Apache Hudi Technical Specification
| Syntax | Description |
|---|---|
| Last Updated | Aug 2022 |
| Table Version | 5 |
This document is a specification for the Hudi's Storage Format which transforms immutable cloud/file storage systems into transactional data lakes.
Overview
Hudi Storage Format enables the following features over very large collections of files/objects
- Stream processing primitives like incremental merges, change stream etc
- Database primitives like tables, transactions, mutability, indexes and query performance optimizations
Apache Hudi is an open source data lake platform that is built on top of the Hudi Storage Format and it unlocks the following capabilities.
- Unified Computation Model - a unified way to combine large batch style operations and frequent near real time streaming operations over large datasets.
- Self-Optimized Storage - automatically handle all the table storage maintenance such as compaction, clustering, vacuuming asynchronously and in most cases non-blocking to actual data changes.
- Cloud Native Database - abstracts Table/Schema from actual storage and ensures up-to-date metadata and indexes unlocking multi-fold read and write performance optimizations.
- Engine Neutrality - designed to be neutral and without any assumptions on the preferred computation engine. Apache Hudi will manage metadata, and provide common abstractions and pluggable interfaces to most/all common compute/query engines.
This document is intended as reference guide for any compute engines, that aim to write/read Hudi tables, by interacting with the storage format directly.
Storage Format
Data Layout
At a high level, Hudi organizes data into a directory structure under the base path (root directory for the Hudi table). The directory structure can be flat (non-partitioned) or based on coarse-grained partitioning values set for the table. Non-partitioned tables store all the data files under the base path.
Note that, unlike Hive style partitioning, partition columns are not removed from data files and partitioning is a mere organization of data files. A special reserved .hoodie directory under the base path is used to store transaction logs and metadata.
A special file hoodie.properties persists table level configurations, shared by writers and readers of the table. These configurations are explained here,
and any config without a default value needs to be specified during table creation.
/data/hudi_trips/ <== Base Path
├── .hoodie/ <== Meta Path
| └── hoodie.properties <== Table Configs
│ └── metadata/ <== Table Metadata
├── americas/
│ ├── brazil/
│ │ └── sao_paulo/ <== Partition Path
│ │ ├── <data_files>
│ └── united_states/
│ └── san_francisco/
│ ├── <data_files>
└── asia/
└── india/
└── chennai/
├── <data_files>
Table Types
Hudi storage format supports two table types offering different trade-offs between ingest and query performance and the data files are stored differently based on the chosen table type. Broadly, there can be two types of data files
- Base files - Files that contain a set of records in columnar file formats like Apache Parquet/Orc or indexed formats like HFile format.
- log files - Log files contain inserts, updates, deletes issued against a base file, encoded as a series of blocks. More on this below.
| Table Type | Trade-off |
|---|---|
| Copy-on-Write (CoW) | Data is stored entirely in base files, optimized for read performance and ideal for slow changing datasets |
| Merge-on-read (MoR) | Data is stored in a combination of base and log files, optimized to balance the write and read performance and ideal for frequently changing datasets |
Data Model
Hudi's data model is designed like an update-able database like a key-value store. Within each partition, data is organized into key-value model, where every record is uniquely identified with a record key.
User fields
To write a record into a Hudi table, each record must specify the following user fields.
| User fields | Description |
|---|---|
| Partitioning key [Optional] | Value of this field defines the directory hierarchy within the table base path. This essentially provides an hierarchy isolation for managing data and related metadata |
| Record key(s) | Record keys uniquely identify a record within each partition if partitioning is enabled |
| Ordering field(s) | Hudi guarantees the uniqueness constraint of record key and the conflict resolution configuration manages strategies on how to disambiguate when multiple records with the same keys are to be merged into the table. The resolution logic can be based on an ordering field or can be custom, specific to the table. To ensure consistent behaviour dealing with duplicate records, the resolution logic should be commutative, associative and idempotent. This is also referred to as ‘precombine field’. |
Meta fields
In addition to the fields specified by the table's schema, the following meta fields are added to each record, to unlock incremental processing and ease of debugging. These meta fields are part of the table schema and stored with the actual record to avoid re-computation.
| Hudi meta-fields | Description |
|---|---|
| _hoodie_commit_time | This field contains the commit timestamp in the timeline that created this record. This enables granular, record-level history tracking on the table, much like database change-data-capture. |
| _hoodie_commit_seqno | This field contains a unique sequence number for each record within each transaction. This serves much like offsets in Apache Kafka topics, to enable generating streams out of tables. |
| _hoodie_record_key | Unique record key identifying the record within the partition. Key is materialized to avoid changes to key field(s) resulting in violating unique constraints maintained within a table. |
| _hoodie_partition_path | Partition path under which the record is organized into. |
| _hoodie_file_name | The data file name this record belongs to. |
Within a given file, all records share the same values for _hoodie_partition_path and _hoodie_file_name, thus easily compressed away without any overheads with columnar file formats. The other fields can also be optional for writers
depending on whether protection against key field changes or incremental processing is desired. More on how to populate these fields in the sections below.
Transaction Log (Timeline)
Hudi serializes all actions performed on a table into an event log - called the Timeline. Every transactional action on the Hudi table creates a new entry (instant) in the timeline. Data consistency in Hudi is provided using Multi-version Concurrency Control (MVCC) and all transactional actions follow the state transitions below, to move each file group from one consistent state to another.
- requested - Action is planned and requested to start on the timeline.
- inflight - Action has started running and is currently in-flight. Actions are idempotent, and could fail many times in this state.
- completed - Action has completed running
All actions and the state transitions are registered with the timeline using an atomic write of a special meta-file inside the .hoodie directory. The requirement from the underlying storage system is to support an atomic-put and read-after-write consistency. The meta file naming structure is as follows
[Action timestamp].[Action type].[Action state]
Action timestamp: Monotonically increasing value to denote strict ordering of actions in the timeline. This could be provided by an external token provider or rely on the system epoch time at millisecond granularity.
Action type: Type of action. The following are the actions on the Hudi timeline.
| Action type | Description |
|---|---|
| commit | Commit denotes an atomic write (inserts, updates and deletes) of records in a table. A commit in Hudi is an atomic way of updating data, metadata and indexes. The guarantee is that all or none the changes within a commit will be visible to the readers |
| deltacommit | Special version of commit which is applicable only on a Merge-on-Read storage engine. The writes are accumulated and batched to improve write performance |
| rollback | Rollback denotes that the changes made by the corresponding commit/delta commit were unsuccessful & hence rolled back, removing any partial files produced during such a write |
| savepoint | Savepoint is a special marker to ensure a particular commit is not automatically cleaned. It helps restore the table to a point on the timeline, in case of disaster/data recovery scenarios |
| restore | Restore denotes that the table was restored to a particular savepoint. |
| clean | Management activity that cleans up versions of data files that no longer will be accessed |
| compaction | Management activity to optimize the storage for query performance. This action applies the batched up updates from deltacommit and re-optimizes data files for query performance |
| replacecommit | Management activity to replace a set of data files atomically with another. It can be used to cluster the data for better query performance. This action is different from a commit in that the table state before and after are logically equivalent |
| indexing | Management activity to update the index with the data. This action does not change data, only updates the index aynchronously to data changes |
Action state: Denotes the state transition identifier (requested -> inflight -> completed)
Meta-files with requested transaction state contain any planning details, If an action requires generating a plan of execution, this is done before requesting and is persisted in the Meta-file. The data is serialized as Json/Avro, and the schema for each of these actions are as follows
replacecommit- HoodieRequestedReplaceMetadatarestore- HoodieRestorePlanrollback- HoodieRollbackPlanclean- HoodieCleanerPlanindexing- HoodieIndexPlan
Meta-files with completed transaction state contain details about the transaction completed such as the number of inserts/updates/deletes per file ID, file size, and some extra metadata such as checkpoint and schema for the batch of records written. Similar to the requested action state, the data is serialized as Json/Avro, and the schema as follows
commit- HoodieCommitMetadatadeltacommit- HoodieCommitMetadatarollback- HoodieRollbackMetadatasavepoint- HoodieSavepointMetadatarestore- HoodieRestoreMetadataclean- HoodieCleanMetadatacompaction- HoodieCompactionMetadatareplacecommit- HoodieReplaceCommitMetadataindexing- HoodieIndexCommitMetadata
By reconciling all the actions in the timeline, the state of the Hudi table can be re-created as of any instant of time.
Metadata
Hudi automatically extracts the physical data statistics and stores the metadata along with the data to improve write and query performance. Hudi Metadata is an internally-managed table which organizes the table metadata under the base path .hoodie/metadata. The metadata is in itself a Hudi table, organized with the Hudi merge-on-read storage format. Every record stored in the metadata table is a Hudi record and hence has partitioning key and record key specified.
Apache Hudi platform employs HFile format, to store metadata and indexes, to ensure high performance, though different implementations are free to choose their own. Following are the metadata table partitions :-
- files - Partition path to file name index. Key for the Hudi record is the partition path and the actual record is a map of file name to an instance of HoodieMetadataFileInfo (Refer the schema below). The files index can be used to do file listing and do filter based pruning of the scanset during query.
| Schema | Field Name | Data Type | Description |
|---|---|---|---|
| HoodieMetadataFileInfo | size | long | size of the file |
isDeleted | boolean | whether file has been deleted |
- bloom_filters - Bloom filter index to help map a record key to the actual file. The Hudi key is
str_concat(hash(partition name), hash(file name))and the actual payload is an instance of HudiMetadataBloomFilter (Refer the schema below). Bloom filter is used to accelerate 'presence checks' validating whether particular record is present in the file, which is used during merging, hash-based joins, point-lookup queries, etc.
| Schema | Field Name | Data Type | Description |
|---|---|---|---|
| HudiMetadataBloomFilter | size | long | size of the file |
type | string | type code of the bloom filter | |
timestamp | string | timestamp when the bloom filter was created/updated | |
bloomFilter | bytes | the actual bloom filter for the data file | |
isDeleted | boolean | whether the bloom filter entry is valid |
- column_stats - contains statistics of columns for all the records in the table. This enables fine-grained file pruning for filters and join conditions in the query. The actual payload is an instance of HoodieMetadataColumnStats (Refer the schema below).
| Schema | Field Name | Data Type | Description |
|---|---|---|---|
| HoodieMetadataColumnStats | fileName | string | file name to which the column stat applies |
columnName | string | column name to which the column stat applies | |
minValue | Wrapper type (based on data schema) | minimum value of the column in the file | |
maxValue | Wrapper type (based on data schema) | maximum value of the column in the file | |
valueCount | long | total count of values | |
nullCount | long | total count of null values | |
totalSize | long | total storage size on disk | |
totalUncompressedSize | long | total uncompressed storage size on disk | |
isDeleted | boolean | whether the column stat entry is valid |
Notes:
-
By default, all top-level fields are indexed for column stats.
-
When a top-level field is nested, it won't be indexed by default. Dot-notation will be recognized for indexing sub-fields via manual configuration, e.g.,
set hoodie.metadata.index.column.stats.column.list=foo.a.b,foo.c -
record_index - contains information about record keys and their location in the dataset. This improves performance of updates since it provides file locations for the updated records and also enables fine grained file pruning for filters and join conditions in the query. The payload is an instance of HoodieRecordIndexInfo (Refer the schema below).
| Schema | Field Name | Data Type | Description |
|---|---|---|---|
| HoodieRecordIndexInfo | partitionName | string | partition name to which the record belongs |
fileIdEncoding | int | determines the fields used to deduce file id. When the encoding is 0, file Id can be deduced from fileIdLowBits, fileIdHighBits and fileIndex. When encoding is 1, file Id is available in raw string format in fileId field | |
fileId | string | file id in raw string format is available when encoding is set to 1 | |
fileIdHighBits | long | file Id can be deduced as {UUID}-{fileIndex} when encoding is set to 0. fileIdHighBits and fileIdLowBits form the UUID | |
fileIdLowBits | long | file Id can be deduced as {UUID}-{fileIndex} when encoding is set to 0. fileIdHighBits and fileIdLowBits form the UUID | |
fileIndex | int | file Id can be deduced as {UUID}-{fileIndex} when encoding is set to 0. fileIdHighBits and fileIdLowBits form the UUID | |
instantTime | long | Epoch time in millisecond representing the commit time at which record was added |
File Layout Hierarchy
As mentioned in the data model, data is partitioned coarsely through a directory hierarchy based on the partition path configured. Within each partition the data is physically stored as base and log files and organized into logical concepts as File groups and File slices. These logical concepts will be referred to by the writer / reader requirements.
File group - Groups multiple versions of a base file. File group is uniquely identified by a File id. Each version corresponds to the commit's timestamp recording updates to records in the file. The base files are stored in open source data formats like Apache Parquet, Apache ORC, Apache HBase HFile etc.
File slice - A File group can further be split into multiple slices. Each file slice within the file-group is uniquely identified by commit's timestamp that created it. In case of COW, file-slice is simply just another version of the base-file. In case of MOR it's a combination of the base-file along with log-files attached to it. Each log-file corresponds to the delta commit in the timeline.
Base file
The base file name format is:
[File Id]_[File Write Token]_[Transaction timestamp].[File Extension]
- File Id - Uniquely identify a base file within the table. Multiple versions of the base file share the same file id.
- File Write Token - Monotonically increasing token for every attempt to write the base file. This should help uniquely identifying the base file when there are failures and retries. Cleaning can remove partial/uncommitted base files if the write token is not the latest in the file group
- Commit timestamp - Timestamp matching the commit instant in the timeline that created this base file
- File Extension - base file extension to denote the open source file format such as .parquet, .orc
Log File Format
The log file name format is:
[File Id]_[Base Transaction timestamp].[Log File Extension].[Log File Version]_[File Write Token]
- File Id - File Id of the base file in the slice
- Base Transaction timestamp - Commit timestamp on the base file for which the log file is updating the deletes/updates for
- Log File Extension - Extension defines the format used for the log file (e.g. Hudi proprietary log format)
- Log File Version - Current version of the log file format
- File Write Token - Monotonically increasing token for every attempt to write the log file. This should help uniquely identifying the log file when there are failures and retries. Cleaner can clean-up partial log files if the write token is not the latest in the file slice.
The Log file format structure is a Hudi native format. The actual content bytes are serialized into one of Apache Avro, Apache Parquet or Apache HFile file formats based on configuration and the other metadata in the block is serialized using primitive types and byte arrays.
Hudi Log format specification is as follows.
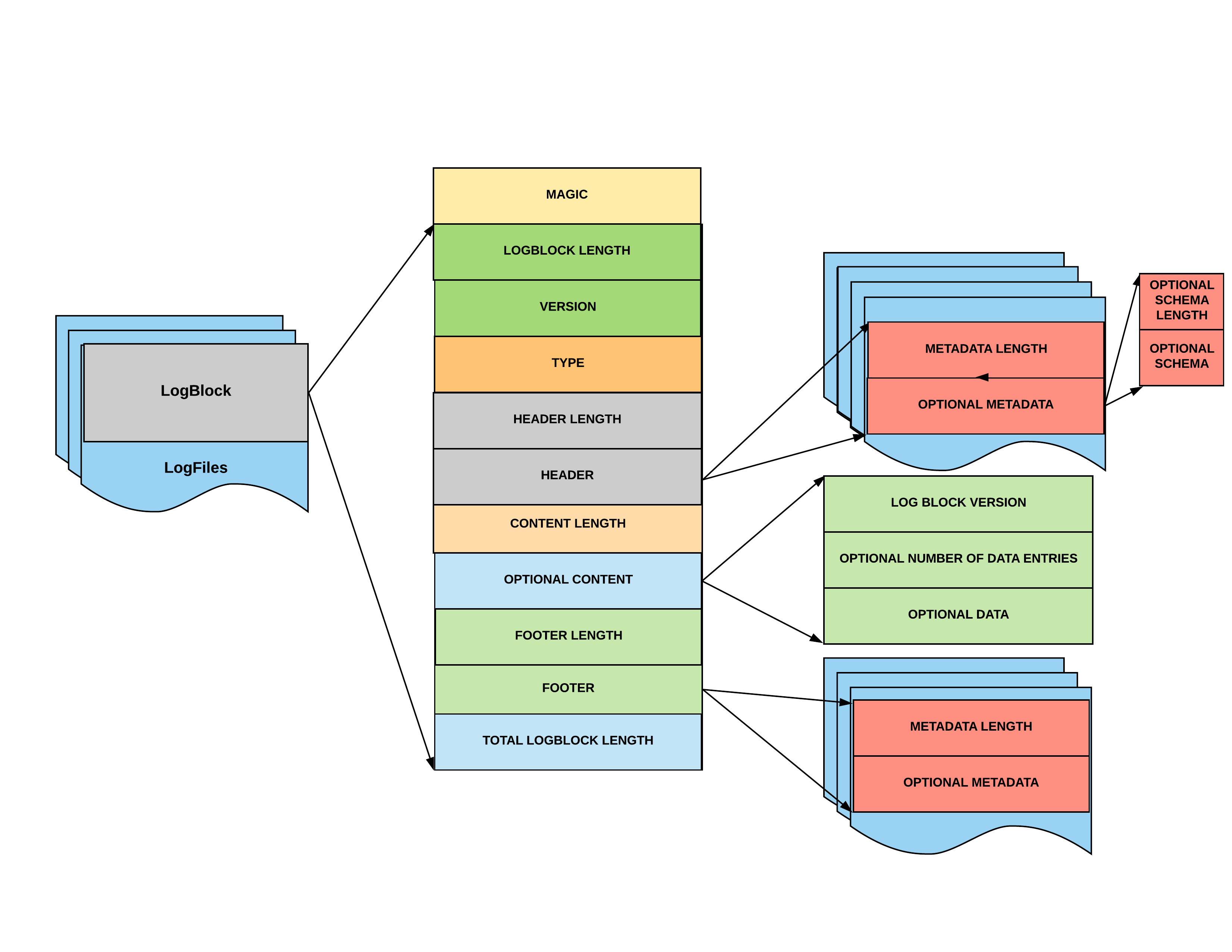
| Section | #Bytes | Description |
|---|---|---|
| magic | 6 | 6 Characters '#HUDI#' stored as a byte array. Sanity check for block corruption to assert start 6 bytes matches the magic byte[]. |
| LogBlock length | 8 | Length of the block excluding the magic. |
| version | 4 | Version of the Log file format, monotonically increasing to support backwards compatibility |
| type | 4 | Represents the type of the log block. Id of the type is serialized as an Integer. |
| header length | 8 | Length of the header section to follow |
| header | variable | Custom serialized map of header metadata entries. 4 bytes of map size that denotes number of entries, then for each entry 4 bytes of metadata type, followed by length/bytearray of variable length utf-8 string. |
| content length | 8 | Length of the actual content serialized |
| content | variable | The content contains the serialized records in one of the supported file formats (Apache Avro, Apache Parquet or Apache HFile) |
| footer length | 8 | Length of the footer section to follow |
| footer | variable | Similar to Header. Map of footer metadata entries. |
| total block length | 8 | Total size of the block including the magic bytes. This is used to determine if a block is corrupt by comparing to the block size in the header. Each log block assumes that the block size will be last data written in a block. Any data if written after is just ignored. |
Metadata key mapping from Integer to actual metadata is as follows
- Instant Time (encoding id: 1)
- Target Instant Time (encoding id: 2)
- Command Block Type (encoding id: 3)
Log file format block types
The following are the possible block types used in Hudi Log Format:
Command Block (Id: 1)
Encodes a command to the log reader. The Command block must be 0 byte content block which only populates the metadata Command Block Type. Only possible values in the current version of the log format is ROLLBACK_PREVIOUS_BLOCK, which lets the reader to undo the previous block written in the log file. This denotes that the previous action that wrote the log block was unsuccessful.
Delete Block (Id: 2)

| Section | #bytes | Description |
|---|---|---|
| format version | 4 | version of the log file format |
| length | 8 | length of the deleted keys section to follow |
| deleted keys | variable | Tombstone of the record to encode a delete. The following 3 fields are serialized using the KryoSerializer. Record Key - Unique record key within the partition to deleted Partition Path - Partition path of the record deleted Ordering Value - In a particular batch of updates, the delete block is always written after the data (Avro/HFile/Parquet) block. This field would preserve the ordering of deletes and inserts within the same batch. |
Corrupted Block (Id: 3)
This block type is never written to persistent storage. While reading a log block, if the block is corrupted, then the reader gets an instance of the Corrupted Block instead of a Data block.
Avro Block (Id: 4)
Data block serializes the actual records written into the log file

| Section | #bytes | Description |
|---|---|---|
| format version | 4 | version of the log file format |
| record count | 4 | total number of records in this block |
| record length | 8 | length of the record content to follow |
| record content | variable | Record represented as an Avro record serialized using BinaryEncoder |
HFile Block (Id: 5)
The HFile data block serializes the records using the HFile file format. HFile data model is a key value pair and both are encoded as byte arrays. Hudi record key is encoded as Avro string and the Avro record serialized using BinaryEncoder is stored as the value. HFile file format stores the records in sorted order and with index to enable quick point reads and range scans.
Parquet Block (Id: 6)
The Parquet Block serializes the records using the Apache Parquet file format. The serialization layout is similar to the Avro block except for the byte array content encoded in columnar Parquet format. This log block type enables efficient columnar scans and better compression.
Different data block types offers different trade-offs and picking the right block is based on the workload requirements and is critical for merge and read performance.
Reader Expectations
Readers will use snapshot isolation to query a Hudi table at a consistent point in time in the Hudi timeline. The reader constructs the snapshot state using the following steps
- Pick an instant in the timeline (last successful commit or a specific commit version explicitly queried) and set that the commit time to compute the list of files to read from.
- For the picked commit time, compute all the file slices that belong to that specific commit time. For all the partition paths involved in the query, the file slices that belong to a successful commit before the picked commit should be included. The lookup on the filesystem could be slow and inefficient and can be further optimized by caching in memory or using the files (mapping partition path to filenames) index or with the support of an external timeline serving system.
- For the MoR table type, ensure the appropriate merging rules are applied to apply the updates queued for the base in the log files.
- Contents of the log files should be loaded into an effective point lookup data structure (in-memory or persisted)
- Duplicate record keys should be merged based on the ordering field specified. It is important to order the inserts and deletes in the right order to be consistent and idempotent.
- When the base file is scanned, for every record block, the reader has to lookup if there is a newer version of the data available for the record keys in the block and merge them into the record iterator.
- In addition, all the "replacecommit" metadata needs to read to filter out flle groups, that have been replaced with newer file groups, by actions like clustering.
Writer Expectations�
Writer into Hudi will have to ingest new records, updates to existing records or delete records into the table. All transactional actions follow the same state transition as described in the transaction log (timeline) section. Writers will optimistically create new base and log files and will finally transition the action state to completed to register all the modifications to the table atomically. Writer merges the data using the following steps
- Writer will pick a monotonically increasing instant time from the latest state of the Hudi timeline (action commit time) and will pick the last successful commit instant (merge commit time) to merge the changes to. If the merge succeeds, then action commit time will be the next successful commit in the timeline.
- For all the incoming records, the writer will have to efficiently determine if this is an update or insert. This is done by a process called tagging - which is a batched point lookups of the record key and partition path pairs in the entire table. The efficiency of tagging is critical to the merge performance. This can be optimized with indexes (bloom, global key value based index) and caching. New records will not have a tag.
- Once records are tagged, the writer can apply them onto the specific file slice.
- For CoW, writer will create a new slice (action commit time) of the base file in the file group
- For MoR, writer will create a new log file with the action commit time on the merge commit time file slice
- Deletes are encoded as special form of updates where only the meta fields and the operation is populated. See the delete block type in log format block types.
- Once all the writes into the file system are complete, concurrency control checks happen to ensure there are no overlapping writes and if that succeeds, the commit action is completed in the timeline atomically making the changes merged visible for the next reader.
- Synchronizing Indexes and metadata needs to be done in the same transaction that commits the modifications to the table.
Compatibility
Compatibility between different readers and writers is enforced through the hoodie.table.version table config. Hudi storage format evolves in a backwards compatible way for readers, where newer readers
can read older table versions correctly. However older readers may be required to upgrade in order to read higher table versions. Hence, we recommend upgrading readers first, before upgrading writers when
the table version evolves.
Balancing write and query performance
A critical design choice for any table is to pick the right trade-offs in the data freshness and query performance spectrum. Hudi storage format lets the users decide on this trade-off by picking the table type, record merging and file sizing.
Table types
| Merge Efficiency | Query Efficiency | |
|---|---|---|
| Copy on Write (COW) | Tunable COW table type creates a new File slice in the file-group for every batch of updates. Write amplification can be quite high when the update is spread across multiple file groups. The cost involved can be high over a time period especially on tables with low data latency requirements. | Optimal COW table types create whole readable data files in open source columnar file formats on each merge batch, there is minimal overhead per record in the query engine. Query engines are fairly optimized for accessing files directly in cloud storage. |
| Merge on Read (MOR) | Optimal MOR table type batches the updates to the file slice in a separate optimized Log file, write amplification is amortized over time when sufficient updates are batched. The merge cost involved will be lower than COW since the churn on the records re-written for every update is much lower. | Tunable MOR Table type required record level merging during query. Although there are techniques to make this merge as efficient as possible, there is still a record level overhead to apply the updates batched up for the file slice. The merge cost applies on every query until the compaction applies the updates and creates a new file slice. |
Interesting observation on the MOR table format is that, by providing a special view of the table which only serves the base files in the file slice (read optimized query of MOR table), query can pick between query efficiency and data freshness dynamically during query time. Compaction frequency determines the data freshness of the read optimized view. With this, the MOR has all the levers required to balance the merge and query performance dynamically.
Record merging
Hudi data model ensures record key uniqueness constraint, to maintain this constraint every single record merged into the table needs to be checked if the same record key already exists in the table. If it does exist, the conflict resolution strategy is applied to create a new merged record to be persisted. This check is done at the file group level and every record merged needs to be tagged to a single file group. By default, record merging is done during the merge which makes it efficient for queries but for certain real-time streaming requirements, it can also be deferred to the query as long as there is a consistent way to mapping the record key to a certain file group using consistent hashing techniques.
File sizing
Sizing the file group is extremely critical to balance the merge and query performance. Larger the file size, the more the write amplification when new file slices are being created. So to balance the merge cost, compaction or merge frequency should be tuned accordingly and this has an impact on the query performance or data freshness.
Table Management
All table services can be run synchronous with the Table client that merges modifications to the data or can be run asynchronously to the table client. Asynchronous is default mode in the Apache Hudi platform. Any client can trigger table management by registering a 'requested' state action in the Hudi timeline. Process in charge of running the table management tasks asynchronously looks for the presence of this trigger in the timeline.
Compaction
Compaction is the process that efficiently updates a file slice (base and log files) for efficient querying. It applies all the batched up updates in the log files and writes a new file slice. The logic to apply the updates to the base file follows the same set of rules listed in the Reader expectations.
Clustering
If the natural ingestion ordering does not match the query patterns, then data skipping does not work efficiently. It is important for query efficiency to be able to skip as much data on filter and join predicates with column level statistics. Clustering columns need to be specified on the Hudi table. The goal of the clustering table service, is to group data often accessed together and consolidate small files to the optimum target file size for the table.
- Identify file groups that are eligible for clustering - this is chosen based on the clustering strategy (file size based, time based etc)
- Identify clustering groups (file groups that should be clustered together) and each group should expect data sizes in multiples of the target file size.
- Persist the clustering plan in the Hudi timeline as a replacecommit, when clustering is requested.
- Clustering execution can then read the individual clustering groups, write back new file groups with target size with base files sorted by the specified clustering columns.
Cleaning
Cleaning is a process to free up storage space. Apache Hudi maintains a timeline and multiple versions of the files written as file slices. It is important to specify a cleaning protocol which deletes older versions and reclaims the storage space. Cleaner cannot delete versions that are currently in use or will be required in future. Snapshot reconstruction on a commit instant which has been cleaned is not possible.
For e.g, there are a couple of retention policies supported in Apache Hudi platform
- keep_latest_commits: This is a temporal cleaning policy that ensures the effect of having look-back into all the changes that happened in the last X commits.
- keep_latest_file_versions: This policy has the effect of keeping a maximum of N number of file versions irrespective of time.
Apache Hudi provides snapshot isolation between writers and readers by managing multiple files with MVCC concurrency. These file versions provide history and enable time travel and rollbacks, but it is important to manage how much history you keep to balance your storage costs.
Concurrency Control
Apache Hudi storage format enables transactional consistencies for reads and writes.
Multiple concurrent readers
Hudi storage format supports snapshot isolation for concurrent readers. A reader loads the Hudi timeline and picks the latest commit and constructs the snapshot state as of the picked commit. Two concurrent readers are never in contention even in the presence of concurrent writes happening.
Concurrency control with writes
If there are only inserts to the table, then there will be no conflicts. To better illustrate scenarios with update conflicts, let's categorize writers are 2 types.
- a Table write client merges new changes to the table, from external sources or as output another computation.
- a Table service client does table management services like clustering, compaction, and cleaning et which does not logically change the state of the table.
Let us look at the various write conflict scenarios
Multiple table write client conflicts
Conflicts can occur if two or more writers update the same file group and in that case the first transaction to commit succeeds while the rest will need to be aborted and all changes cleaned up. To be able to detect concurrent updates to the same file group, external locking has to be configured. Conflict detection can be optimistic or pessimistic.
-
Under optimistic locking, the table writer makes all new base and log files and before committing the transaction, a table level lock is acquired and if there is a newer slice (version) on any of the file groups modified by the current transaction, the transaction has conflicts and needs to be retried. This works well for highly concurrent unrelated updates. Bulk changes to the tables may starve in the presence of multiple concurrent smaller updates.
-
Table clients can also hold pessimistic locks on all the file id groups before they write any new data. They will be required to hold on to the file id locks until the transaction commits. This is not a good fit for highly concurrent workloads, as lock contention may be prohibitively high. Optimistic locking works better for these scenarios.
It is also worth noting that, if multiple writers originate from the same JVM client, a simple locking at the client level would serialize the writes and no external locking needs to be configured.
Apache Hudi platform uses optimistic locking and provides a pluggable LockProvider interface and multiple implementations are available out of the box (Apache Zookeeper, DynamoDB, Apache Hive and JVM Level in-process lock).
Table service client and Table write client conflicts
Concurrent updates to the same file group between the Table client and Table Service client can be managed with some additional complexity without the need for external locking. The table service client will be creating a new file slice within the file group and the table client will be creating a new log entry on the current file slice in the file group. Since Hudi maintains a strict ordering of operations in the timeline, When reading a file group, Hudi reader can reconcile all the changes to the previous file slice that are not part of the current file slice.
Multiple Table service client conflicts
Since Table service client commits are not opaque modifications to the table, concurrency control can be more efficient and intelligent. Concurrent updates to the same file group can be detected early and conflicting table service clients can be aborted. Planning table service actions need to be serialized by short-lived locks.
Optimistic concurrency efficiency
The efficiency of Optimistic concurrency is inversely proportional to the possibility of a conflict, which in turn depends on the running time and the files overlapping between the concurrent writers. Apache Hudi storage format makes design choices that make it possible to configure the system to have a low possibility of conflict with regular workloads
- All records with the same record key are present in a single file group. In other words, there is a 1-1 mapping between a record key and a file group id, at all times.
- Unit of concurrency is a single file group and this file group size is configurable. If the table needs to be optimized for concurrent updates, the file group size can be smaller than default which could mean lower collision rates.
- Merge-on-read storage engine has the option to store the contents in record oriented file formats which reduces write latencies (often up to 10 times compared to columnar storage) which results in less collision with other concurrent writers
- Merge-on-read storage engine combined with scalable metadata table ensures that the system can handle frequent updates efficiently which means ingest jobs can be frequent and quick, reducing the chance of conflicts