Apache Hudi vs. Delta Lake: Choosing the Right Tool for Your Data Lake on AWSMay 27, 2024 by Siladitya Ghoshdelta lakecomparison
Use AWS Data Exchange to seamlessly share Apache Hudi datasetsMay 22, 2024 by Saurabh Bhutyani, Ankith Ede, and Chandra Krishnandata sharingaws
Building Analytical Apps on the Lakehouse using Apache Hudi, Daft & StreamlitMay 10, 2024 by Dipankar Mazumdarpythondaftstreamlitdata lakehouse
Learn how to read Hudi data with AWS Glue Ray using Daft (No Spark)May 7, 2024 by Soumil Shahawsraydaft
How to Query Apache Hudi Tables with Python Using Daft: A Spark-Free ApproachMay 2, 2024 by Soumil Shahpythondaft
Apache Hudi vs Apache Iceberg: A Comprehensive ComparisonApril 25, 2024 by RisingWave marketing teamapache icebergcomparisonrisingwave
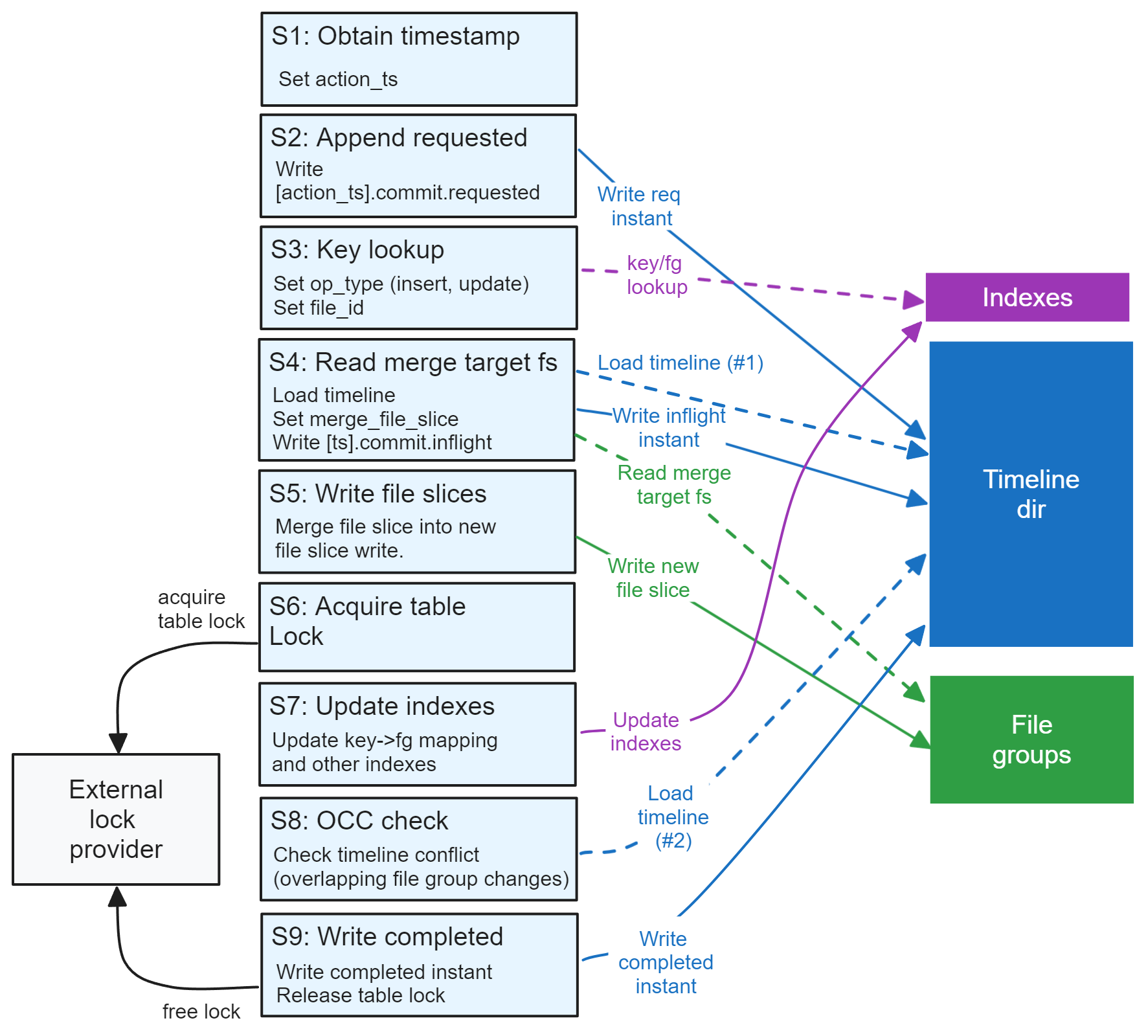
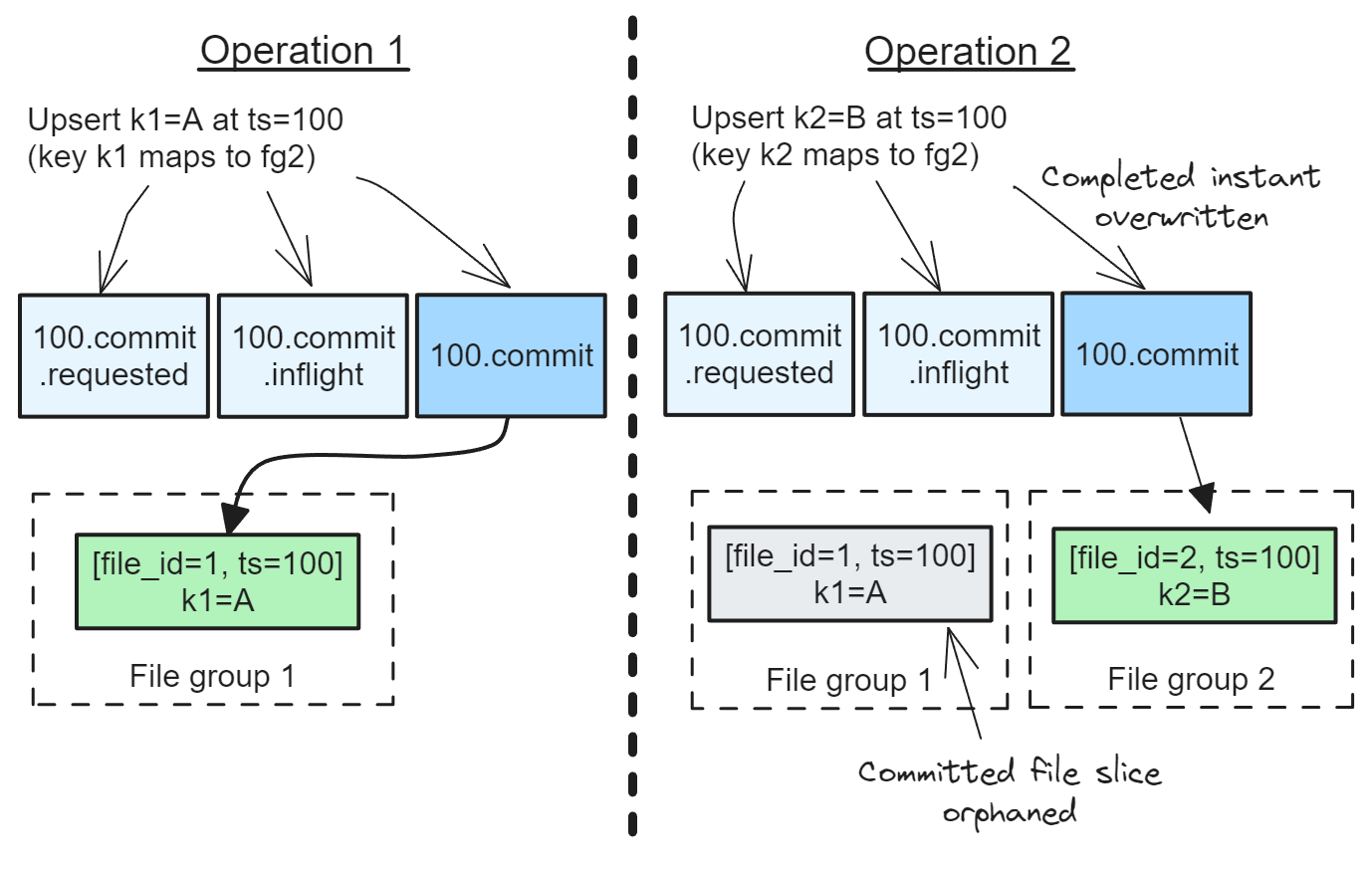
Understanding Apache Hudi's Consistency Model Part 1April 24, 2024 by Jack Vanlightlytable formatacidcowconcurrency controltla specification
Understanding Apache Hudi's Consistency Model Part 2April 24, 2024 by Jack Vanlightlyacidconcurrency control
Understanding Apache Hudi's Consistency Model Part 3April 24, 2024 by Jack Vanlightlytla specificationacidconcurrency control