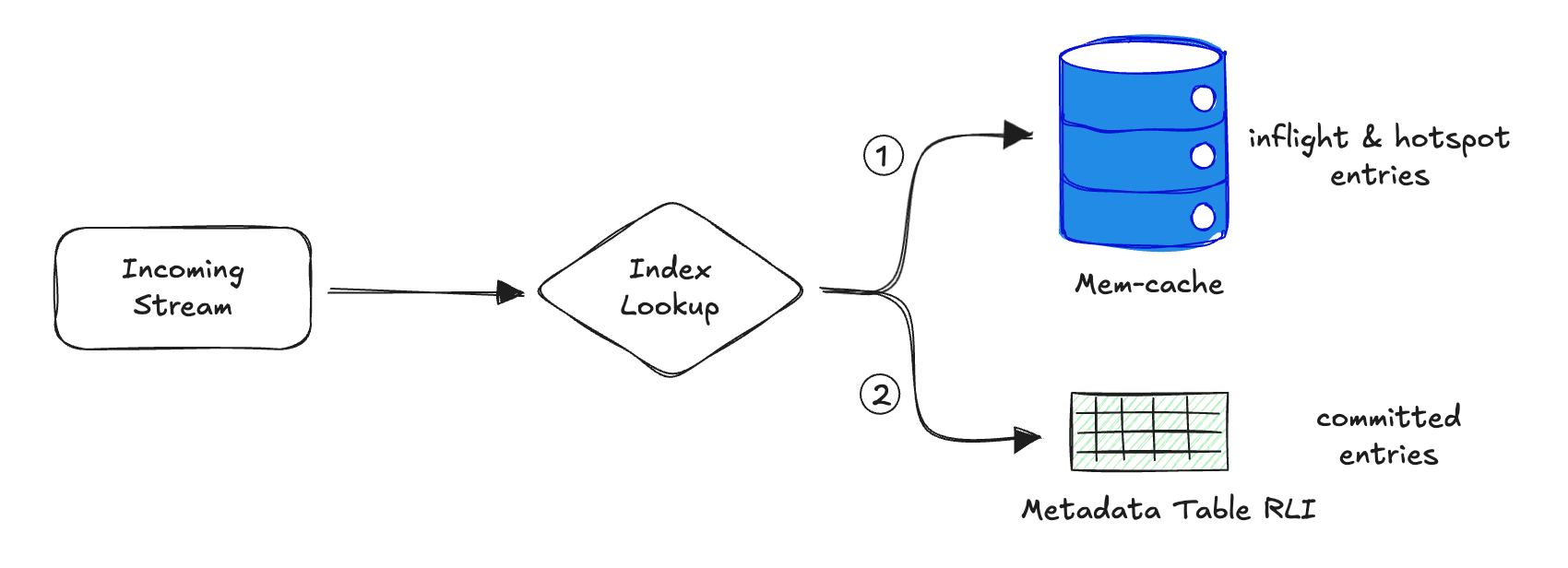
Why a Small Local Cache Still Exists
.Flink RLI is fundamentally table-backed, but a small checkpoint-scoped cache is still required to bridge the gap between in-flight updates and committed metadata. It remembers recent record-to-location changes that have already passed through the Flink pipeline but may not yet be visible in the committed metadata table. That matters when the same record appears more than once before the corresponding Hudi instant finishes committing; the later record still needs to route to the latest in-flight location (Figure 3).
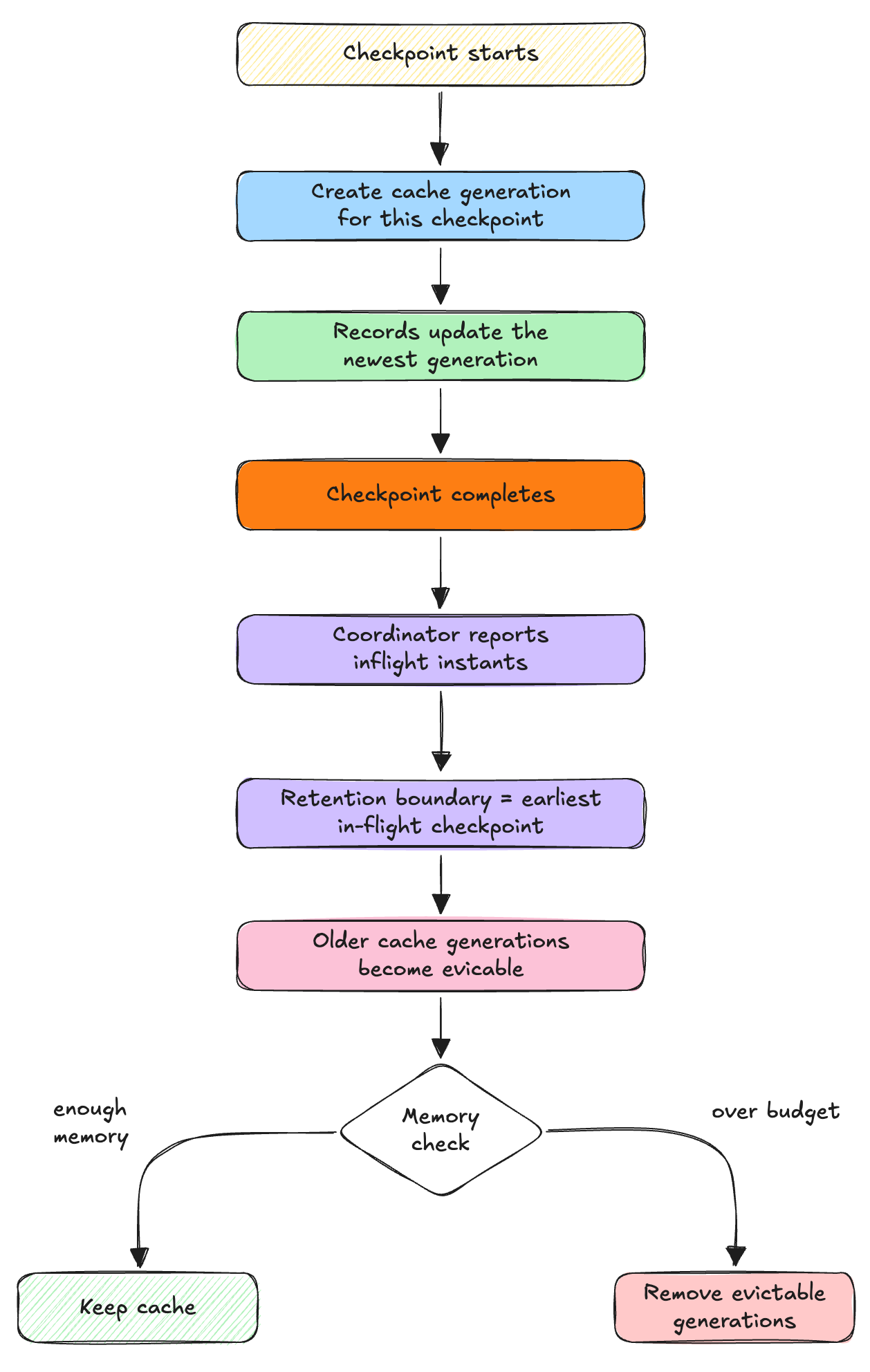
Each checkpoint produces a new cache generation — a snapshot of the record-to-location changes seen during that checkpoint. On checkpoint completion, Flink learns which commits are still in flight, keeps the cache generations that may still be needed, and refreshes its view of the metadata table. Older generations can then be cleaned up when memory pressure requires it. The result is a small correctness buffer for the commit gap plus a fresh table-backed read view after commits land.
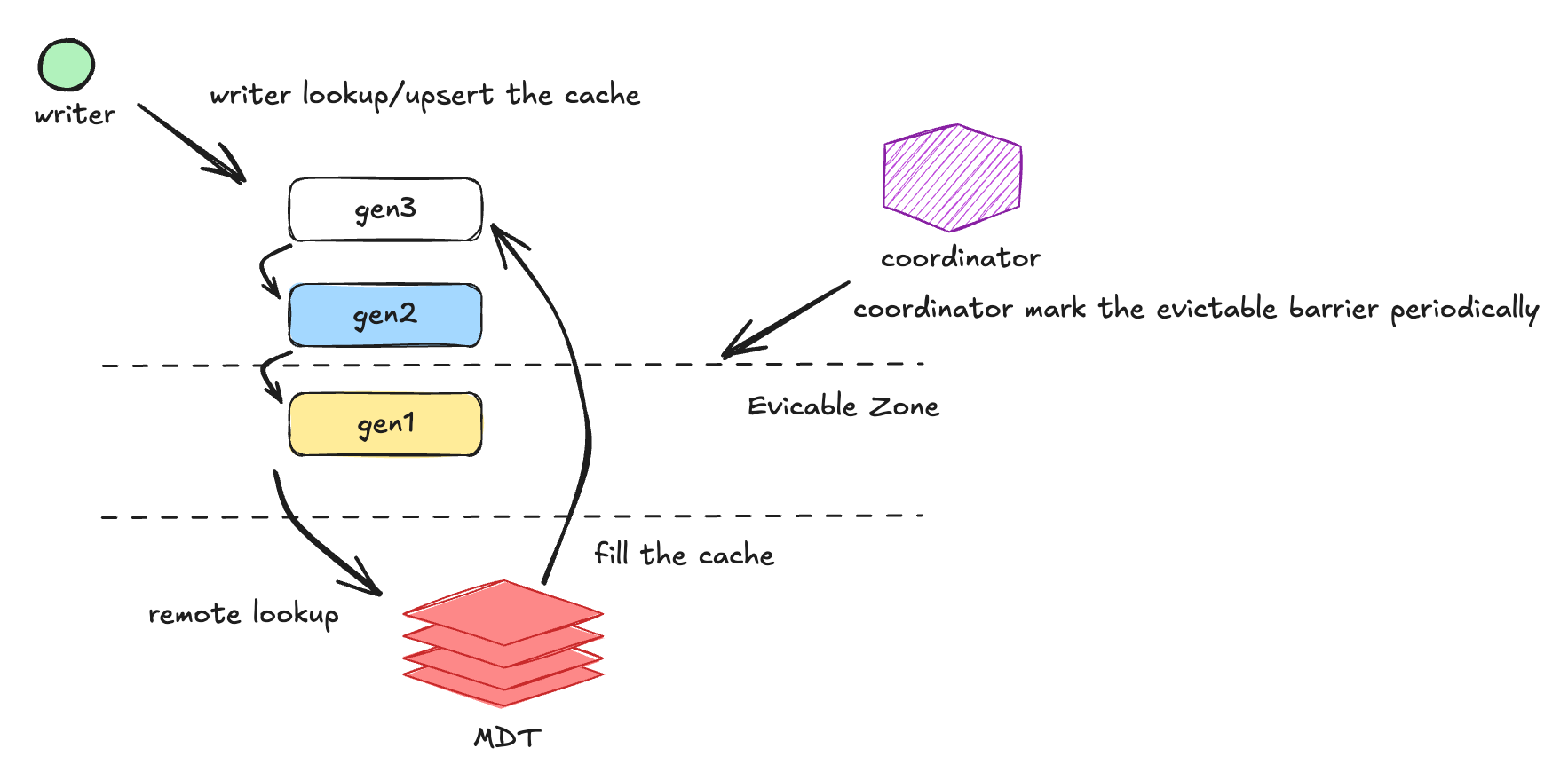
Cache eviction is intentionally lazy. A completed checkpoint does not immediately delete cache data. Instead, Flink asks the operator coordinator — Flink’s write coordinator on the JobManager, which drives Hudi commits — which Hudi instants are still in flight, and uses the earliest in-flight checkpoint as the retention boundary. Cache generations older than that boundary become evictable. They are actually closed and removed only when a memory check decides the cache needs space for a new checkpoint generation or for continued updates. This keeps recovery-safe entries around while still bounding memory usage (Figure 4).
Keeping the Index Consistent During Failures
The tricky window is between a successful Flink checkpoint and a completed Hudi instant. A checkpoint can succeed while the asynchronous acknowledgment or commit step is delayed, lost, or interrupted by task/job failover. During that gap, data may be valid from Flink’s point of view, but the corresponding MDT index commit may still be in flight.
The design handles this through checkpoint-aware recovery. Flink persists enough write metadata to retry commits that completed in Flink but did not finish in Hudi. After task failover or job restart, Hudi can recommit those pending instants and refresh the table state before new records continue reading from RLI.
Flink also flushes pending mini-batches before checkpoint barriers, so a data change and its matching index update stay within the same checkpoint boundary.
How Index Updates Are Written
Index updates are written in batches rather than one record at a time. Before each checkpoint, or when the buffer is full, Flink deduplicates updates by record key so only the latest location is kept. It then writes those updates to the metadata table and reports the result to the same coordinator that commits the data files. This keeps the data commit and index commit aligned.
Routing: Keeping Reads and Writes on the Same Shard
Global RLI uses the same record-key routing on both sides of the pipeline: first when records are looked up, and again when index updates are written. The task that owns a slice of the global record index also receives the matching updates for that slice.
Every record key maps deterministically to an RLI shard:
s = h(k) mod N_RLI
The same shard assignment is reused for both lookups and index updates, ensuring that reads and writes for a given key are handled by the same slice of the index.
In other words, the record key first chooses a stable RLI shard. That shard is then mapped to the bucket-assign task for lookup and to the index-writer task for metadata updates. This keeps the read side and write side aligned without requiring every task to touch every shard.
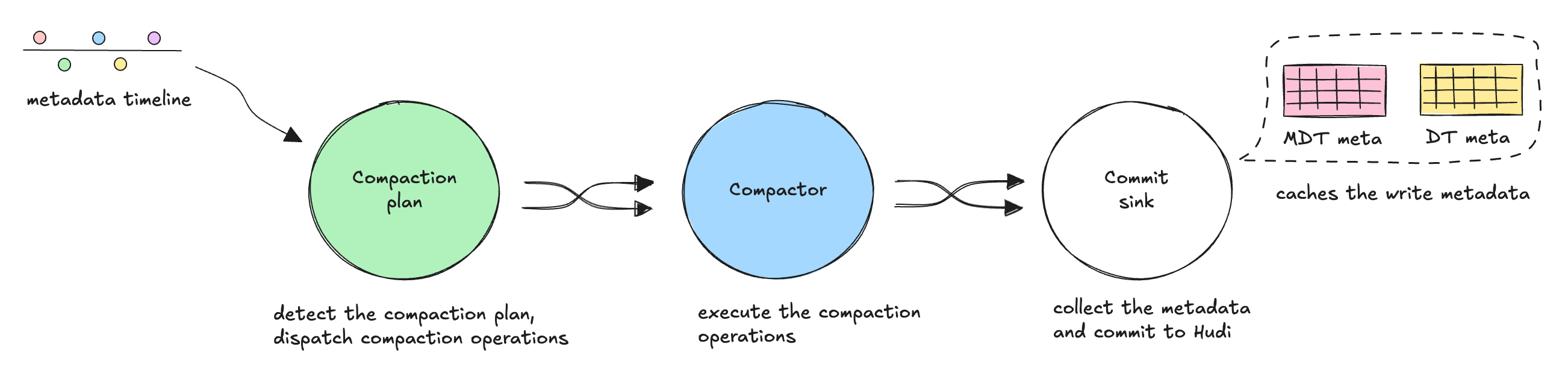
Compaction
RLI adds write traffic to the metadata table, so metadata compaction becomes an important operational concern. (The benchmark uses a Merge-on-Read table, so both the data table and the always-MOR metadata table run compaction.) The RFC keeps metadata compaction asynchronous so ingestion can continue while metadata files are merged in the background. As the Perf and Benchmarking section below shows, data-table compaction stays moderate while metadata-table compaction produces the largest tail latency — the main metric to watch (Figure 5).
Performance Benchmarking
Because RLI maintenance sits directly on the write path, the key question is whether a metadata-table-backed global index can sustain production streaming workloads without becoming a bottleneck.
Our evaluation focused on three questions:
- Can Flink RLI sustain high-throughput ingestion against large existing tables?
- Can checkpoint completion remain comfortably within streaming SLAs?
- Does maintaining the metadata-table index materially impact write throughput or operational stability?
The goal was not to compare RLI against bucket index. Bucket index is a partition-local solution and will always have lower lookup costs. Instead, the goal was to validate that global indexing on Flink is operationally viable at production scale.
Benchmark Environment
Both benchmark runs used the same baseline environment:
- ~1 billion existing records
- ~1 TB table size on disk
- 100 date partitions
- 100 RLI shards
- Flink standalone cluster with 4 workers
- 64 vCPU / 256 GB RAM per worker
We evaluated two ingestion profiles:
| Run | Ingestion Rate | Incremental Records | Checkpoint Interval |
|---|---|---|---|
| Baseline | 20K records/sec | 50M | 5 minutes |
| Aggressive | 50K records/sec | 100M | 3 minutes |
Results
The aggressive workload successfully sustained 50,000 records per second against a table containing approximately 1 billion existing records while maintaining a 3-minute checkpoint SLA.
Despite the increased ingestion pressure, checkpoints remained comfortably within budget, averaging 24.1 seconds end-to-end. The job completed the full 100 million-record workload without instability, source backpressure remained manageable, and ingestion throughput stayed near the target rate throughout the run.
| Metric | Average | P99 |
|---|---|---|
| Checkpoint SLA | 180s | 180s |
| Checkpoint E2E | 24.1s | — |
| Minibatch Lookup Latency | 3.35s | 8.94s |
| Data Flush Latency | 0.29s | 1.43s |
| Index Flush Latency | 2.33s | 4.84s |
Lookup latency increased relative to the baseline run due to higher minibatch fan-out and reduced cache locality. However, both data writes and index maintenance remained well below checkpoint deadlines, demonstrating that MDT-backed global indexing can operate within typical streaming SLAs at this scale.
Note: The benchmark intentionally stresses the worst-case scenario. Many real-world CDC workloads exhibit strong temporal locality, causing repeated updates to a relatively small working set of keys. In those environments, cache hit rates and effective lookup latency are expected to improve further.
Takeaways from the benchmarks
The benchmark demonstrates that MDT-backed global indexing is operationally viable for large-scale Flink ingestion. Even under the more aggressive workload, checkpoint completion remained comfortably within the configured SLA, while lookup and index maintenance costs stayed bounded.
More importantly, index scalability is no longer tied to Flink state size. The global record index lives in the table itself, allowing new jobs to attach immediately, minimizing savepoint overhead, and enabling Spark and Flink writers to share the same index infrastructure.
Conclusion
Flink RLI closes one of the longest-standing gaps between Spark and Flink in Hudi's indexing architecture. By moving the global record index into the Metadata Table, Hudi decouples index scalability from Flink state while preserving the correctness guarantees required for global upserts.
For teams already using Spark RLI, Flink can now operate on the same indexed tables without rebuilding state. For teams relying on flink_state, RLI provides a path toward smaller savepoints, faster recovery, and a more operationally sustainable architecture.
With Hudi 1.2.0, stateless global upserts are now a viable and robust capability for Flink streaming workloads.