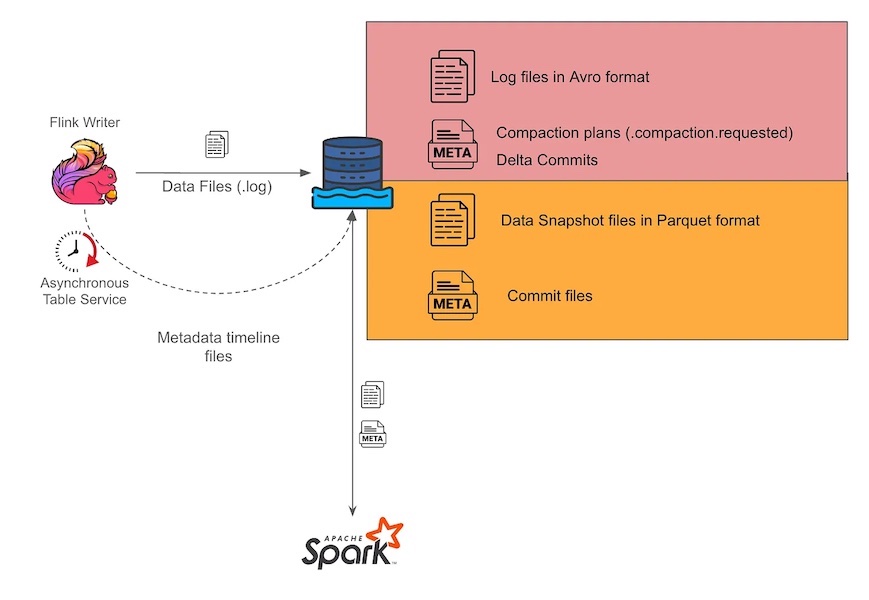
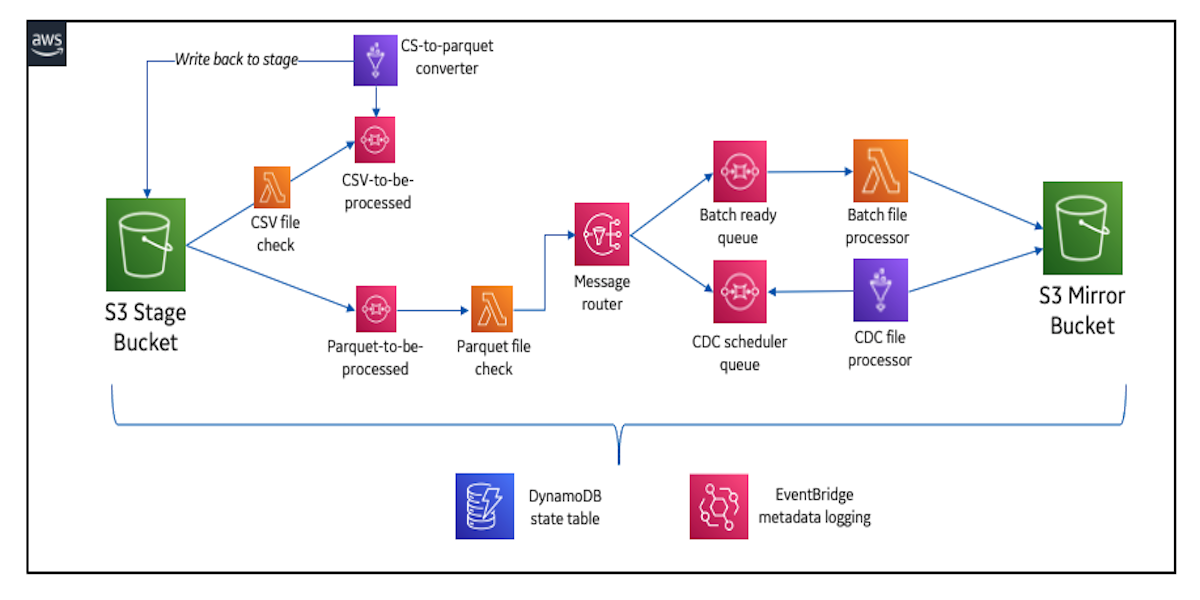
Enabling near real-time data analytics on the data lakeFebruary 23, 2024 by Shi Kai Ng and Shuguang Xiangbimorgrab
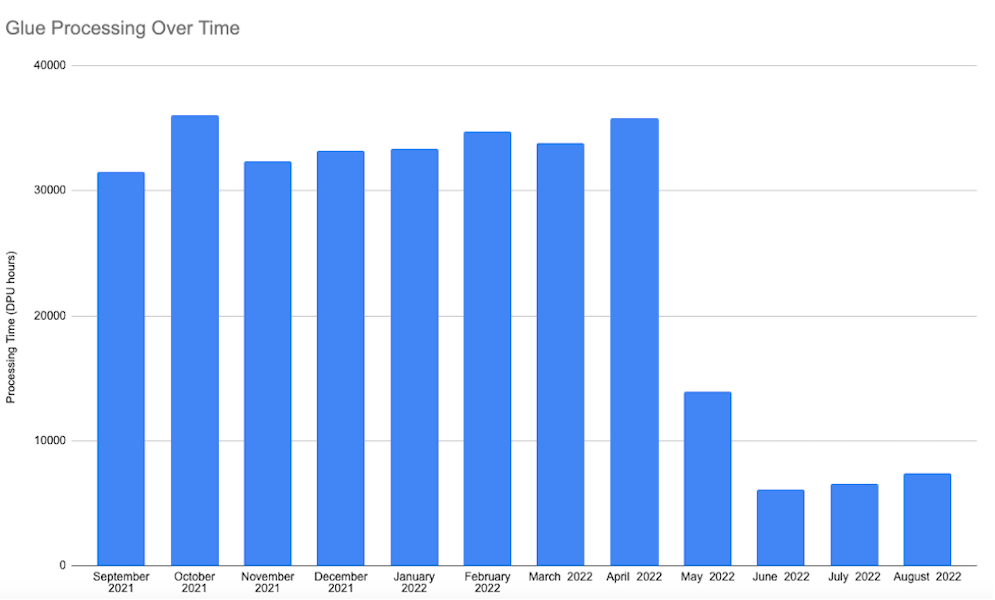
How Hudl built a cost-optimized AWS Glue pipeline with Apache Hudi datasetsNovember 10, 2022 by Indira Balakrishnan, Ramzi Yassine and Swagat Kulkarniperformanceincremental processingbiaws
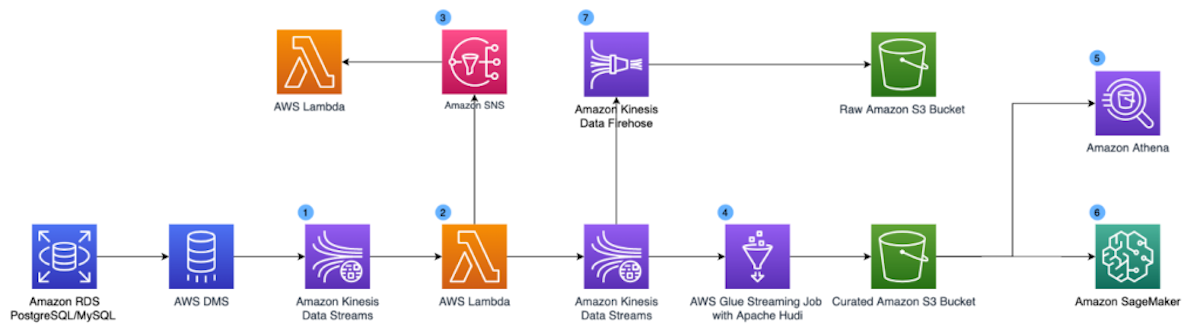
How NerdWallet uses AWS and Apache Hudi to build a serverless, real-time analytics platformAugust 9, 2022 by Kevin Chun and Dylan Qubiincremental processingaws
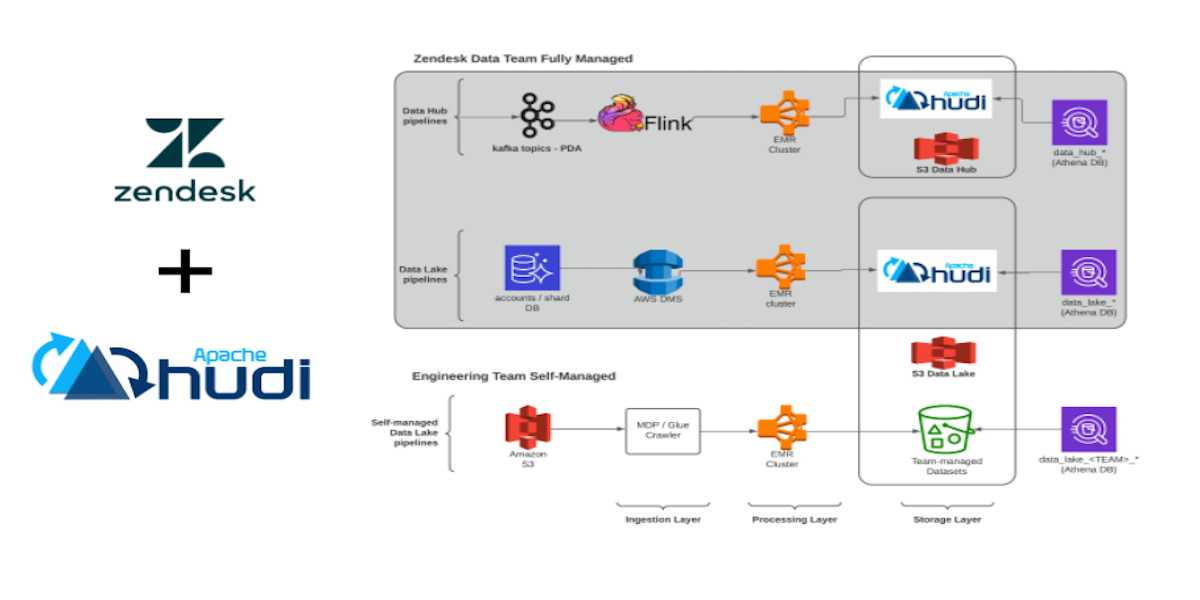
Zendesk - Insights for CTOs: Part 3 – Growing your business with modern data capabilitiesMarch 24, 2022 by Syed Jaffry and Johnathan Hwangmodern data architecturebigdprstreamingaws
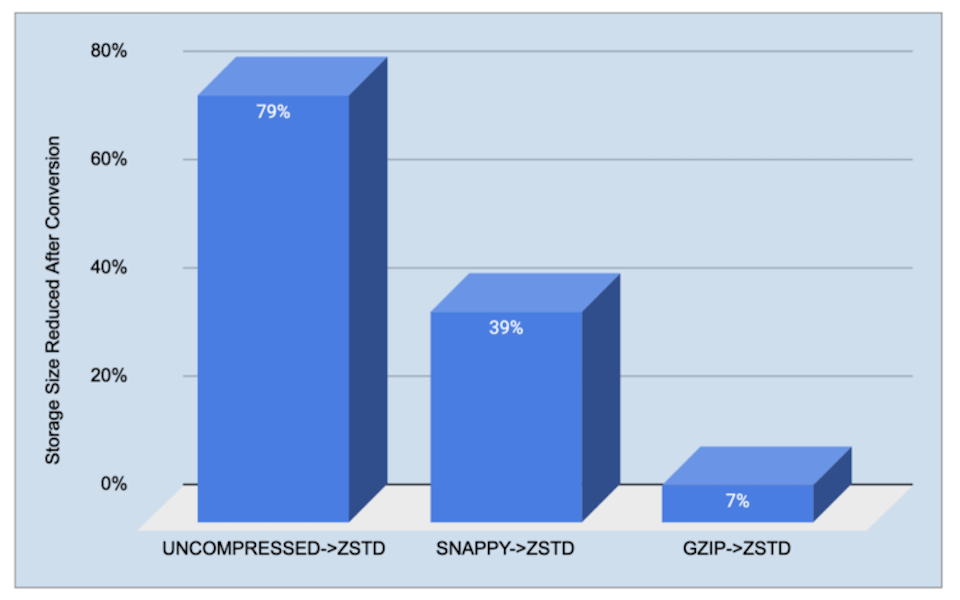
Cost Efficiency @ Scale in Big Data File FormatJanuary 25, 2022 by Xinli Shang, Kai Jiang, Zheng Shao and Mohammad Islamperformancecompressionbiuber
How GE Aviation built cloud-native data pipelines at enterprise scale using the AWS platformNovember 16, 2021 by Alcuin Weidus and Suresh Patnambiaws
How Amazon Transportation Service enabled near-real-time event analytics at petabyte scale using AWS Glue with Apache HudiOctober 14, 2021 by Madhavan Sriram, Diego Menin, Gabriele Cacciola and Kunal Gautambiaws
Building High-Performance Data Lake Using Apache Hudi and Alluxio at T3GoDecember 1, 2020 by t3gobiincremental processingcaching
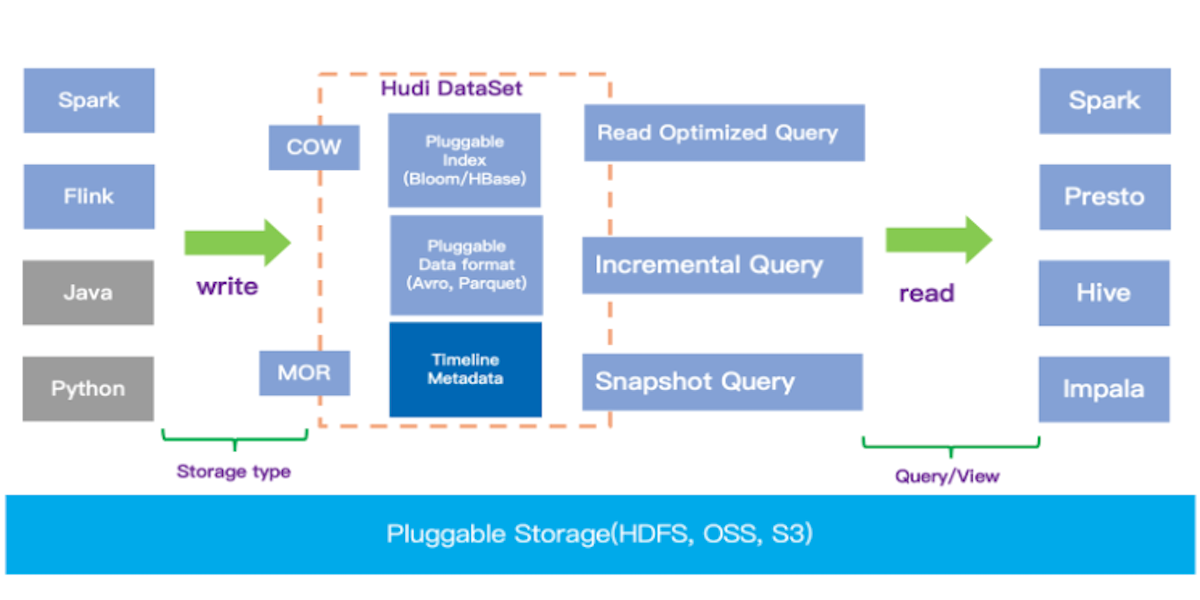
Building a Large-scale Transactional Data Lake at Uber Using Apache HudiJune 9, 2020 by Nishith Agarwaldata lakehousebiuber