Scaling Autonomous Vehicle Data Infrastructure with Apache Hudi at Applied IntuitionJanuary 22, 2026 by The Hudi Communitydata lakehouseapplied intuition
Apache Hudi™ at Uber: Engineering for Trillion-Record-Scale Data Lake OperationsJanuary 16, 2026 by Team at Uberuber
From Legacy to Leading: Funding Circle's Journey with Apache HudiJanuary 15, 2026 by The Hudi Communitydata lakehousefunding circle
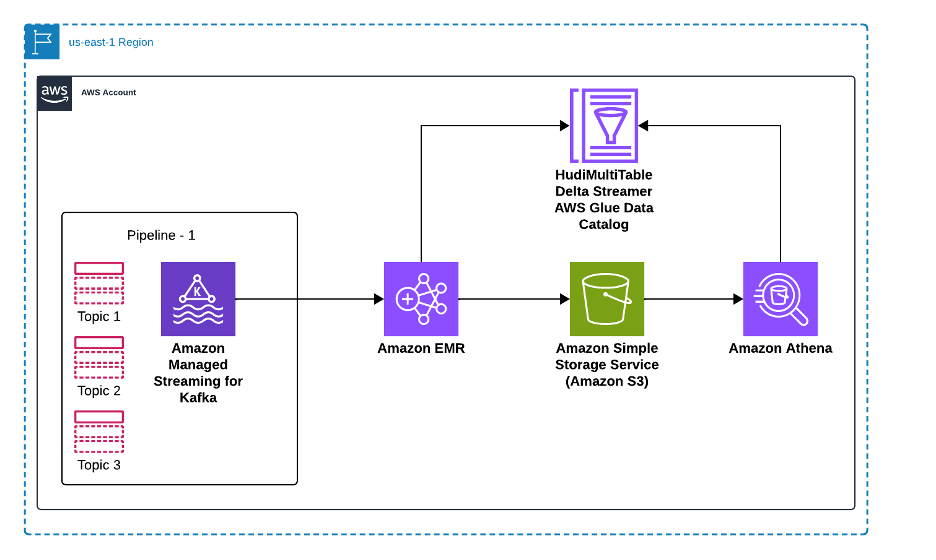
Using Amazon EMR DeltaStreamer to stream data to multiple Apache Hudi tablesJanuary 15, 2026 by AWS Big Data Blogawshudi streamer
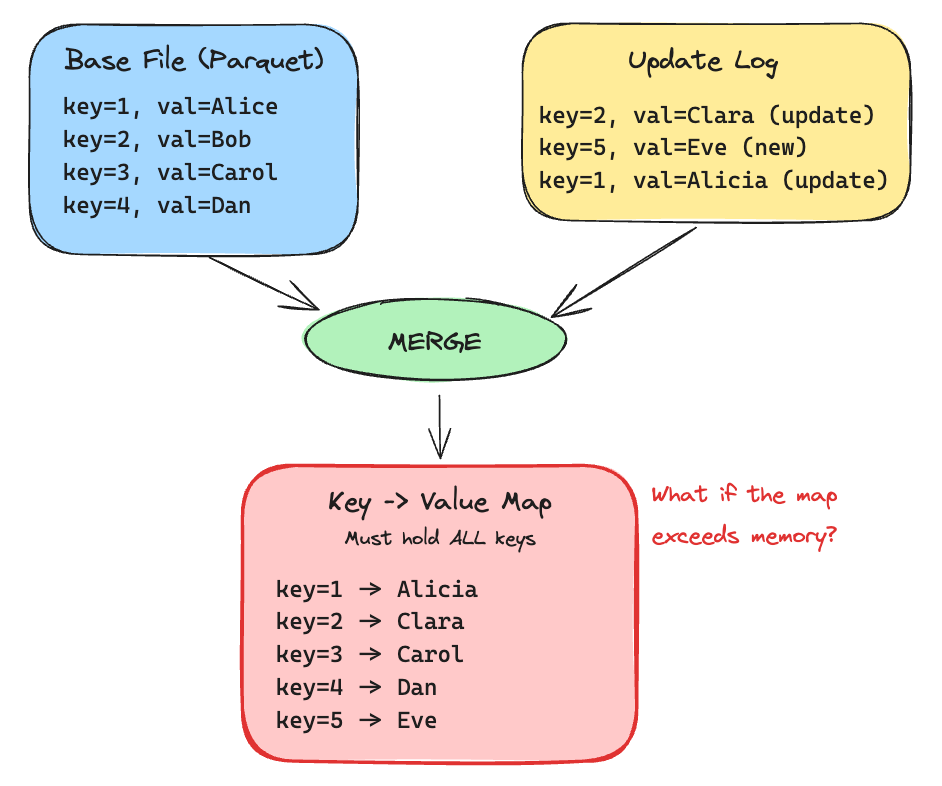
ExternalSpillableMap: Handle Maps Too Big for MemoryJanuary 13, 2026 by Yongkyunperformanceapache spark
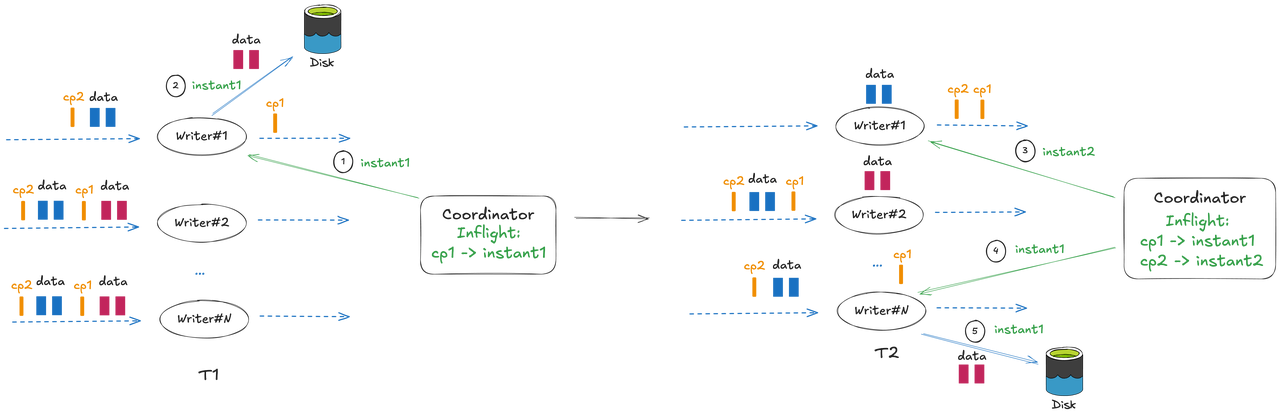
Apache Hudi 1.1 Deep Dive: Async Instant Time Generation for Flink WritersJanuary 9, 2026 by Shuo Chengapache flinkstreaming
How Zupee Cut S3 Costs by 60% with Apache HudiDecember 22, 2025 by The Hudi Communitydata lakehousezupee
Maximizing Throughput with Apache Hudi NBCC: Stop Retrying, Start ScalingDecember 16, 2025 by Shiyan Xudata lakehouseconcurrency controlstreaming
From Batch to Streaming: Accelerating Data Freshness in Uber's Data LakeDecember 12, 2025 by Uber Engineeringstreamingapache flinkdata lakehouseuber
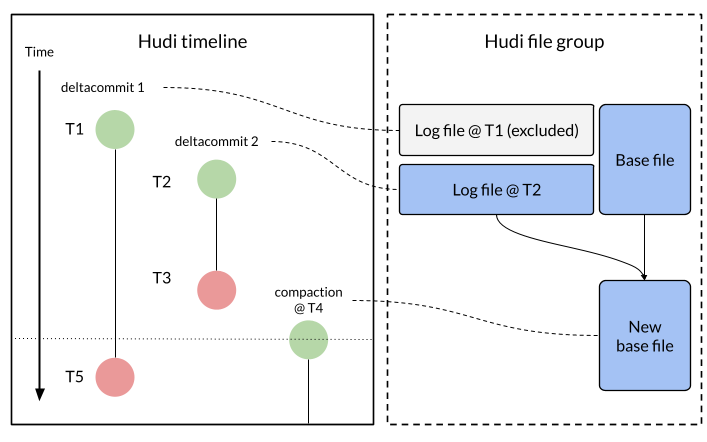
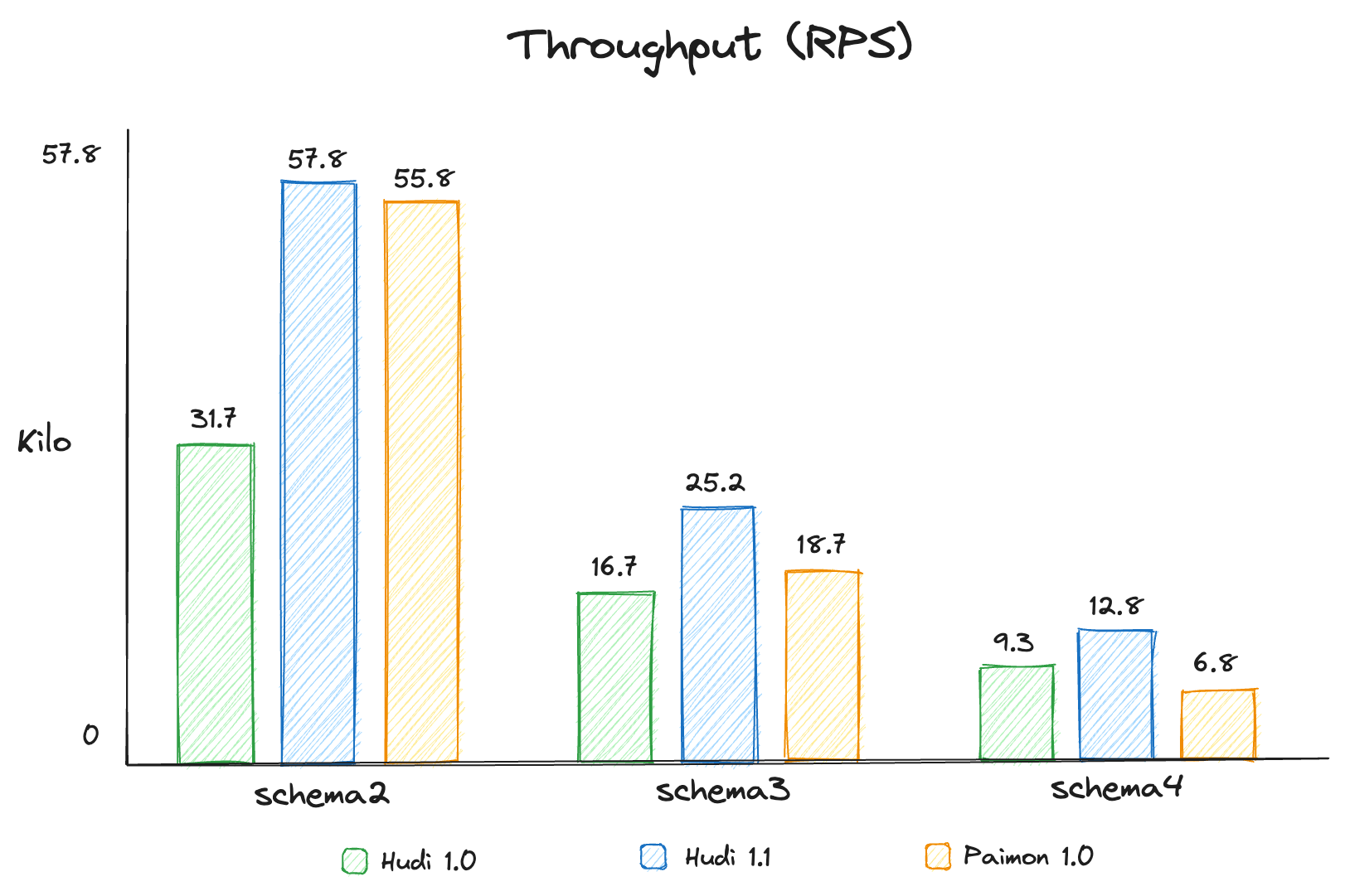
Apache Hudi 1.1 Deep Dive: Optimizing Streaming Ingestion with Apache FlinkDecember 10, 2025 by Shuo Chengapache flinkapache paimonperformance