How FreeWheel Uses Apache Hudi to Power Its Data Lakehouse

This post summarizes a FreeWheel talk from the Apache Hudi Community Sync. Watch the recording on YouTube.
FreeWheel, a division of Comcast, provides advanced video advertising solutions across TV and digital platforms. As the business scaled, FreeWheel faced growing challenges maintaining consistency, freshness, and operational efficiency in its data systems. To address these challenges, the team began transitioning from a legacy Lambda architecture to a modern, Apache Hudi-powered lakehouse approach.
Their original stack, shown below, used multiple systems like Presto, ClickHouse, and Druid to serve analytical and real-time use cases. However, the architecture had some limitations:
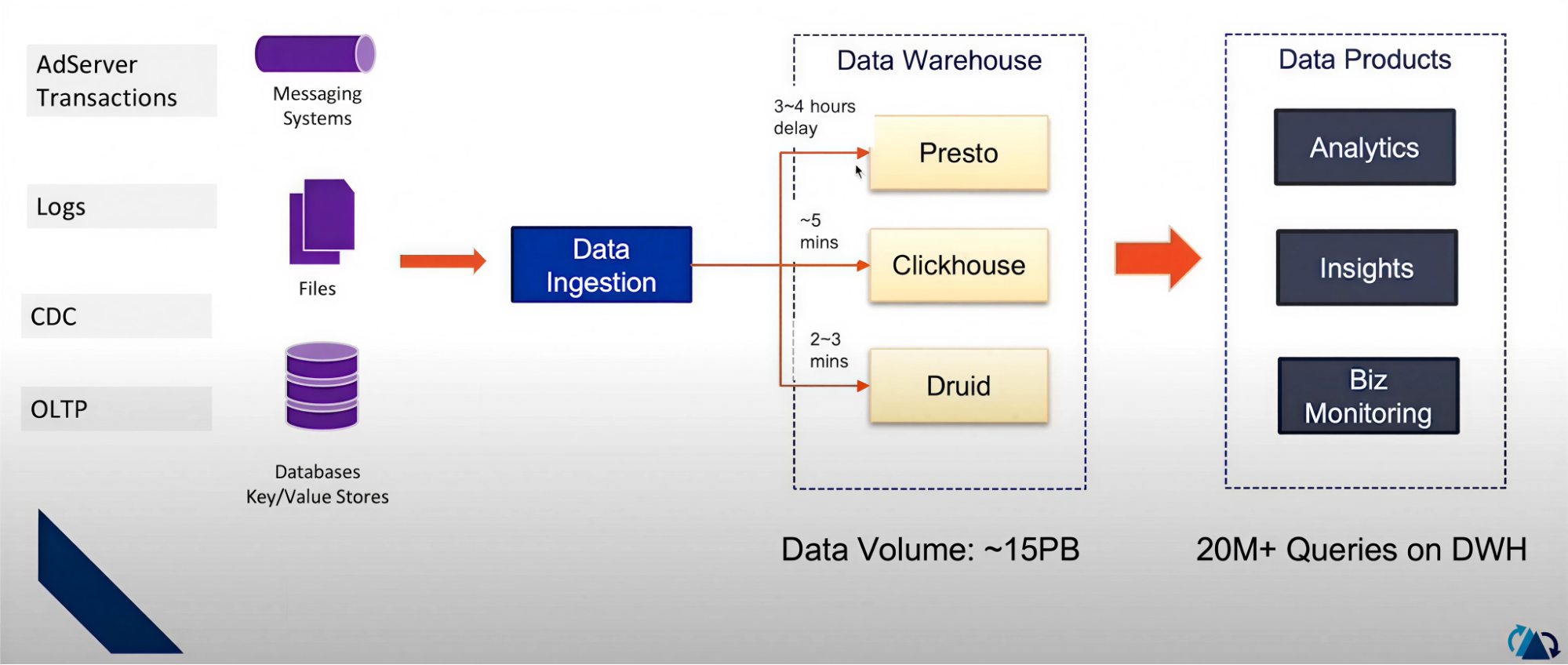
Data freshness issues
- Presto tables had a 3–4 hour delay, which was too slow for operational use cases.
- Only ClickHouse and Druid offered near‑real‑time access (~5 minutes) but added complexity.
Complex ingestion
- Data came from logs, CDC streams, files, and databases.
- Each system had its own ingestion pipeline and refresh logic.
Query performance bottlenecks
- With ~15 PB of data and 20M+ queries/day, scaling across three engines was costly and hard to operate.
Use Case 1: Lambda Architecture and Its Drawbacks
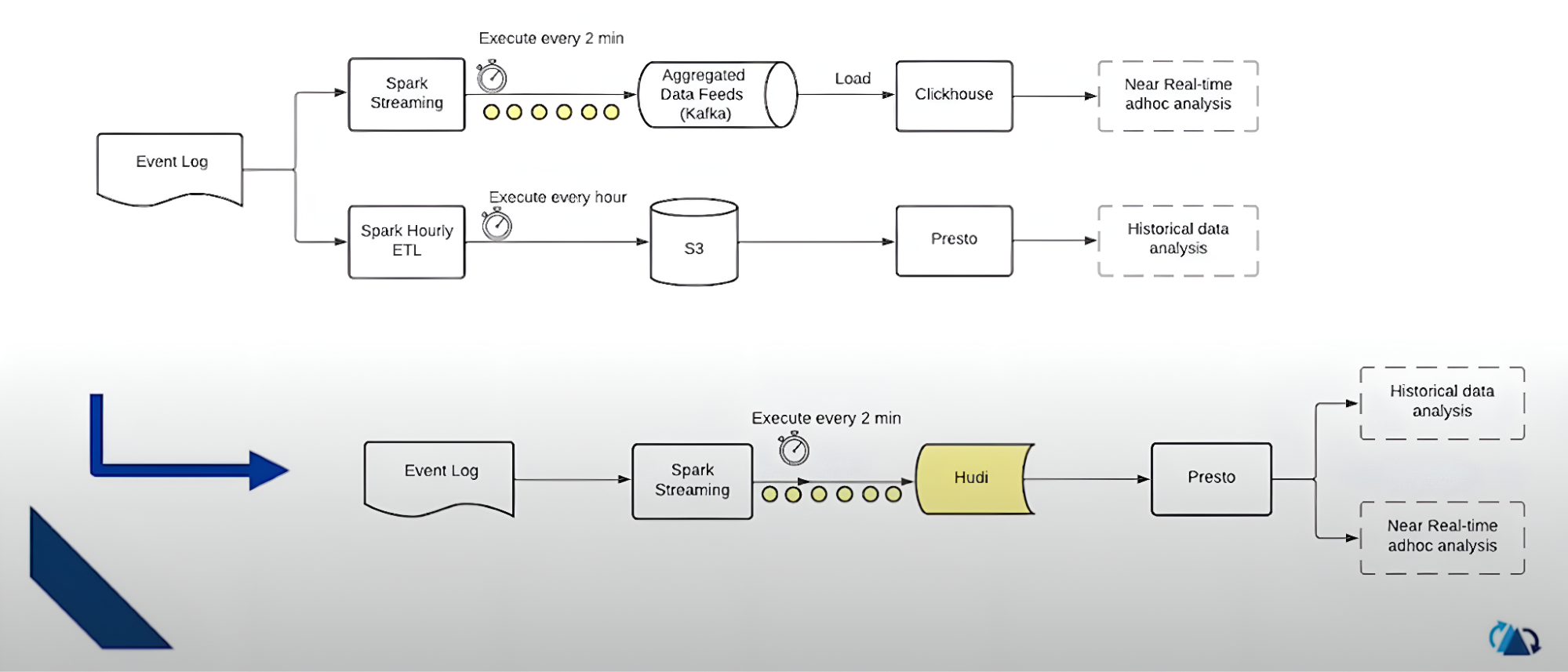
FreeWheel initially followed a traditional Lambda architecture, which separated the processing of batch and real‑time data. This approach created several problems: it required duplicate pipelines for batch and real‑time processing (leading to inefficient engineering workflows), and it struggled to scale ClickHouse for large aggregates.
By consolidating on Hudi as the table format for both streaming and historical data, FreeWheel unified the storage layer and eliminated duplicate pipelines. Hudi’s upserts by key and incremental processing make it possible to serve near–real‑time analytics. The result is simpler operations, consistent logic, and a platform that scales with data volume and query complexity.
Use Case 2: Real-Time Inventory Management
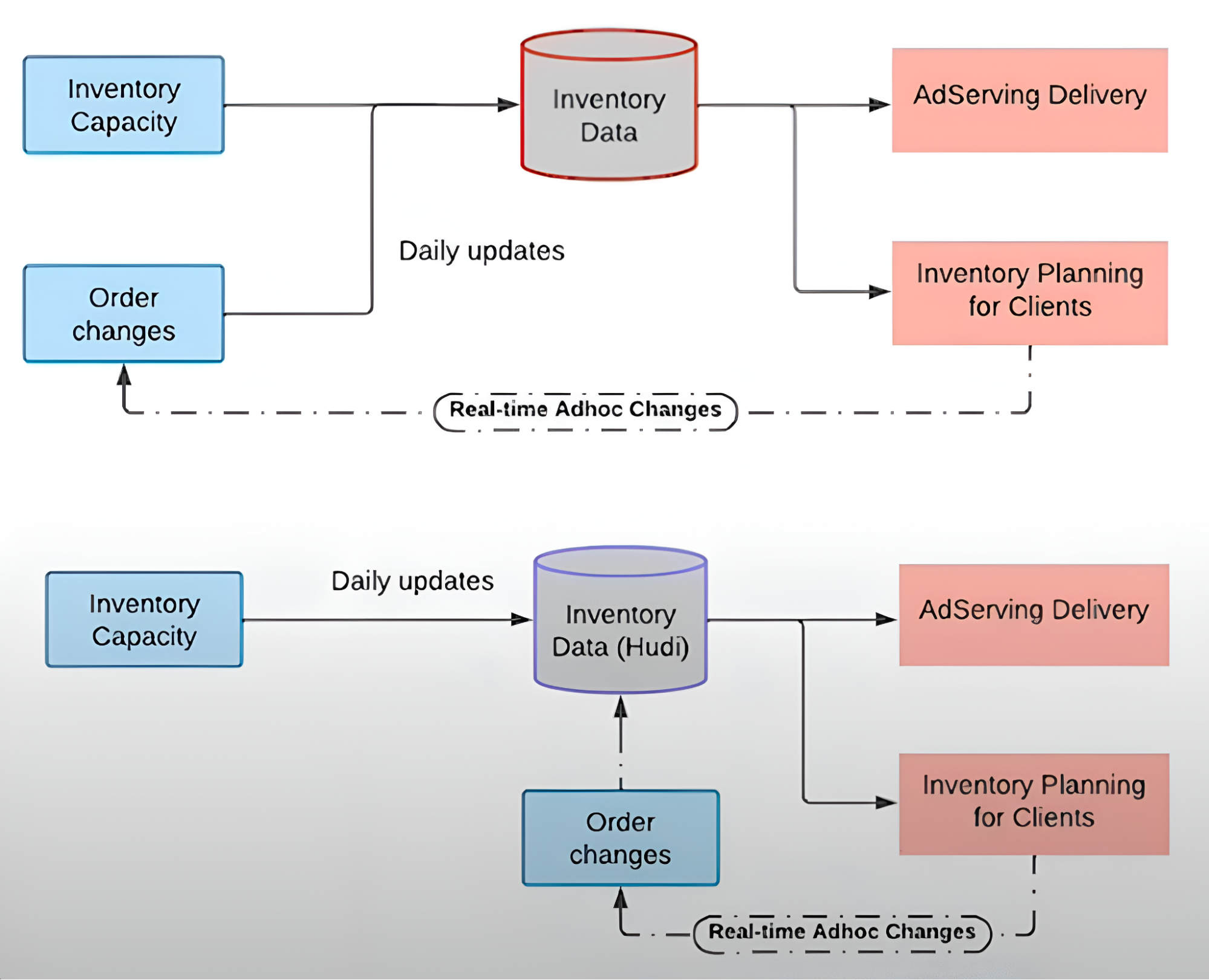
Historically, daily ad inventory updates were a significant challenge. This method led to low forecasting accuracy and frequent delivery-performance mismatches.
By modernizing the platform with Hudi, FreeWheel updates inventory within minutes. Order changes are applied as upserts to Hudi tables and become queryable shortly thereafter, dramatically improving forecast accuracy and reducing delivery‑vs‑forecast mismatches.
Use Case 3: Scalable Audience Data Processing
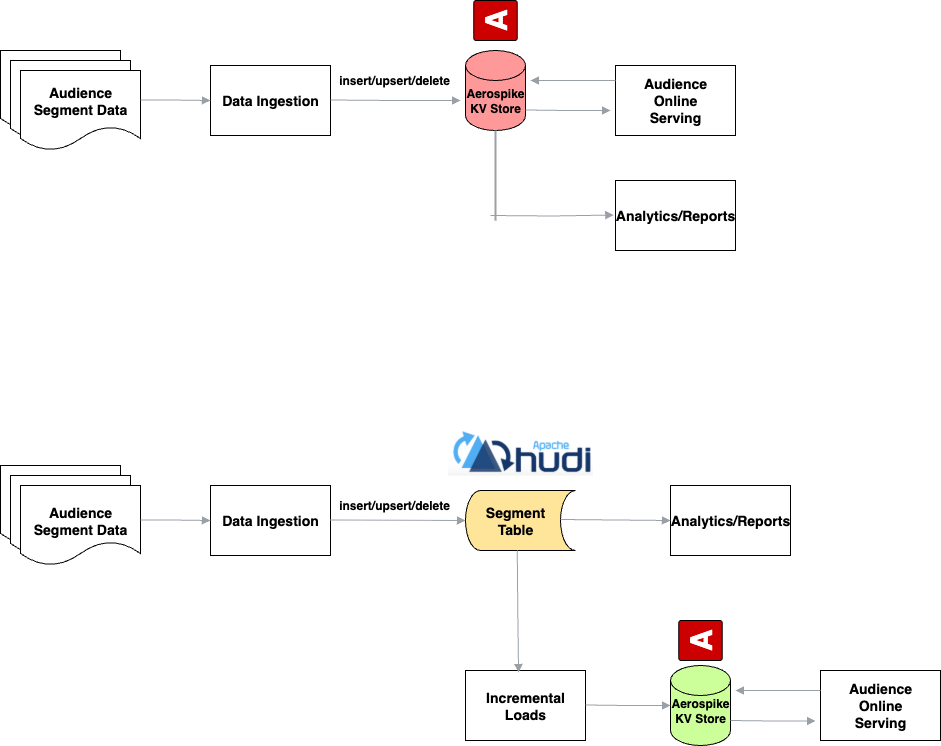
FreeWheel uses Aerospike to ingest audience segments for its online services, which involves handling high‑frequency, real‑time data. However, this setup brought a few key challenges—chiefly, the need for analytical insights on top of real‑time data and the need to efficiently manage bulk loads alongside frequent updates.
To address these challenges, FreeWheel introduced Hudi into the data pipeline. Hudi maintains a snapshot table for all audience data, enabling more flexible and efficient data management. It supports bulk inserts, upserts, and change data capture (CDC), enabling smoother handling of updates and large‑scale data loads. Using CDC, large batches of audience updates are applied incrementally to the snapshot. With Hudi in place, the back‑end analytics system became much stronger, while the responsiveness of the online systems was preserved. This setup also improved the stability of the online targeting system, as heavy analytical workloads were moved off the key‑value store, reducing pressure on Aerospike and enhancing overall performance.
Hudi in practice 1: Billion‑scale updates for audience‑segment ingestion
Use case overview
This implementation showcases how a large‑scale platform ingests and updates audience‑segmentation data at the billion‑record scale using Hudi tables. The architecture efficiently handles high‑frequency updates across more than 63,000 partitions and a table over 600 TB, with performance optimizations at both the data and infrastructure levels.
Key architecture and design principles
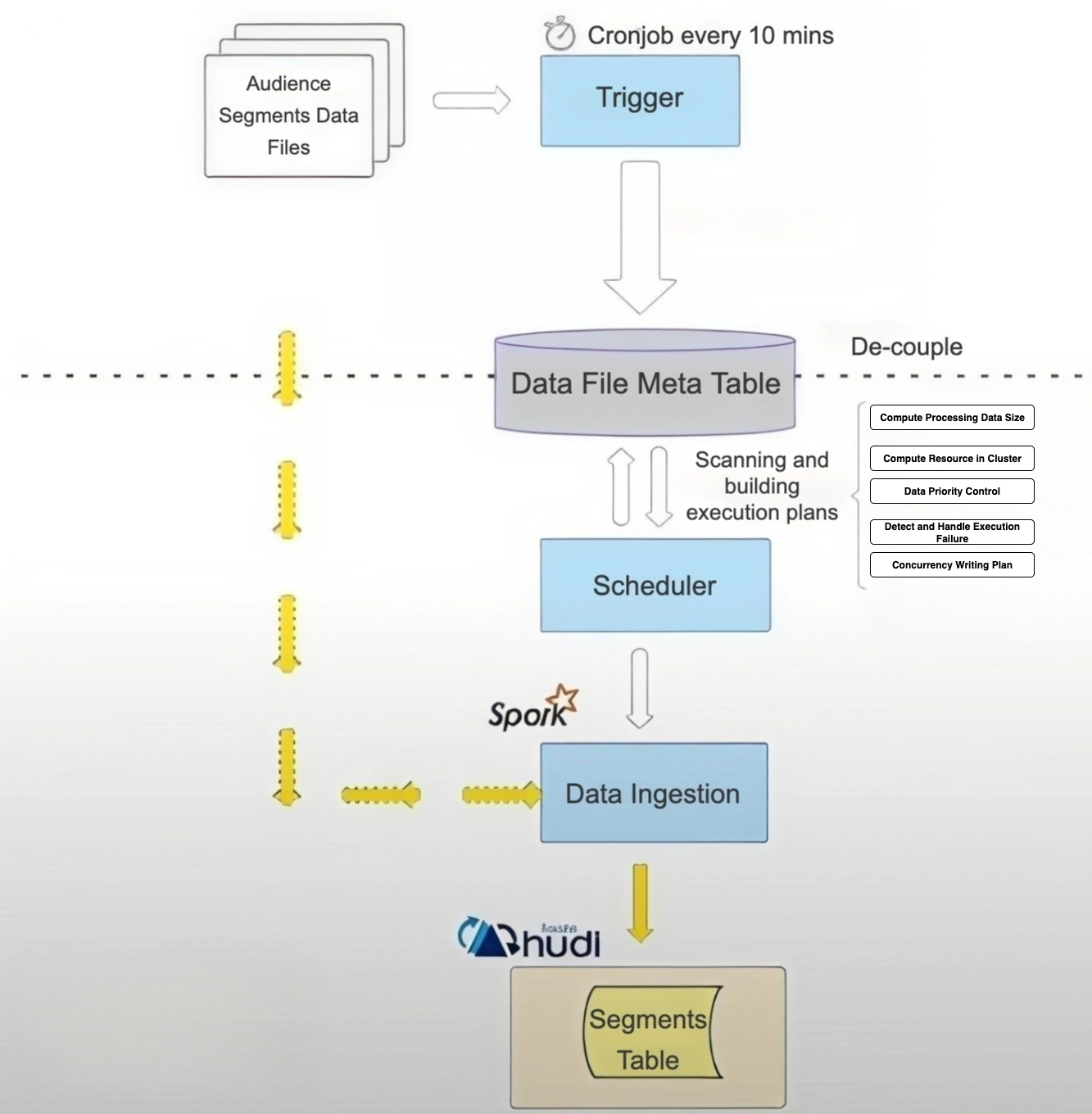
Partitioning and orchestration
FreeWheel uses the audience‑segment ID as the partition key. Each partition can be processed independently, allowing many Spark jobs to run in parallel. Each job upserts data to the Hudi lakehouse table.
A central scheduler allocates work based on input size, priority, and write concurrency limits. This enables dynamic scaling across more than 63,000 partitions, where per-partition input sizes range from 1 million to 100 billion records.
Decoupled ingestion pipeline
- Scheduler: allocates resources based on input size and supports job priority, multi-writer concurrency control, and concurrency planning.
- Ingestion job: Spark jobs process data and write it to the Hudi segment table in the lakehouse.
Challenges of input data at scale
- Table size: over 600 TB.
- Partition count: 63,000 audience‑segment partitions.
- Data skew: massive variation in partition sizes, ranging from 1 million to 100 billion records.
Metrics and performance insights
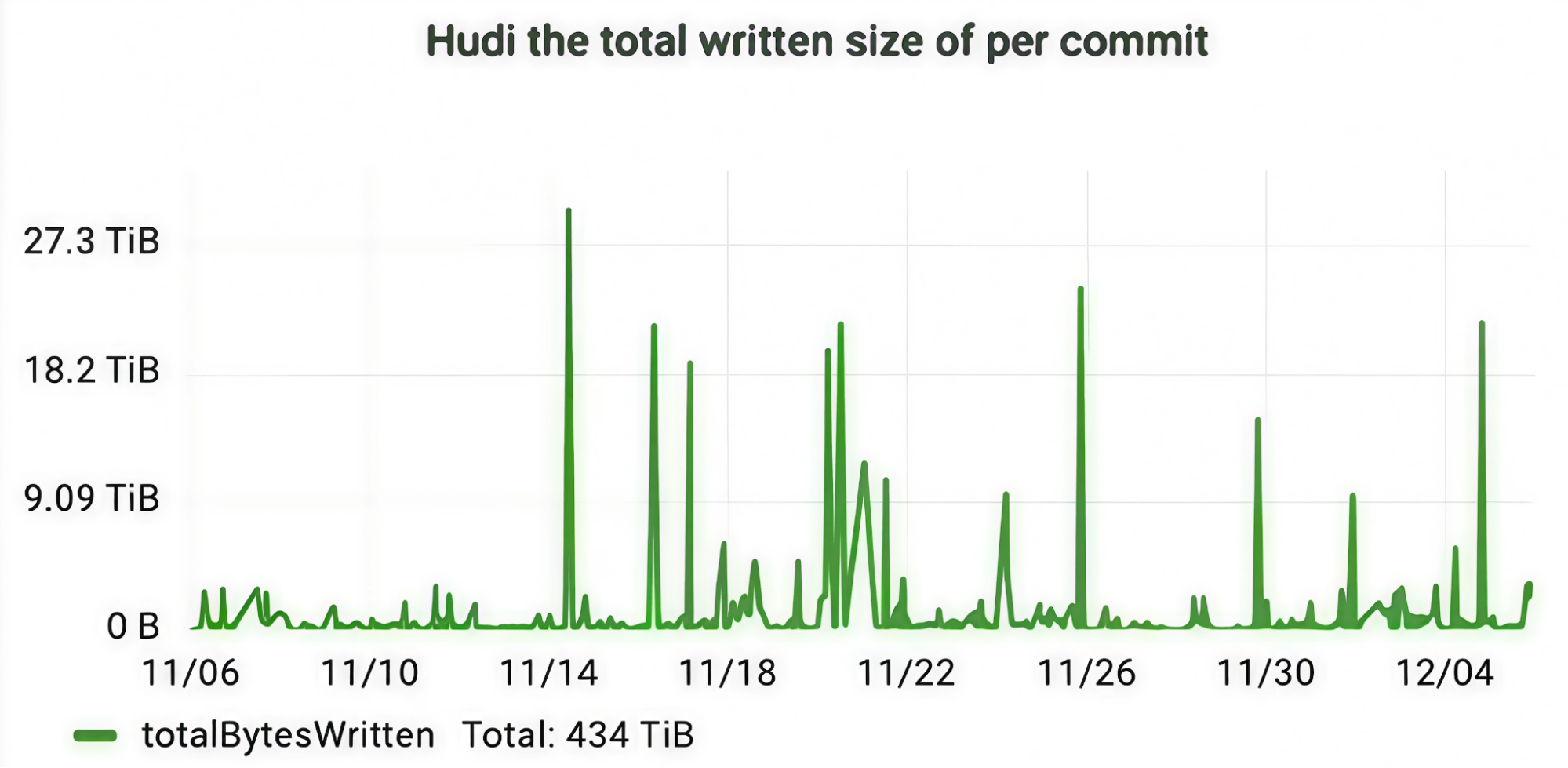
- Cost optimization
- Unit cost on AWS: ~$0.10 per million records updated.
- Throughput: the pipeline supports up to 12 million upserts per second.
Operational optimizations
- Handle S3 throttling by increasing partition parallelism. Hash partition prefixes and coordinate with AWS to raise per‑bucket request caps and remove I/O bottlenecks.
- Balance SLA and cost with adaptive resource provisioning through the scheduler; choose resources based on input size to keep jobs stable while controlling spend.
- Deduplicate before commit: group by record key, order by event timestamp, and write only the latest value to reduce churn and speed up writes.
Hudi in practice 2: Real‑time aggregated ingestion using Spark Streaming + clustering
Pipeline overview
This implementation showcases an efficient pipeline where Spark Streaming ingests aggregated data into a Hudi lakehouse using the bulk_insert operation, followed by asynchronous clustering.
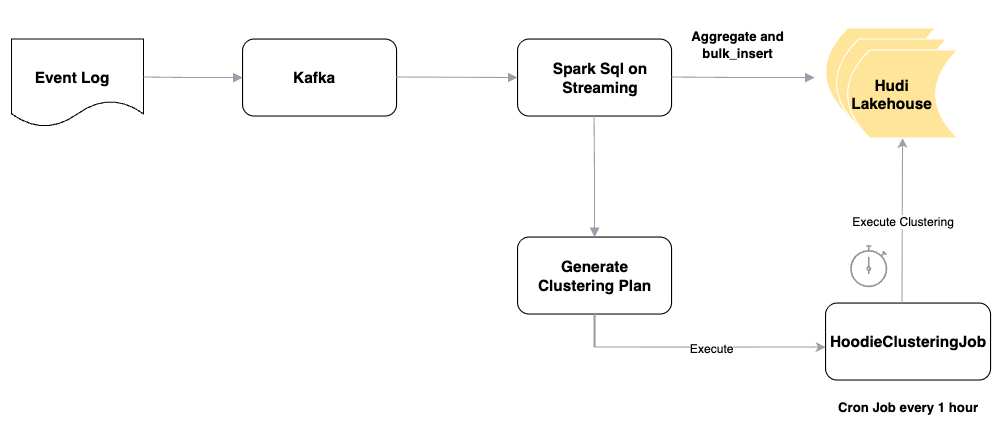
Data ingestion flow
- Kafka: raw events are streamed into Kafka.
- Spark SQL on Streaming: consumes Kafka messages and performs near‑real‑time aggregations.
- bulk_insert into Hudi lakehouse: aggregated data is appended using bulk_insert.
- Clustering plan generation: clustering plans are created asynchronously.
- HoodieClusteringJob: a cron job runs hourly to execute clustering and consolidate small files.
Results at a glance
- Massive file reduction: clustering reduced total file count by nearly 90%, minimizing small‑file pressure and improving metadata performance.
- Write throughput boost: increased by about 114% due to optimized file layout.
- Faster queries: Presto query performance improved significantly after clustering.
However, Spark Streaming is a macro‑batch system, typically executing every one or two minutes. As a result, it does not trigger clustering jobs immediately but instead generates clustering plans for later execution. In production, clustering jobs are scheduled to run hourly and apply only to stable partitions, ensuring compaction and file optimization without impacting real‑time ingestion.
Conclusion
FreeWheel’s journey with Hudi transformed its data architecture—offering unified access, real‑time freshness, and scalable operations. The team credits Hudi’s community and feature set as key to its success.
“We’re lucky to choose Hudi as our Lakehouse. Thanks to the powerful Hudi community!” – Bing Jiang