Timeline
Changes to table state (writes, table services, schema changes, etc) are recorded as actions in the Hudi timeline. The Hudi timeline is a log of all actions performed on the table at different instants (points in time). It is a key component of Hudi's architecture, acting as a source of truth for the state of the table. All instant times used on the timeline follow TrueTime semantics, and are monotonically increasing globally across various processes involved. See TrueTime section below for more details.
Each action has the following attributes associated with it.
- requested instant : Instant time representing when the action was requested on the timeline and acts as the transaction id. An immutable plan for the action should be generated before the action is requested.
- completed instant : Instant time representing when the action was completed on the timeline. All relevant changes to table data/metadata should be made before the action is completed.
- state : state of the action. valid states are
REQUESTED,INFLIGHTandCOMPLETEDduring an action's lifecycle. - type : the kind of action performed. See below for full list of actions.
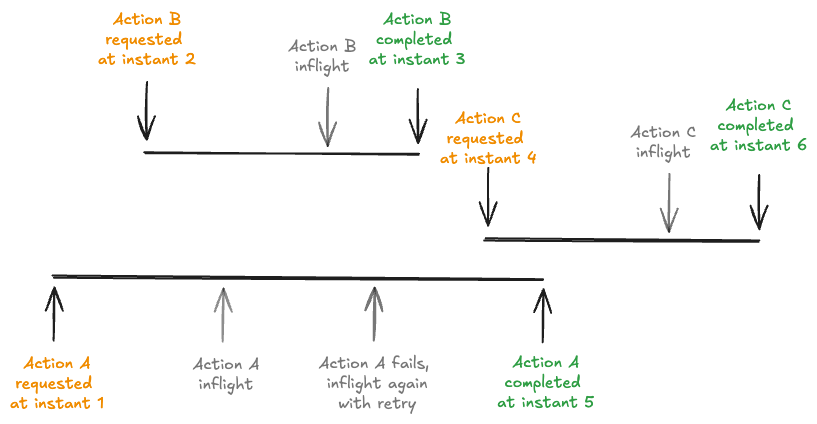
Figure: Actions in the timeline
Action Types
Following are the valid action types.
- COMMIT - Write operation denoting an atomic write of a batch of records into a base files in the table.
- DELTA_COMMIT - Write operation denoting an atomic write of a batch of records into merge-on-read type table, where some/all of the data could be just written to delta logs.
- REPLACE_COMMIT - Write operation that atomically replaces a set of file groups in the table with another. Used for implementing batch write operations like insert_overwrite, delete_partition etc, as well as table services like clustering.
- CLEANS - Table service that removes older file slices that are no longer needed from the table, by deleting those files.
- COMPACTION - Table service to reconcile differential data between base and delta files, by merging delta files into base files.
- LOGCOMPACTION - Table service to merge multiple small log files into a bigger log file in the same file slice.
- CLUSTERING - Table service to rewrite existing file groups with optimized sort order or storage layouts, as new file groups in the table.
- INDEXING - Table service to build an index of a requested type on a column of the table, consistent with the state of the table at the completed instant in face of ongoing writes.
- ROLLBACK - Indicates that an unsuccessful write operation was rolled back, removing any partial/uncommitted files produced during such a write from storage.
- SAVEPOINT - Marks certain file slices as "saved", such that cleaner will not delete them. It helps restore the table to a point on the timeline, in case of disaster/data recovery scenarios or perform time-travel queries as of those instants.
- RESTORE - Restores a table to a given savepoint on the timeline, in case of disaster/data recovery scenarios.
In some cases, action types in the completed state may be different from requested/inflight states, but still tracked by the same requested instant. For e.g. CLUSTERING as in requested/inflight state, becomes REPLACE_COMMIT in completed state. Compactions complete as COMMIT action on the timeline producing new base files. In general, multiple write operations from the storage engine may map to the same action on the timeline.
State Transitions
Actions go through state transitions on the timeline, with each transition recorded by a file of the pattern <requested instant>.<action>.<state>(for other states) or
<requested instant>_<completed instant>.<action> (for COMPLETED state). Hudi guarantees that the state transitions are atomic and timeline consistent based on the instant time.
Atomicity is achieved by relying on the atomic operations on the underlying storage (e.g. PUT calls to S3/Cloud Storage).
Valid state transitions are as follows:
[ ] -> REQUESTED- Denotes an action has been scheduled, but has not initiated by any process yet. Note that the process requesting the action can be different from the process that will perform/complete the action.REQUESTED -> INFLIGHT- Denotes that the action is currently being performed by some process.INFLIGHT -> REQUESTEDorINFLIGHT -> INFLIGHT- A process can safely fail many times while performing the action.INFLIGHT -> COMPLETED- Denotes that the action has been completed successfully.
The current state of an action on the timeline is the highest state recorded for that action on the timeline, with states ordered as REQUESTED < INFLIGHT < COMPLETED.
TrueTime Generation
Time in distributed systems has been studied literally for decades. Google Spanner’s TrueTime API addresses the challenges of managing time in distributed systems by providing a globally synchronized clock with bounded uncertainty. Traditional systems struggle with clock drift and lack of a consistent timeline, but TrueTime ensures that all nodes operate with a common notion of time, defined by a strict interval of uncertainty. This enables Spanner to achieve external consistency in distributed transactions, allowing it to assign timestamps with confidence that no other operation in the past or future will conflict, solving age-old issues of clock synchronization and causality. Several OLTP databases like Spanner, CockroachDB rely on TrueTime.
Hudi uses these semantics for instant times on the timeline, to provide unique monotonically increasing instant values. TrueTime can be generated by a single shared time generator process or by having each process generate its own time and waiting for time >= maximum expected clock drift across all processes within a distributed lock. Locking ensures only one process is generating time at a time and waiting ensures enough time passes such that any new time generated is guaranteed to be greater than the previous time.
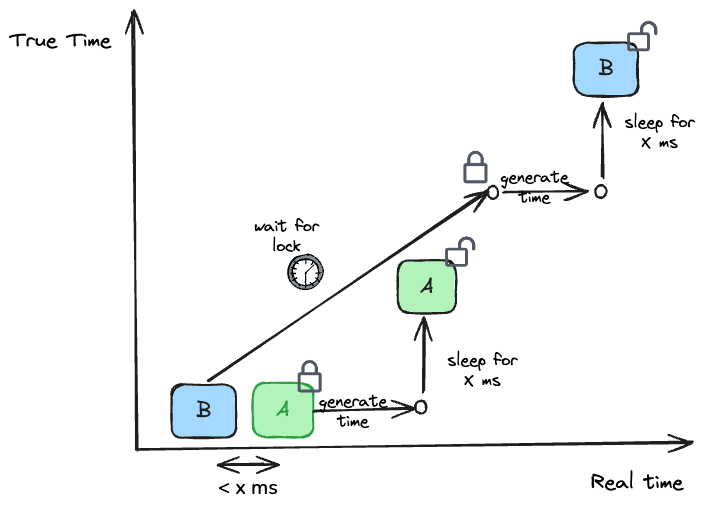
Figure: TrueTime generation for processes A & B
The figure above shows how time generated by process A and B are monotonically increasing, even though process B has a lower local clock than A at the start, by waiting for uncertainty window of x ms to pass.
In fact, given Hudi targets transaction durations > 1 second, we can afford to operate with a much higher uncertainty bound (> 100ms) guaranteeing extremely high fidelity time generation.
Ordering of Actions
Thus, actions appear on the timeline as an interval starting at the requested instant and ending at the completed instant. Such actions can be ordered by completion time to
- Commit time ordering : To obtain serializable execution order of writes performed consistent with typical relational databases, the actions can be ordered by completed instant.
- Event time ordering: Data lakehouses ultimately deal with streams of data (CDC, events, slowly changing data etc), where ordering is dependent on business fields in the data. In such cases, actions can be ordered by commit time, while the records themselves are further merged in order of a specified event time field.
Hudi relies on ordering of requested instants of certain actions against completed instants of other actions, to implement non-blocking table service operations or concurrent streaming model writes with event time ordering.
Timeline Components
Active Timeline
Hudi implements the timeline as a Log Structured Merge (LSM) tree under the .hoodie/timeline directory. Unlike typical LSM implementations,
the memory component and the write-ahead-log are at once replaced by avro serialized files containing individual actions (active timeline) for high durability and inter-process co-ordination.
All actions on the Hudi table are created in the active timeline a new entry and periodically actions are archived from the active timeline to the LSM structure (timeline history).
As the name suggests active timeline is consulted all the time to build a consistent view of data and archiving completed actions ensures reads on the timeline does not incur unnecessary latencies
as timeline grows. The key invariant around such archiving is that any side effects from completed/pending actions (e.g. uncommitted files) are removed from storage, before archiving them.
LSM Timeline History
As mentioned above, active timeline has limited log history to be fast, while archived timeline is expensive to access
during reads or writes, especially with high write throughput. To overcome this limitation, Hudi introduced the LSM (
log-structured merge) tree based timeline. Completed actions, their plans and completion metadata are stored in a more
scalable LSM tree based archived timeline organized in an history storage folder under the .hoodie/timeline metadata
path. It consists of Apache Parquet files with action instant data and bookkeeping metadata files, in the following
manner.
/.hoodie/timeline/history/
├── _version_ <-- stores the manifest version that is current
├── manifest_1 <-- manifests store list of files in timeline
├── manifest_2 <-- compactions, cleaning, writes produce new manifest files
├── ...
├── manifest_<N> <-- there can be many manifest files at any given time
├── <min_time>_<max_time>_<level>.parquet <-- files storing actual action details
One can read more about the details of LSM timeline in Hudi 1.0 specs. To understand it better, here is an example.
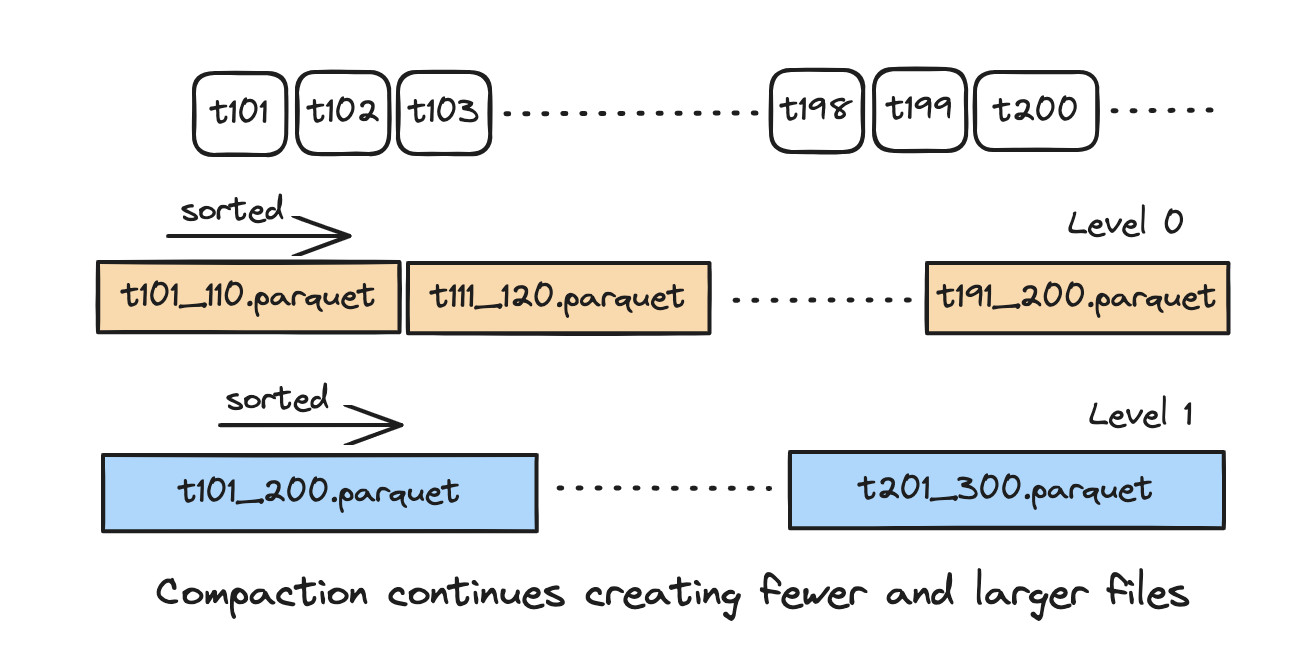
In the above figure, each level is a tree sorted by instant times. We can see that for a bunch of commits the metadata
is stored in a parquet file. As and when more commits are accumulated, they get compacted and pushed down to lower level
of the tree. Each new operation to the timeline yields a new snapshot version. The advantage of such a structure is that
we can keep the top level in memory if needed, and still load the remaining levels efficiently from the disk if we need to walk
back longer history. The LSM timeline compaction frequency is controlled byhoodie.timeline.compaction.batch.size i.e.
for every N parquet files in the current level, they are merged and flush as a compacted file in the next level.
Timeline Archival Configs
Basic configurations that control archival.
Spark configs
| Config Name | Default | Description |
|---|---|---|
| hoodie.keep.max.commits | 30 (Optional) | Archiving service moves older entries from timeline into an archived log after each write, to keep the metadata overhead constant, even as the table size grows. This config controls the maximum number of instants to retain in the active timeline. |
| hoodie.keep.min.commits | 20 (Optional) | Similar to hoodie.keep.max.commits, but controls the minimum number of instants to retain in the active timeline. |
| hoodie.timeline.compaction.batch.size | 10 (Optional) | Controls the number of parquet files to compact in a single compaction run at the current level of the LSM tree. |
For more advanced configs refer here.
Flink Options
Flink jobs using the SQL can be configured through the options in WITH clause. The actual datasource level configs are listed below.
| Config Name | Default | Description |
|---|---|---|
| archive.max_commits | 50 (Optional) | Max number of commits to keep before archiving older commits into a sequential log, default 50Config Param: ARCHIVE_MAX_COMMITS |
| archive.min_commits | 40 (Optional) | Min number of commits to keep before archiving older commits into a sequential log, default 40Config Param: ARCHIVE_MIN_COMMITS |
| hoodie.timeline.compaction.batch.size | 10 (Optional) | Controls the number of parquet files to compact in a single compaction run at the current level of the LSM tree. |
Refer here for more details.