
184 posts tagged with "Apache Hudi"
View All Tags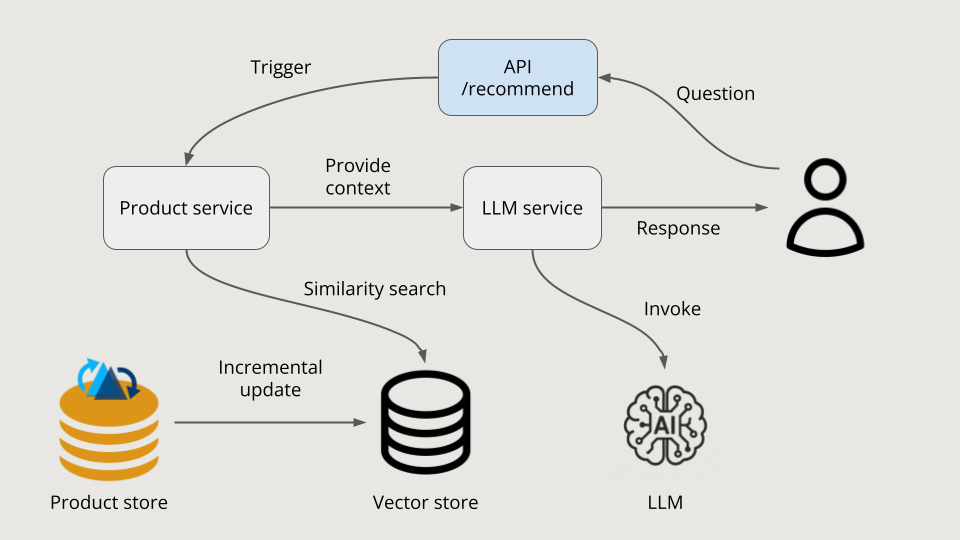
Building a RAG-based AI Recommender (2/2)
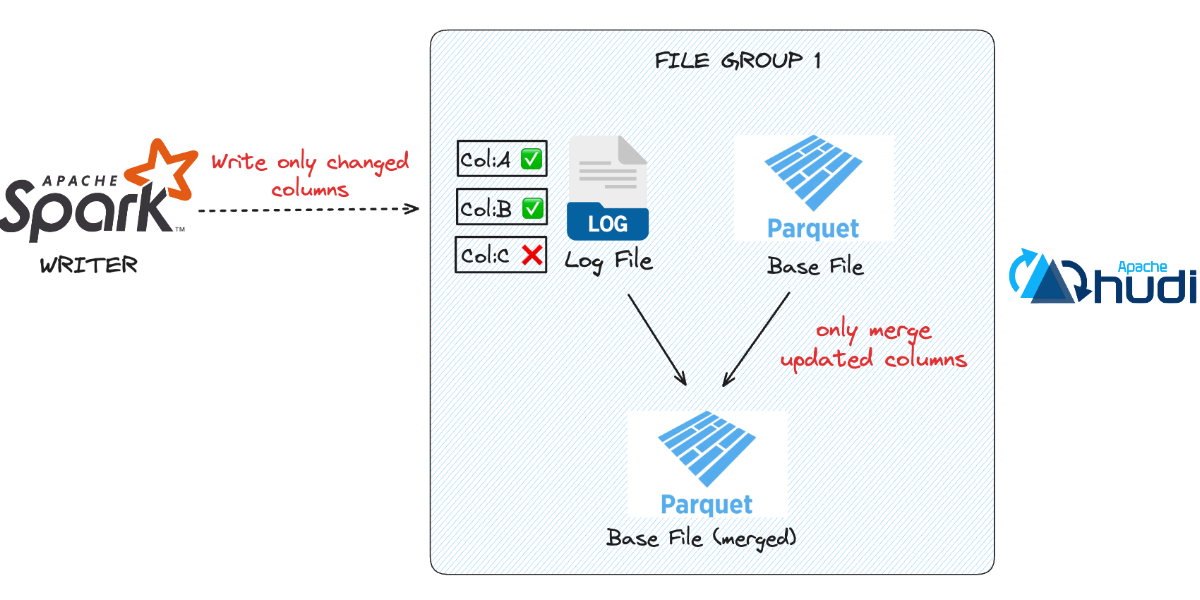
A Deep Dive on Merge-on-Read (MoR) in Lakehouse Table Formats
Modernizing Data Infrastructure at Peloton Using Apache Hudi
How PayU built a secure enterprise AI assistant using Amazon Bedrock
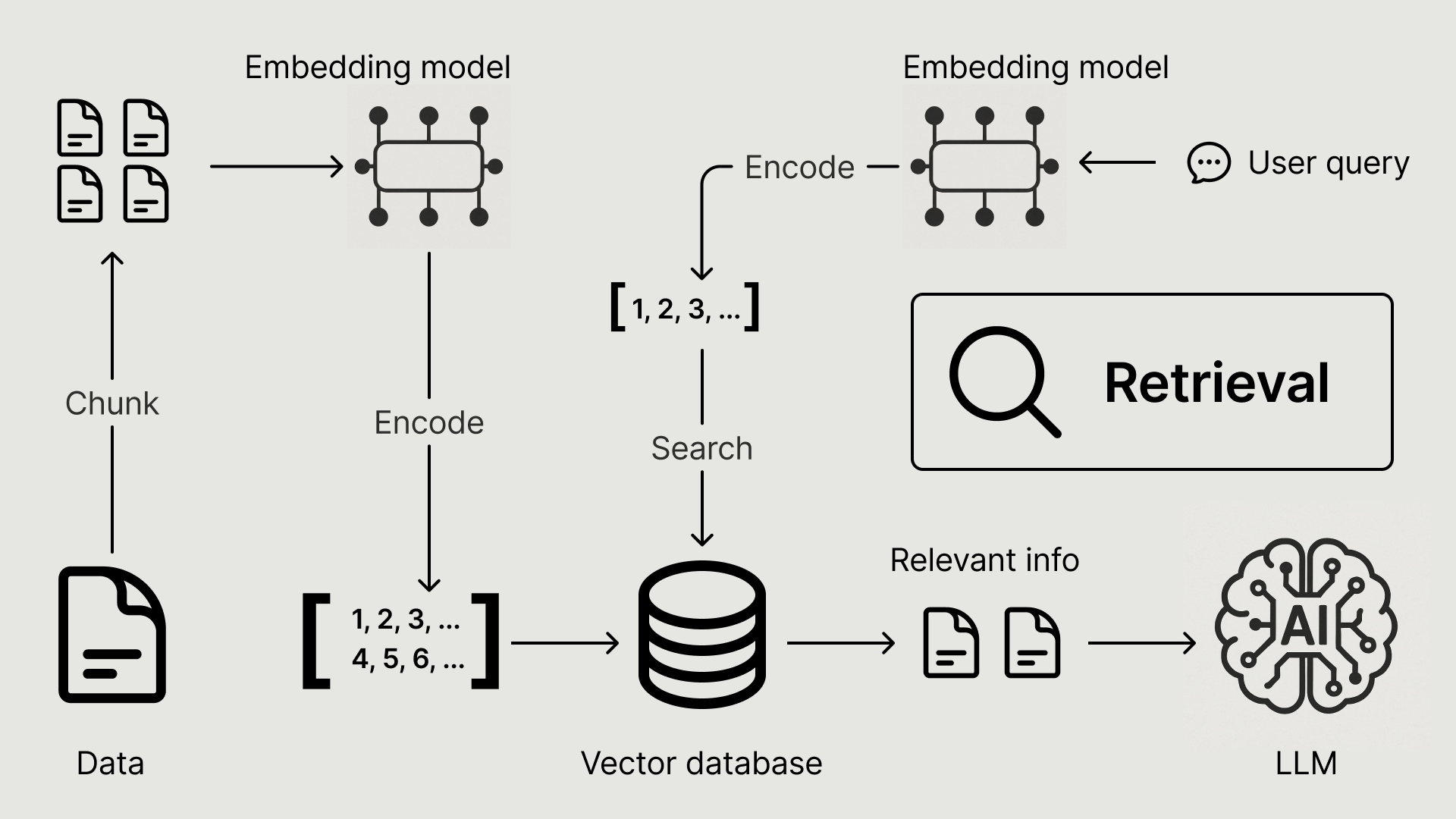
Building a RAG-based AI Recommender (Part 1/2)
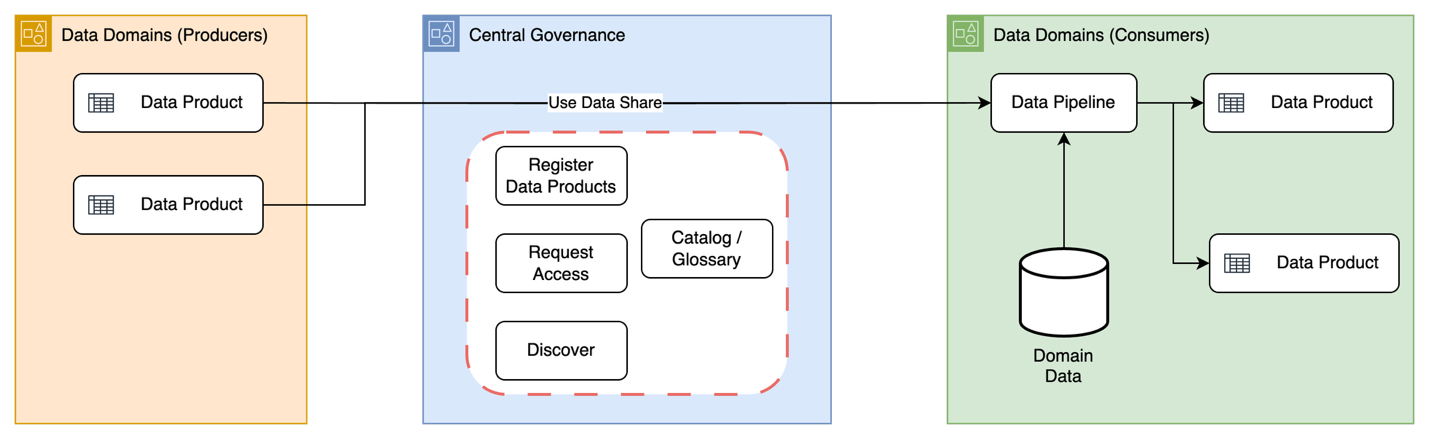
How Stifel built a modern data platform using AWS Glue and an event-driven domain architecture

Why Uber Built Hudi: The Strategic Decision Behind a Custom Table Format

Lakehouse Architecture - Apache Hudi and Apache Iceberg

Scaling Complex Data Workflows at Uber Using Apache Hudi

Apache Hudi does XYZ (1/10): File pruning with multi-modal index
