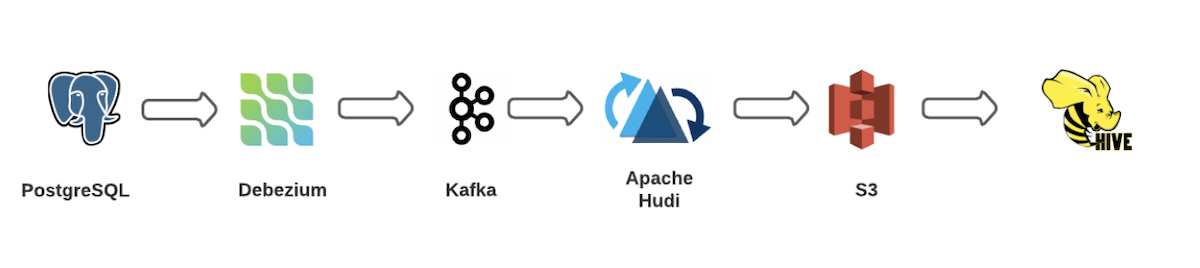
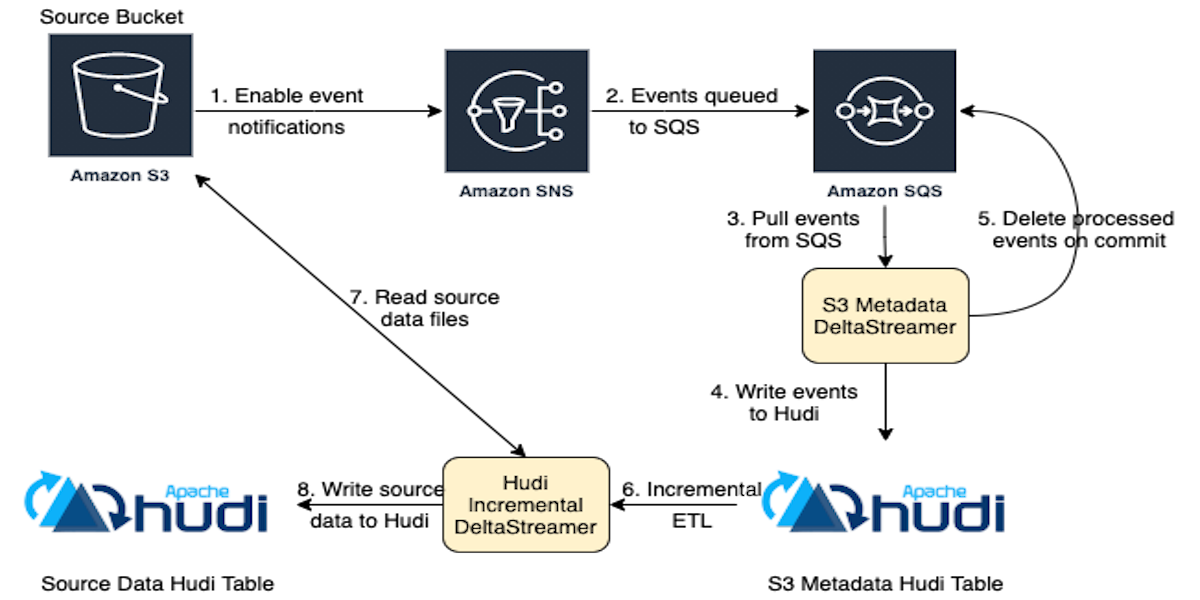
The Art of Building Open Data Lakes with Apache Hudi, Kafka, Hive, and DebeziumDecember 31, 2021 by Gary Stafforddata lakehouse
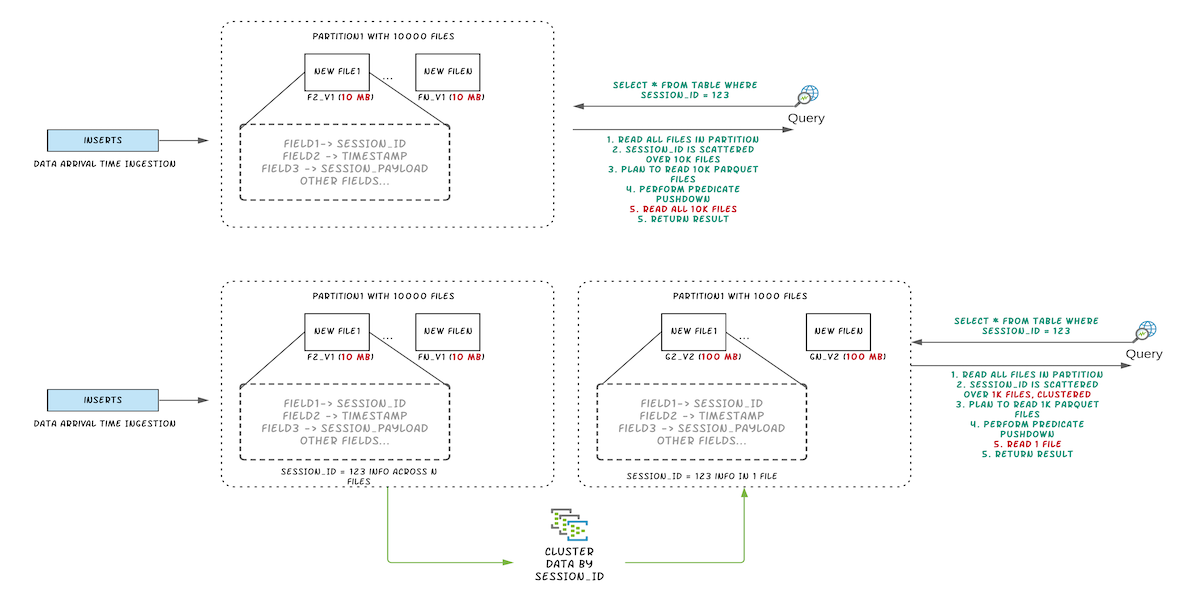
Hudi Z-Order and Hilbert Space Filling CurvesDecember 29, 2021 by Alexey Kudinkin and Tao Mengclusteringdata skipping
New features from Apache Hudi 0.7.0 and 0.8.0 available on Amazon EMRDecember 20, 2021 by Udit Mehrotra and Gagan Brahmiaws
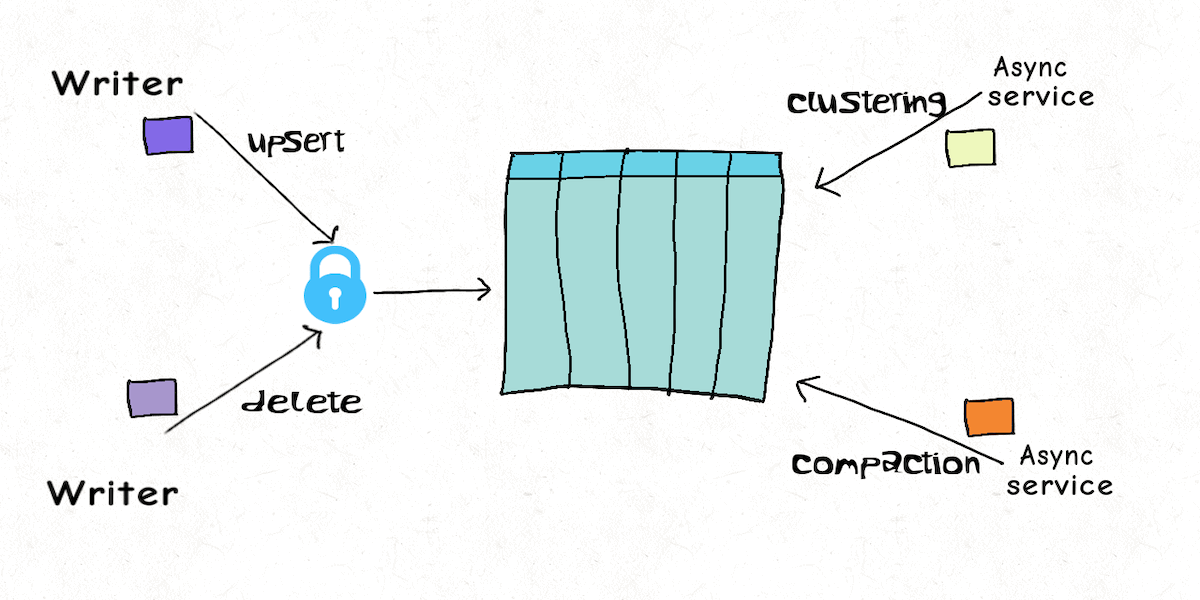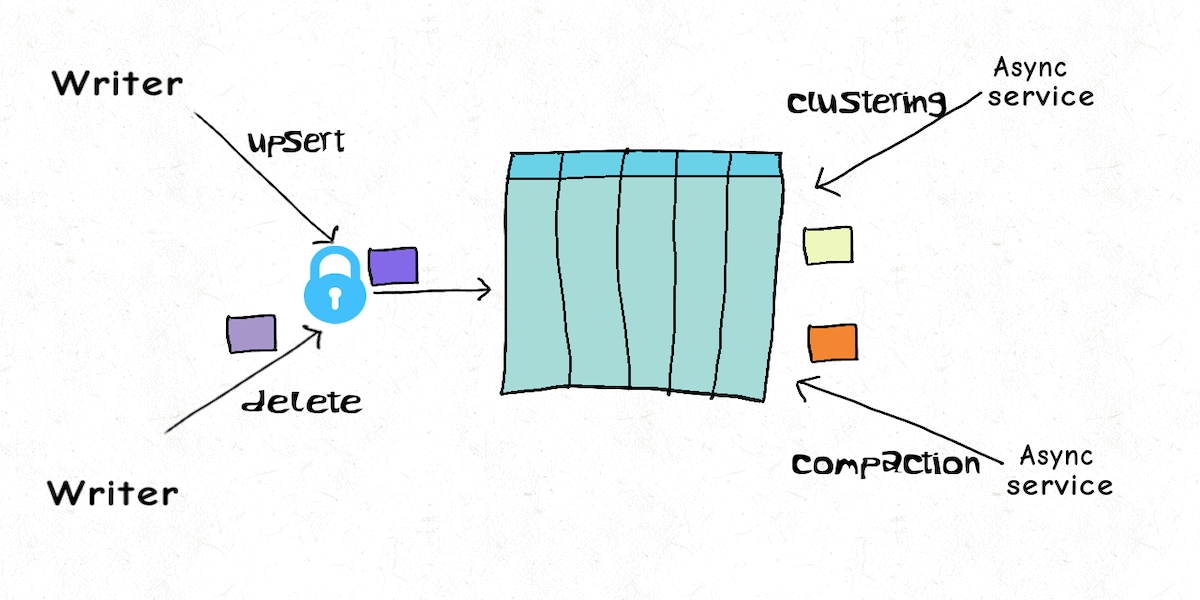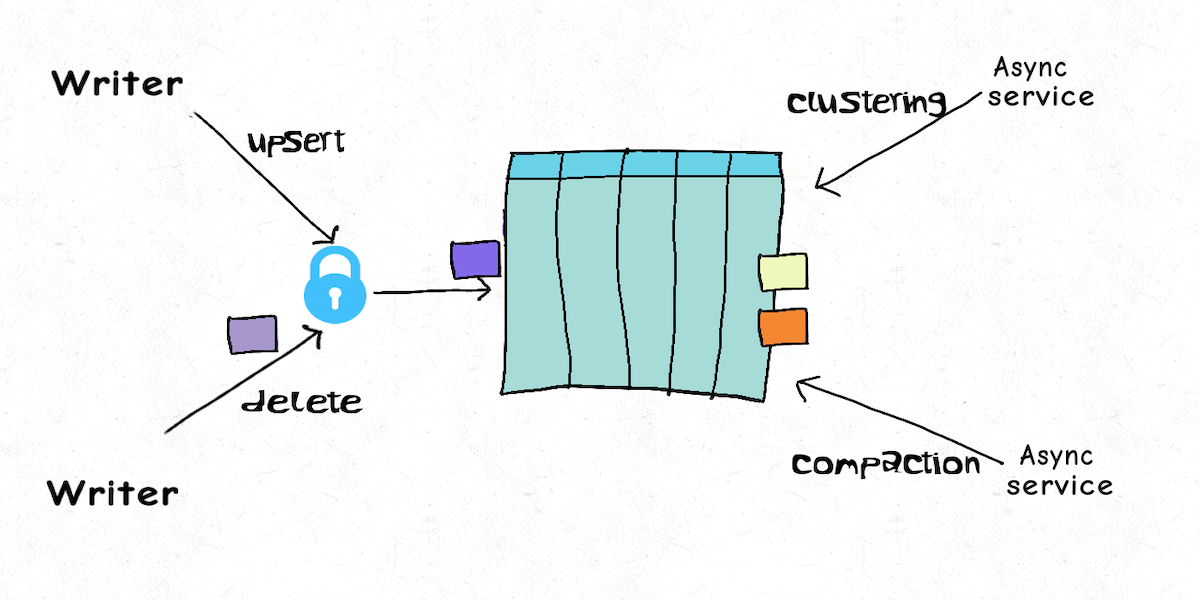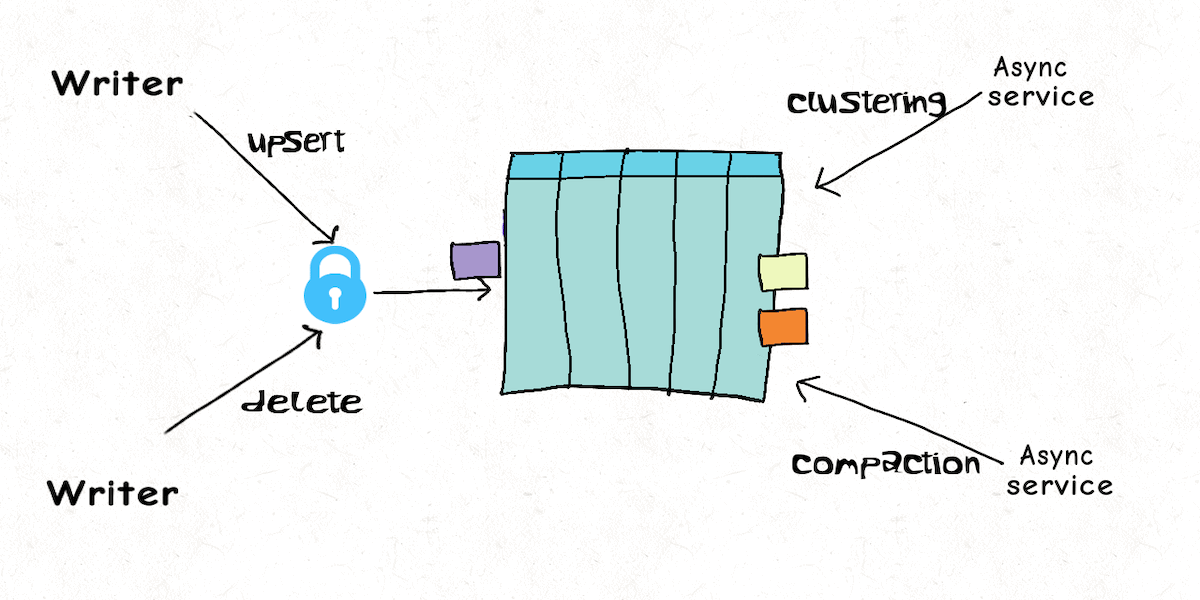
Lakehouse Concurrency Control: Are we too optimistic?December 16, 2021 by Vinoth Chandarconcurrency control
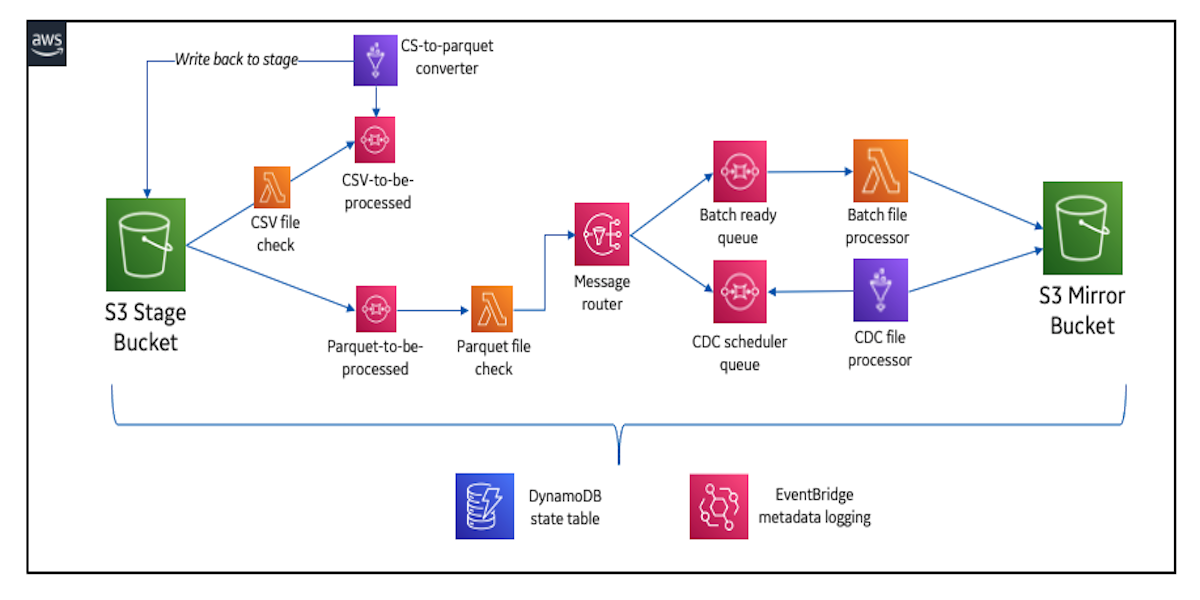
How GE Aviation built cloud-native data pipelines at enterprise scale using the AWS platformNovember 16, 2021 by Alcuin Weidus and Suresh Patnambiaws
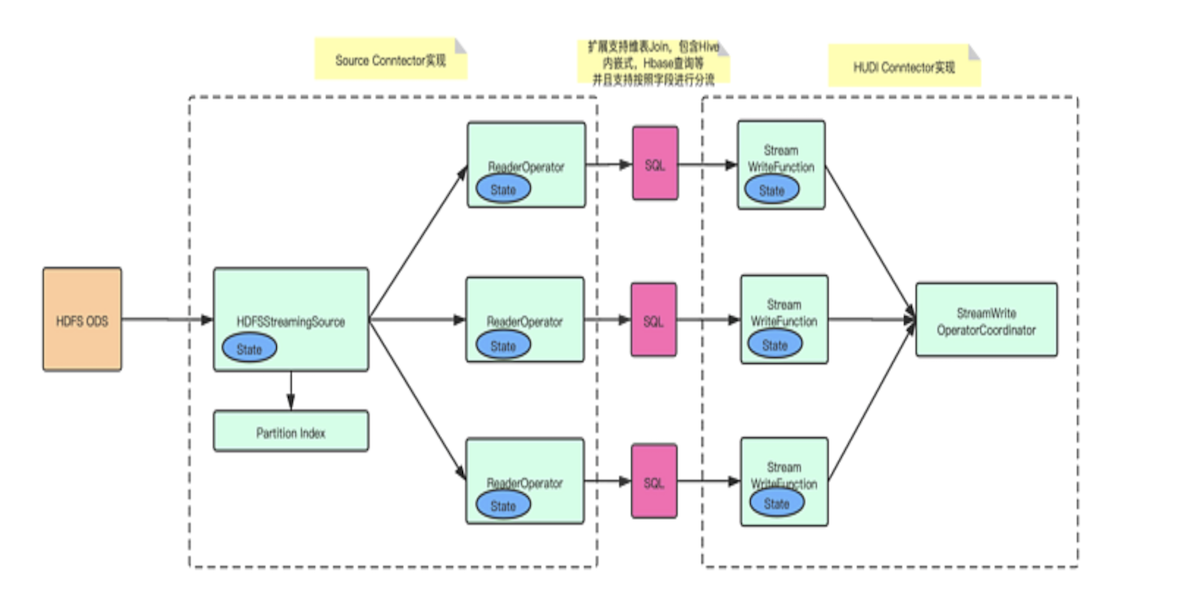
Practice of Apache Hudi in building real-time data lake at station BOctober 21, 2021 by Yu Zhaojingdata lakehouse
How Amazon Transportation Service enabled near-real-time event analytics at petabyte scale using AWS Glue with Apache HudiOctober 14, 2021 by Madhavan Sriram, Diego Menin, Gabriele Cacciola and Kunal Gautambiaws
Building an ExaByte-level Data Lake Using Apache Hudi at ByteDanceSeptember 1, 2021 by Ziyue Guan, translated to English by yihuadata lakehouseperformance