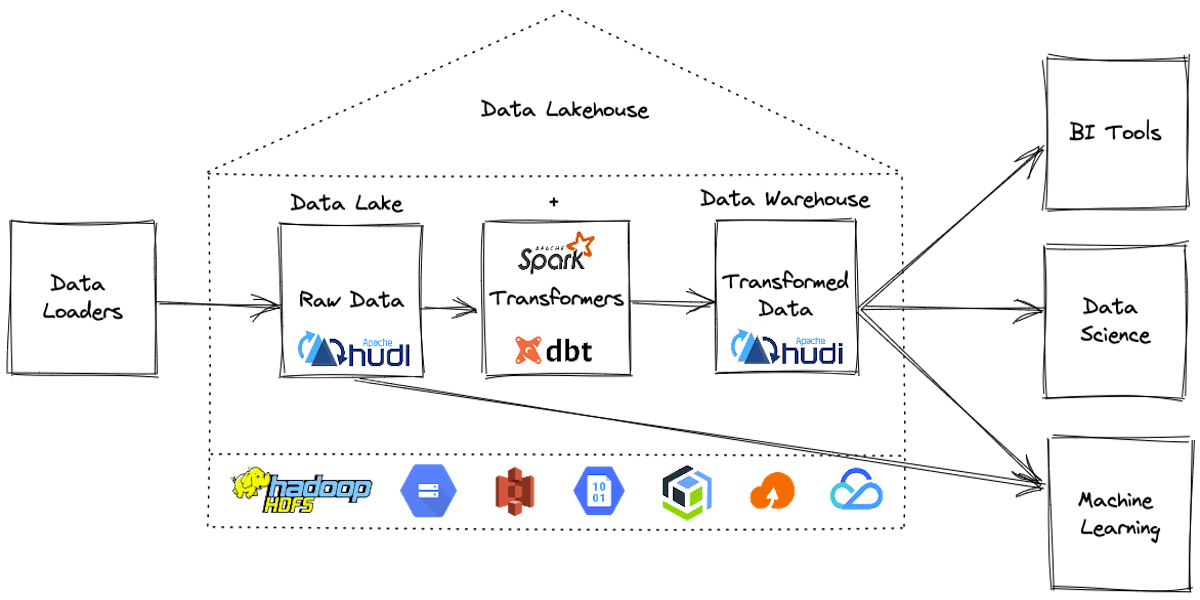
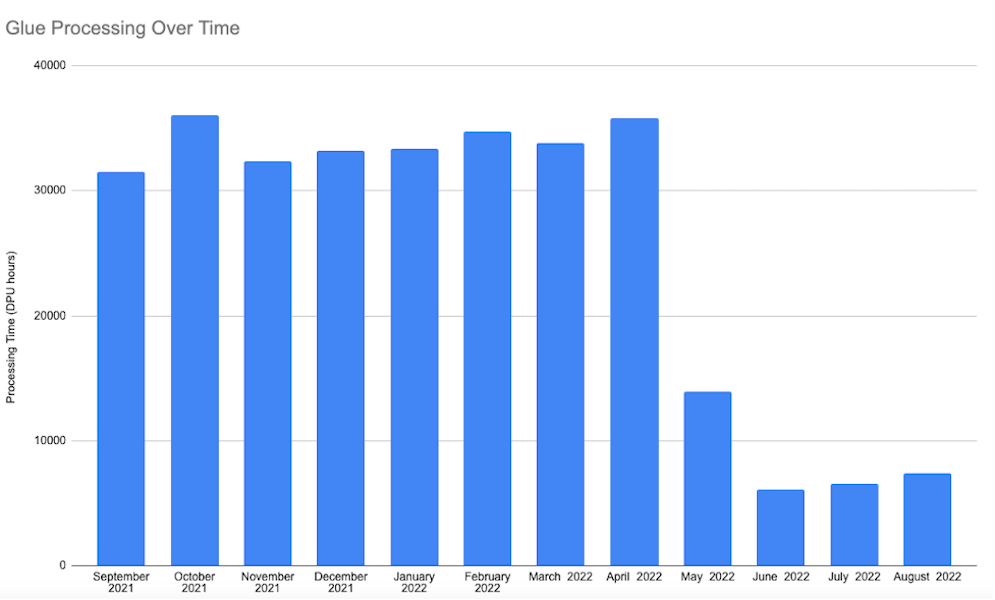
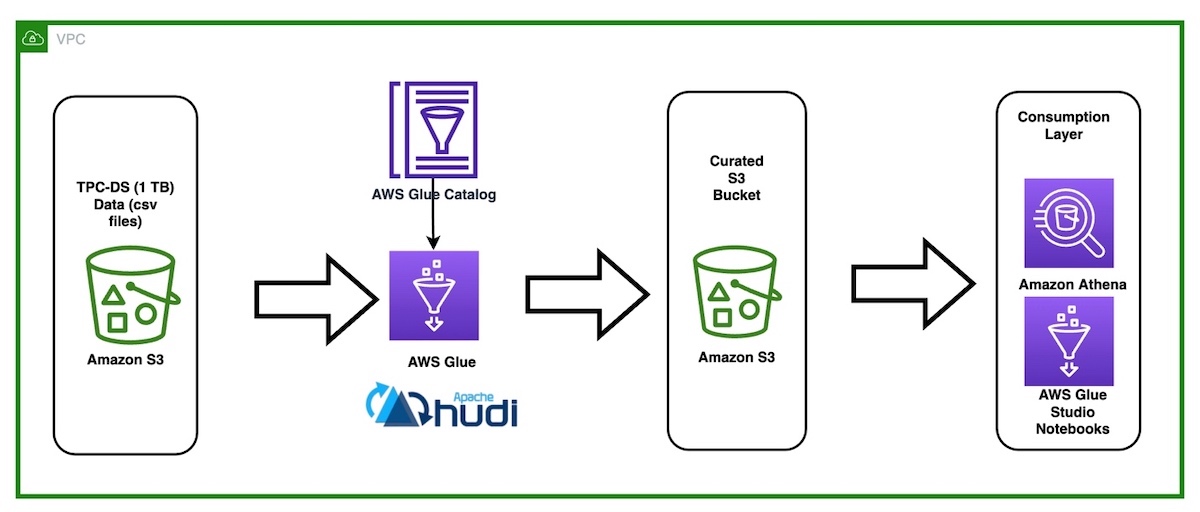
How Hudl built a cost-optimized AWS Glue pipeline with Apache Hudi datasets
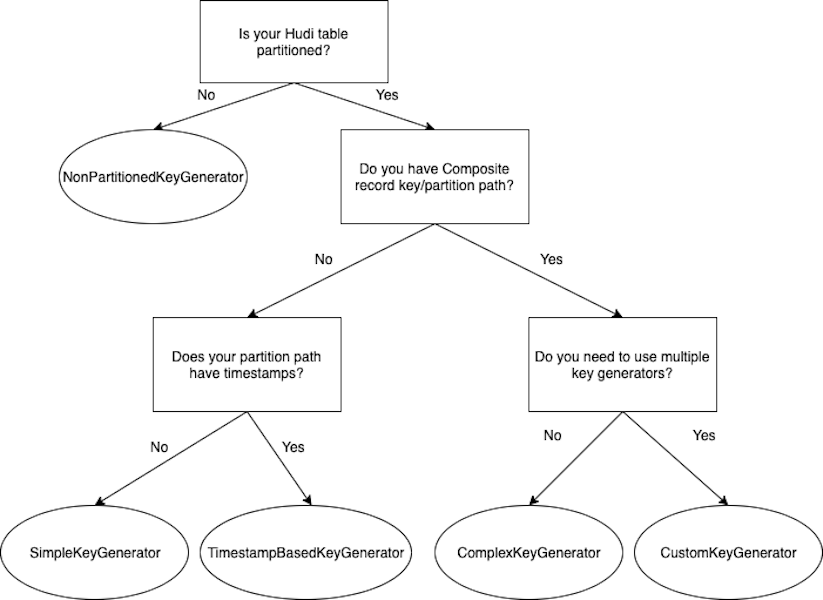
Get started with Apache Hudi using AWS Glue by implementing key design concepts – Part 1
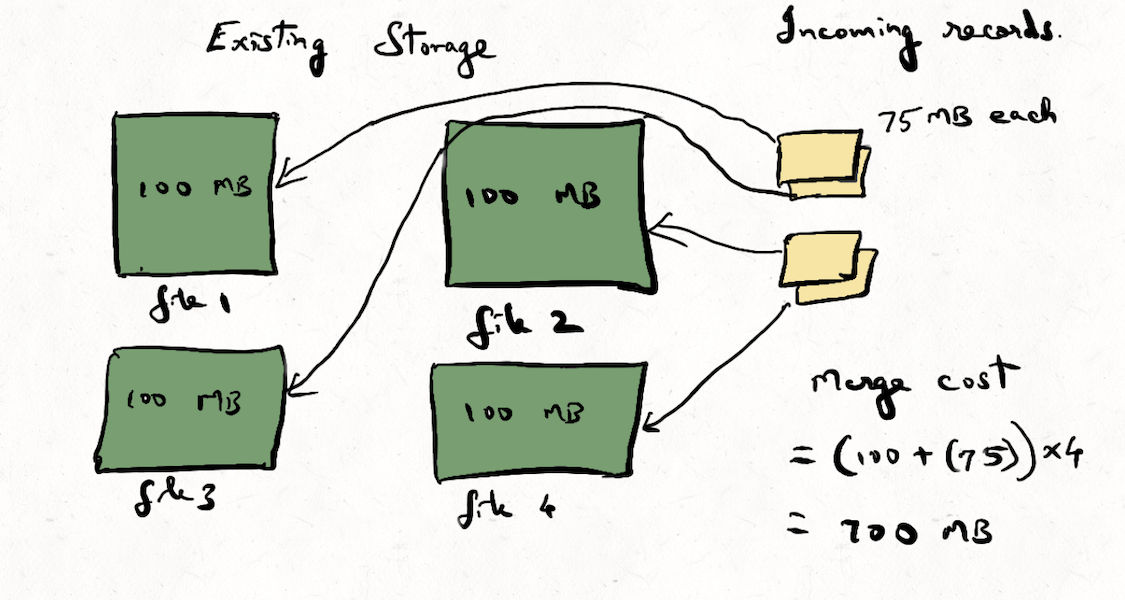
What, Why and How : Apache Hudi’s Bloom Index
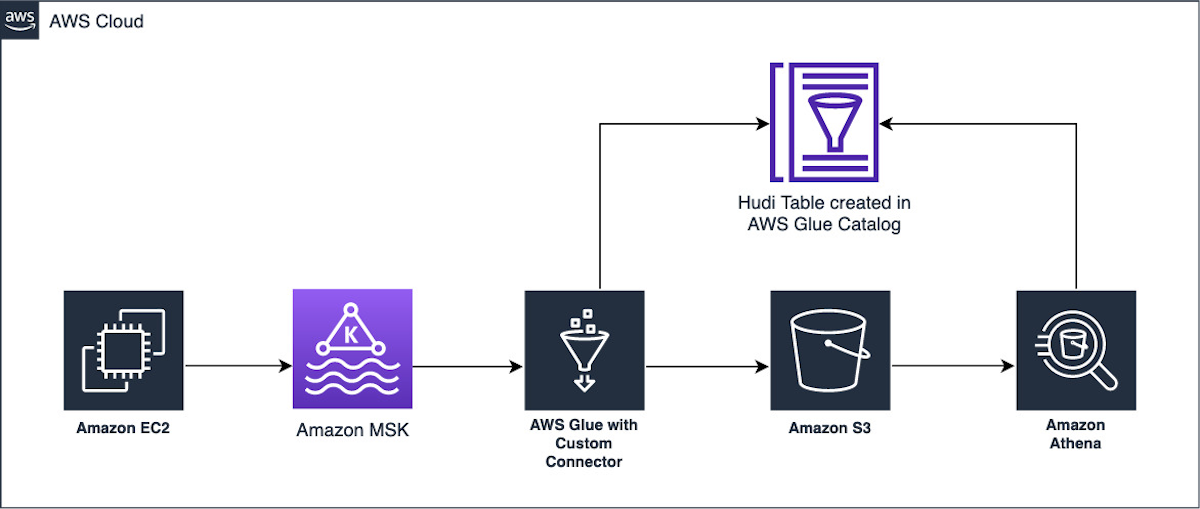
Ingest streaming data to Apache Hudi tables using AWS Glue and Apache Hudi DeltaStreamer

Data processing with Spark: time traveling

Building Streaming Data Lakes with Hudi and MinIO

Data Lake / Lakehouse Guide: Powered by Data Lake Table Formats (Delta Lake, Iceberg, Hudi)

Implementation of SCD-2 (Slowly Changing Dimension) with Apache Hudi & Spark
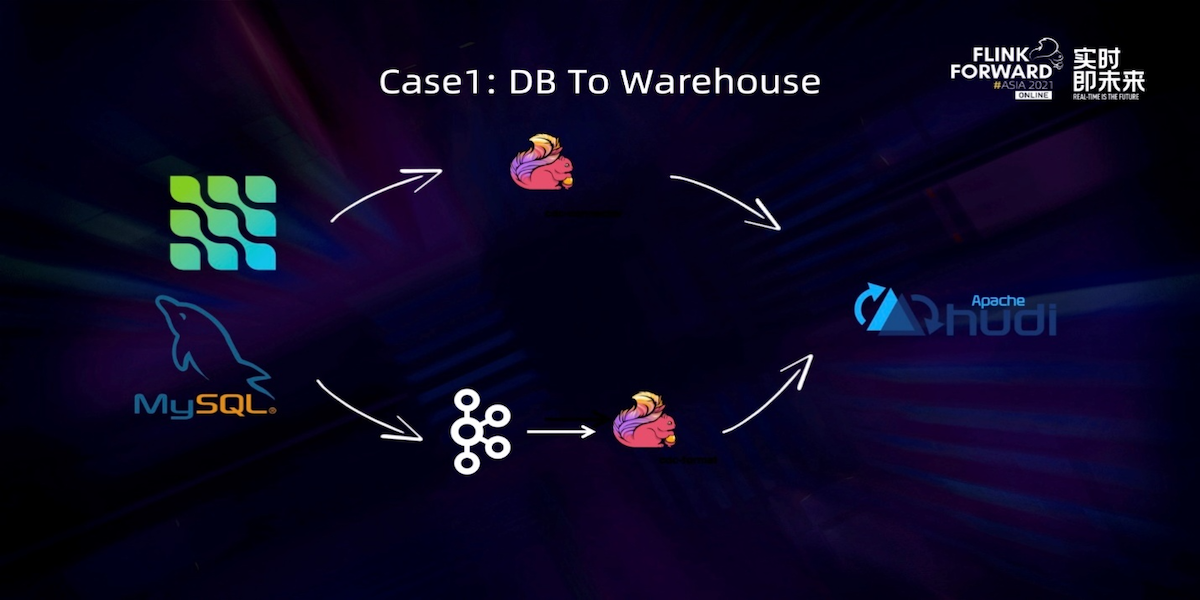
Use Flink Hudi to Build a Streaming Data Lake Platform
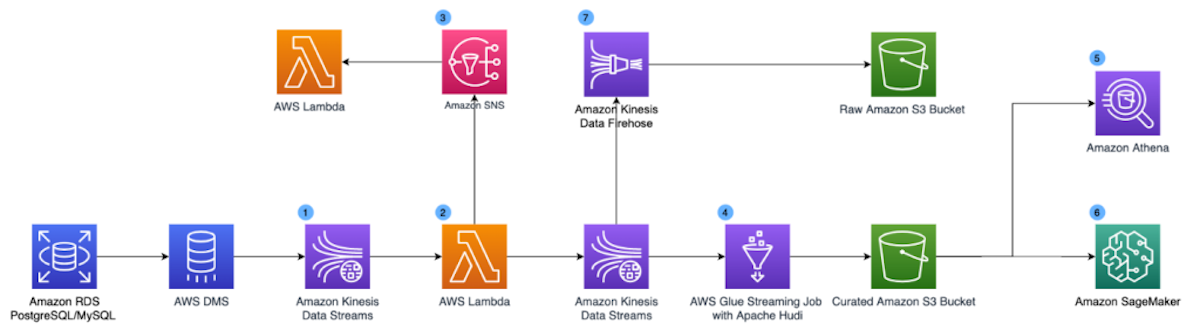
How NerdWallet uses AWS and Apache Hudi to build a serverless, real-time analytics platform