Scaling Complex Data Workflows at Uber Using Apache Hudi
Uber’s trip and order collection pipelines grew highly complex, with long runtimes, massive DAGs, and rigid SQL logic that hampered scalability and maintainability. By adopting Apache Hudi, Uber re-architected these pipelines to enable incremental processing, custom merge behavior, and rule-based functional transformations. This reduced runtime from 20 hours to 4 hours, improved test coverage to 95%, cut costs by 60%, and delivered a composable, explainable, and scalable data workflow architecture.
At Uber, the Core Services Data Engineering team supports a wide range of use cases across products like Uber Mobility and Uber Eats. One critical use case is computing the collection - the net payable amount - from a trip or an order. While this sounds straightforward at first, it quickly becomes a complex data problem when you factor in real-world scenarios like refunds, tips, driver disputes, location updates, and settlement adjustments across multiple verticals.
To solve this problem at scale, Uber re-architected their pipelines using Apache Hudi to enable low-latency, incremental, and rule-based processing. This post outlines the challenges they faced, the architectural shifts they made, and the measurable outcomes they achieved in production.
The Challenge: Scale, Latency, and Complexity
Our original data pipelines were processing nearly 90 million records a day, but the nature of updates made them inefficient. For instance, a trip taken three years ago could still be updated due to a late settlement. Our statistical analysis showed most updates occur within 180 days, so we designed the system to read and write a 180-day window every day - leading to severe read and write amplification.
The pipeline itself was a massive DAG with over 50–60 tasks, taking close to 20 hours to complete. These long runtimes made recovery difficult and introduced operational risks. Making a change meant tracing the logic across this sprawling DAG, which affected developer productivity and increased the chances of regressions.
Despite the large window, we still missed updates that fell outside the 180-day mark, leading to data quality issues. The long development cycles and heavy debugging effort further hindered our ability to iterate and maintain the system.
Rigid SQL and Tight Coupling
Digging deeper, we identified multiple underlying causes. The pipeline relied heavily on SQL for all transformations. But expressing the evolving business rules for different Uber products in SQL was limiting. The logic had grown too complex to be managed effectively, and granular transformations led to a proliferation of intermediate stages. This made unit testing and debugging difficult, and the absence of structured logging made observability poor.
Additionally, data and logic were tightly coupled. The system often required joining tables at very fine granularities, introducing redundancy and making logic harder to reason about. Complex joins, table scans, and late-arriving data amplified processing costs. It was also difficult to trace how a specific row was transformed through the DAG, making explainability a real challenge.
How We Solved It?
- Solving Read Amplification
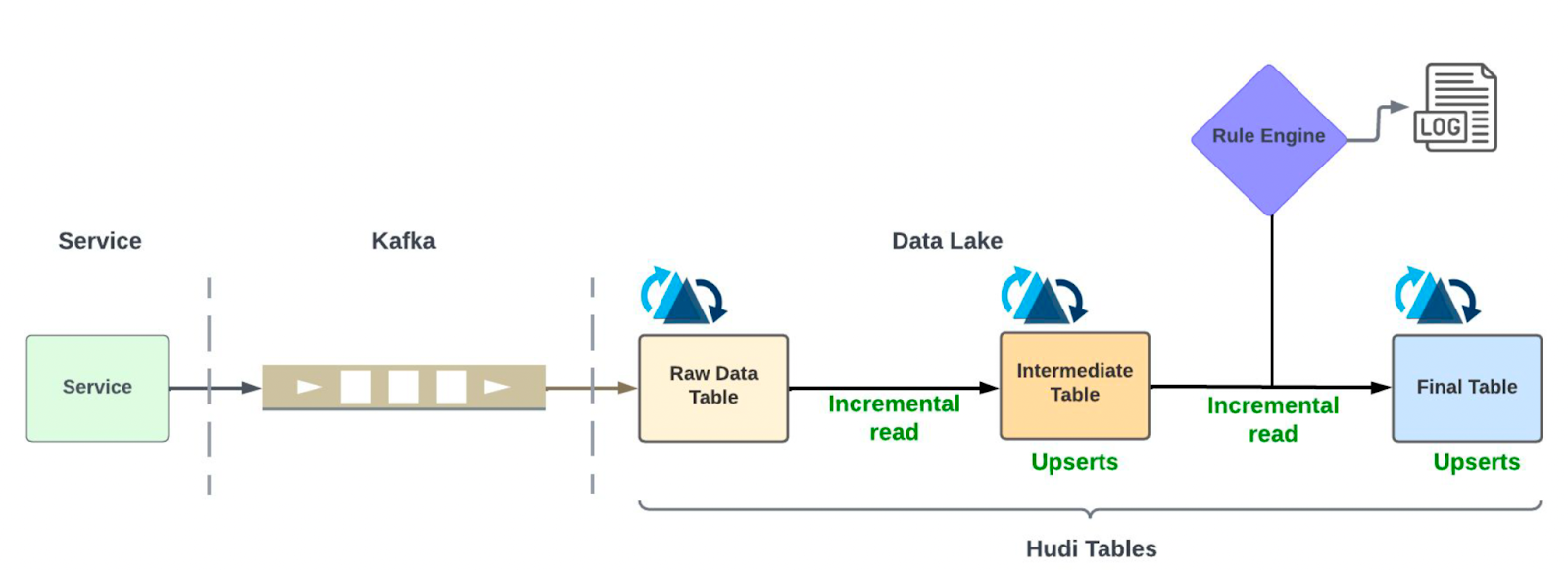
The first step in addressing inefficiencies was eliminating the brute-force strategy of scanning and processing a 180-day window of data on every pipeline run. With the help of Apache Hudi’s incremental read capabilities, we restructured the ingestion layer to read only the records that had mutated since the last checkpoint.
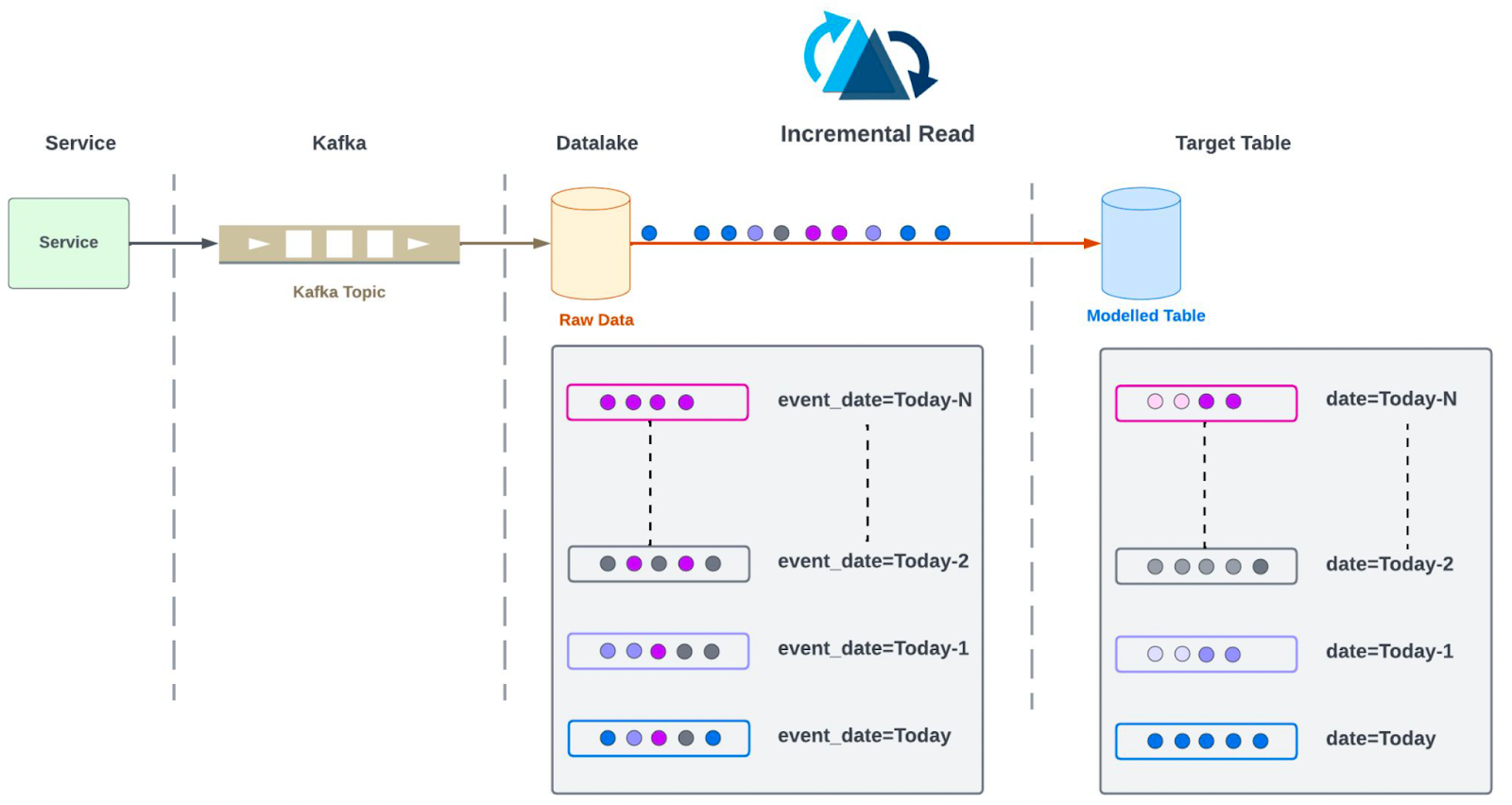
We introduced an intermediate Hudi table that consolidated all related records for a trip or order into a single row, using complex data types such as structs, lists, and maps. This model allowed us to capture the complete state of a trip - including all updates, tips, disputes, and refunds in one place, without scattering information across multiple joins.
By using this intermediate table as the foundation, all downstream logic could operate on change-driven inputs. The result was a pipeline that avoided unnecessary scans, improved correctness by processing all real changes (not just those in a time window), and reduced overall I/O dramatically.
- Eliminating Self Joins with Custom Payloads
Self joins - especially for reconciling updates to the same trip were one of the costliest operations in our original pipeline.
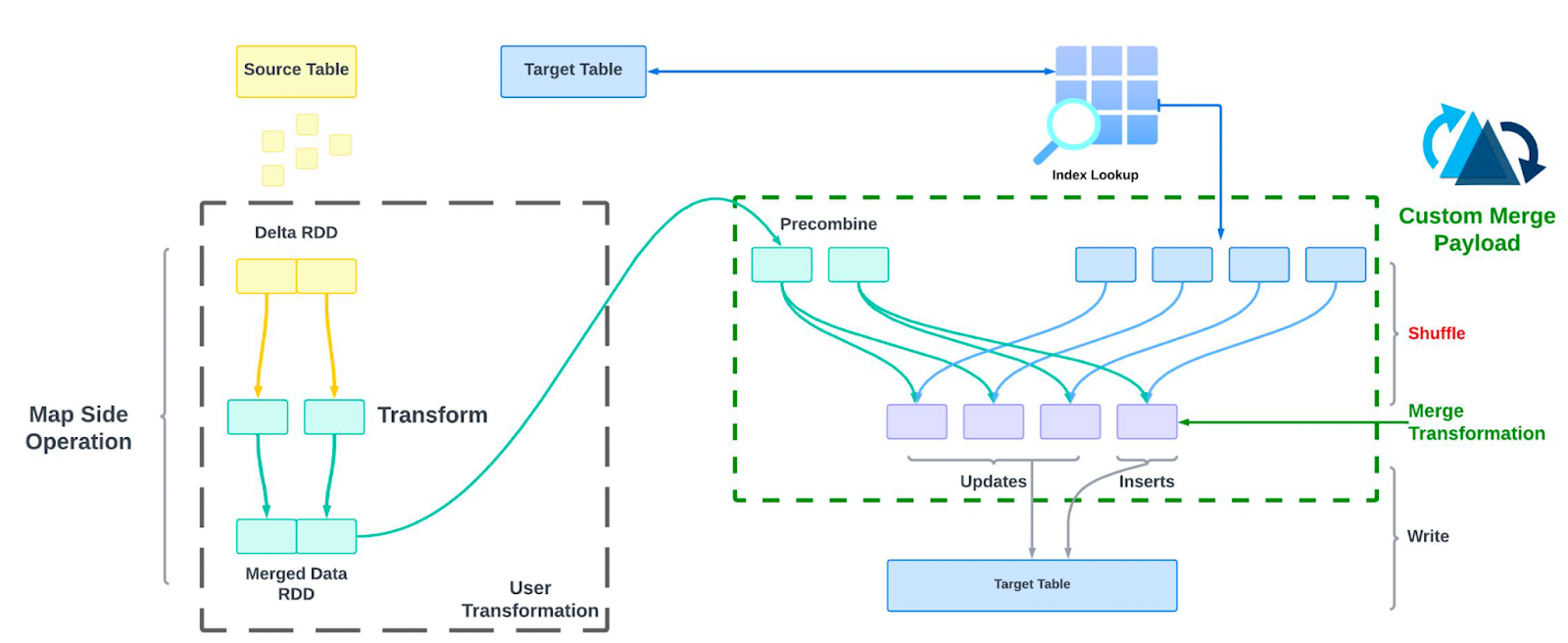
To solve this, we implemented a custom Hudi payload class that allows us to control how updates are applied during the merge phase. This class overrides methods such as combineAndGetUpdateValue and getInsertValue, and executes the merge logic as part of the write path, eliminating the need for a full table scan or shuffle.
This approach helped us efficiently handle updates to complex, nested records in the intermediate Hudi table, and dramatically reduced the cost associated with self joins.
- Simplifying Processing with a Rule-Based Framework
To move away from the rigidity of SQL, we designed a rule engine framework based on functional programming principles.
Instead of expressing business logic as large, monolithic SQL queries, we cast each input row (from the intermediate table) into a strongly typed object (e.g., a Trip object). These objects were then passed through a series of declarative rules - each consisting of a condition and an action.
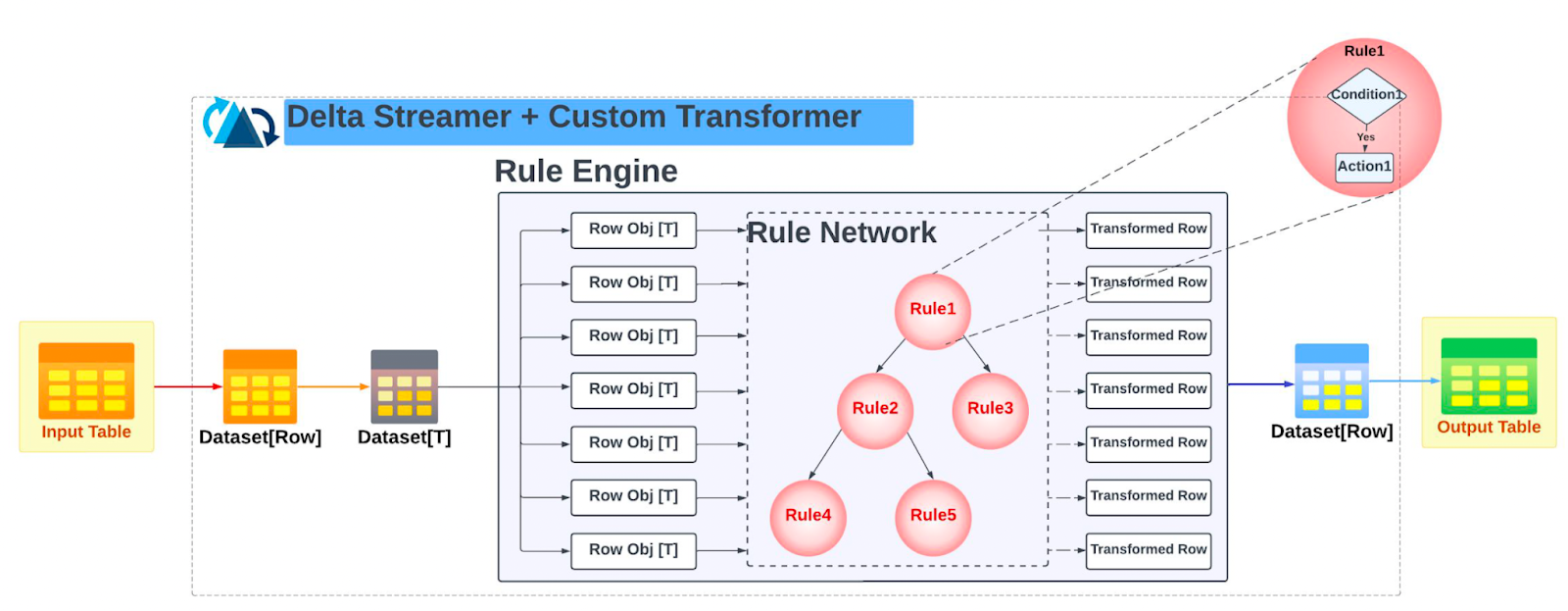
This framework was implemented as a custom transformer plugged into HudiStreamer. The transformer intercepts the ingested data, applies the rule engine logic, and emits the transformed object to the final Hudi output table. We also built in capabilities for:
- Logging and observability (for metrics and debugging)
- Unreachable state detection (flagging invalid rows)
- Unit testing support for each rule independently
This architecture replaced the huge DAG with modular, testable, and composable rule definitions, dramatically improving developer productivity and data pipeline clarity.
Final Architecture
The redesigned system follows a clean, composable structure:
- Incremental ingestion from the data lake is done using HudiStreamer, which writes to an intermediate Hudi table.
- The intermediate table consolidates all records for a trip using complex types, serving as the central input for downstream processing.
- A custom Transformer intercepts the records, casts them into typed domain objects, and passes them through a rule engine.
- The rule engine applies business logic declaratively and emits fully processed objects.
- The output is written to a final Hudi table that supports efficient, incremental consumption.
This design eliminates redundant scans, reduces shuffle overhead, enables full test coverage, and offers detailed observability across all transformation stages.
The Wins with Hudi
The improvements were substantial and measurable:
- Runtime reduced from ~20 hours to ~4 hours (~75% improvement)
- Test coverage increased to 95% for transformation logic
- Single run cost reduced by 60%
- Improved data completeness, processing all updates—not just those in a statistical window
- Reusable and modular logic, reducing DAG complexity
- Higher developer productivity, with isolated unit testing and simplified debugging
- Improved self-join performance through custom payloads
- A generic rule engine design, portable across Spark and Flink
Apache Hudi has been central to Nexus’ success, providing the core data lake storage layer for scalable ingestion, updates, and metadata management. It enables fast, incremental updates at massive scale while maintaining transactional guarantees on top of Amazon S3.
Conclusion
By redesigning the system around Apache Hudi and adopting functional, rule-based processing, Uber was able to transform a brittle, long-running pipeline into a maintainable and efficient architecture. The changes allowed them to scale their data workflows to meet the needs of complex, multi-product use cases without compromising on performance, observability, or data quality.
This work highlights the power of pairing the right storage format with a principled architectural approach. Apache Hudi was instrumental in helping achieve these outcomes and continues to play a key role in Uber’s evolving data platform.
This blog is based on Uber’s presentation at the Apache Hudi Community Sync. If you are interested in watching the recorded version of the video, you can find it here.