Record Merger
Hudi handles mutations to records and streaming data as briefly touched upon in the timeline ordering section. To provide users with full-fledged support for stream processing, Hudi goes to great lengths to make the storage engine and the underlying storage format understand how to merge changes to the same record key, which may arrive in different orders at different times. With the rise of mobile applications and IoT, these scenarios have become the norm rather than an exception. For example, a social networking application may upload user events several hours after they occur when the user reconnects to Wi‑Fi.
Merge Modes
To address these challenges, Hudi supports merge modes, which define how the base and log files are ordered in a file slice and how different records with the same record key within that file slice are merged consistently to produce the same deterministic results for snapshot queries, writers, and table services.
The merge mode is a table-level configuration used in the following code paths:
-
(writing) Combining multiple change records for the same record key while reading input data during writes. This is an optional optimization that reduces the number of records written to log files to improve query and write performance subsequently.
-
(writing) Merging the final change record (partial/full update/delete) against the existing record in storage for COW tables.
-
(compaction) Compaction service merges all change records in log files against base files, respecting the merge mode.
-
(query) Merging change records in log files, after filtering and projections against the base file for MOR table queries.
There are three merge modes: COMMIT_TIME_ORDERING, EVENT_TIME_ORDERING, and CUSTOM. The default merge mode is automatically inferred based on whether any ordering field is configured. If you do not specify an ordering field (e.g., hoodie.table.ordering.fields), the merge mode defaults to COMMIT_TIME_ORDERING, which replaces the old record with the new one from the incoming batch. If you do specify one or more ordering fields, the merge mode defaults to EVENT_TIME_ORDERING, which compares records based on the ordering field values to handle out-of-order data.
You can explicitly configure the merge mode using the write config hoodie.write.record.merge.mode. When you create or write to a table with this config, it will be persisted to the table's configuration file (hoodie.properties) as hoodie.record.merge.mode. Once persisted, all subsequent reads and writes will use this merge mode unless explicitly overridden in the write config.
Merge mode is the way to choose and configure the record merger for your tables. For most use cases, you can choose COMMIT_TIME_ORDERING or EVENT_TIME_ORDERING by setting the appropriate ordering field(s) without any additional configuration or implementation. These modes provide standard merging behaviors that cover the majority of scenarios. For advanced use cases requiring custom merge logic, you can use the CUSTOM merge mode and implement the HoodieRecordMerger interface.
The merge mode should not be altered once a table is created to avoid inconsistent behavior due to compaction producing different merge results when switching between modes.
COMMIT_TIME_ORDERING
Here, we expect the input records to arrive in strict order such that arrival order matches their delta commit order on the table. Merging picks the record belonging to the latest write as the merged result. In relational data model terms, this provides overwrite semantics aligned with serializable writes on the timeline.
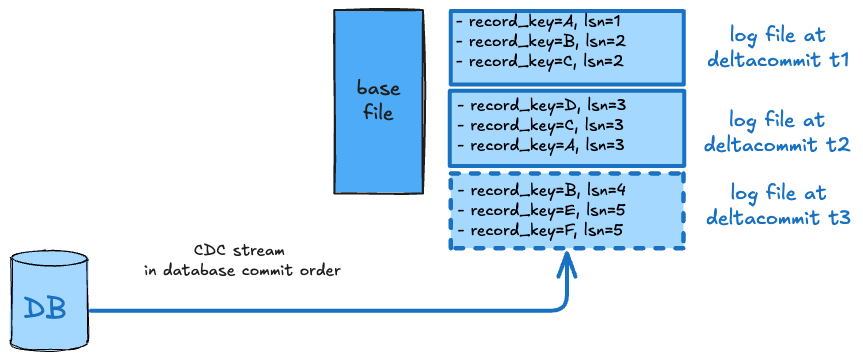
In the example above, the writer process consumes a database change log, expected to be in strict order of a logical sequence number (lsn) that denotes the ordering of the writes in the upstream database.
EVENT_TIME_ORDERING
This is the default merge mode. While commit time ordering provides a well-understood standard behavior, it's hardly sufficient. The commit time is unrelated to the actual ordering of data that a user may care about and strict ordering of input in complex distributed systems is difficult to achieve. With event time ordering, the merging picks the record with the highest value on a user-specified ordering or precombine field as the merged result.
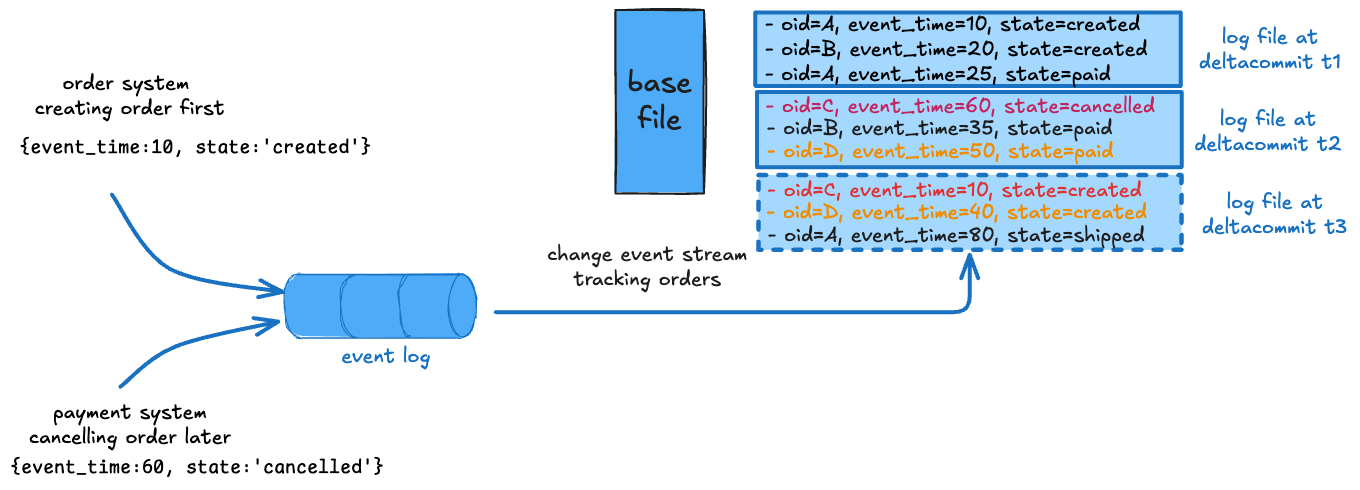
In the example above, two microservices produce change records about orders at different times that can arrive out of order. As color-coded, this can lead to application-level inconsistent states in the table if simply merged in commit time order like a canceled order being re-created or a paid order moved back to just-created state expecting payment again. Event time ordering helps by ignoring older state changes that arrive late and avoiding order status from "jumping back" in time. Combined with non-blocking concurrency control, this provides a very powerful way to process such data streams efficiently and correctly.
CUSTOM
For most users: The built-in COMMIT_TIME_ORDERING and EVENT_TIME_ORDERING merge modes should be sufficient. Only use CUSTOM mode if you need specialized merge logic that cannot be achieved with the standard modes.
In some cases, even more control and customization may be needed. Extending the example above, the two microservices could be updating two different sets of columns "order_info" and "payment_info", along with order state. The merge logic is then expected to not only resolve the correct status, but merge order_info from the record in created state into the record in the canceled state that already has payment_info fields populated with reasons payment failed. Such reconciliation provides a simple denormalized data model for downstream consumption where queries (for example, fraud detection) can simply filter fields across order_info and payment_info without costly self-joins on each access.
To implement custom merge logic, you need to implement the HoodieRecordMerger interface. Hudi allows the authoring of cross-language custom record mergers on top of a standard record merger API, which supports full and partial merges. The HoodieRecordMerger interface uses the BufferedRecord class to provide better performance and consistency by working directly with engine-native record formats without requiring conversion to Avro.
The BufferedRecord class wraps the record data along with key information such as the record key, ordering value, schema identifier, and HoodieOperation. The RecordContext provides a common interface for accessing and manipulating records across different engines (Spark, Flink, etc.), making custom mergers engine-agnostic.
The Java APIs are sketched below at a high level. The interface takes older/newer records wrapped in BufferedRecord instances and produces a merged BufferedRecord. The record merger is configured using a hoodie.write.record.merge.strategy.id write config whose value is a UUID, which is taken by the writer to persist in the table config, and is expected to be returned by getMergingStrategy()
method below. Using this mechanism, Hudi can automatically deduce the record merger to use for the table across different language and engine runtimes.
interface HoodieRecordMerger {
<T> BufferedRecord<T> merge(BufferedRecord<T> older, BufferedRecord<T> newer,
RecordContext<T> recordContext, TypedProperties props) throws IOException {
// Merges full records. Returns a non-null BufferedRecord.
// If the result represents a deletion, set HoodieOperation.DELETE on the returned record.
// Ordering values must always be set if there are ordering fields for the table.
...
}
<T> BufferedRecord<T> partialMerge(BufferedRecord<T> older, BufferedRecord<T> newer,
Schema readerSchema, RecordContext<T> recordContext,
TypedProperties props) throws IOException {
// Merges records which can contain partial updates.
// Returns a non-null BufferedRecord with only changed fields included.
// If the result represents a deletion, set HoodieOperation.DELETE on the returned record.
// Ordering values must always be set if there are ordering fields for the table.
...
}
HoodieRecordType getRecordType() {...}
String getMergingStrategy() {...}
}
Implementation Guidelines
When implementing the HoodieRecordMerger interface, follow these guidelines to ensure consistent results:
-
Return non-null records: Both
merge()andpartialMerge()methods must return a non-nullBufferedRecord. The returned record should contain the merged data whenever possible, even if it represents a deletion. This allows future merge operations to reference the previous value of the data. However, if the data is not available or not needed, it is acceptable to return aBufferedRecordwith null data (e.g., when usingBufferedRecords.createDelete()). -
Handle deletions: If the merged result should delete the row matching the record key, set the
HoodieOperationtoDELETEon the returnedBufferedRecordusingsetHoodieOperation(HoodieOperation.DELETE). -
Preserve ordering values: Always set ordering values in the result if there are any ordering fields configured for the table. This ensures that future merge operations can reference these values correctly.
-
Use RecordContext: The
RecordContextparameter provides engine-agnostic methods to access field values, extract record keys, and manipulate records. Use methods likegetValue(),getRecordKey(), andmergeWithEngineRecord()to work with the underlying data. -
Associative property: The
merge()method should be associative:merge(a, merge(b, c))should yield the same result asmerge(merge(a, b), c)for any three versions A, B, C of the same record.
For more details on the implementation, see RFC 101.
Merge Mode Configs
The record merge mode and optional record merge strategy ID and custom merge implementation classes can be specified using the below configs.
| Config Name | Default | Description |
|---|---|---|
| hoodie.write.record.merge.mode | EVENT_TIME_ORDERING (when ordering field is set) COMMIT_TIME_ORDERING (when ordering field is not set) | Determines the logic of merging different records with the same record key. Valid values: (1) COMMIT_TIME_ORDERING: use commit time to merge records, i.e., the record from later commit overwrites the earlier record with the same key. (2) EVENT_TIME_ORDERING: use event time as the ordering to merge records, i.e., the record with the larger event time overwrites the record with the smaller event time on the same key, regardless of commit time. The event time or ordering fields need to be specified by the user. This is the default when an ordering field is configured. (3) CUSTOM: use custom merging logic specified by the user.Config Param: RECORD_MERGE_MODESince Version: 1.0.0 |
| hoodie.write.record.merge.strategy.id | N/A (Optional) | ID of record merge strategy. Hudi will pick HoodieRecordMerger implementations from hoodie.write.record.merge.custom.implementation.classes that have the same merge strategy ID. When using custom merge logic, you need to specify both this config and hoodie.write.record.merge.custom.implementation.classes.Config Param: RECORD_MERGE_STRATEGY_IDSince Version: 0.13.0Alternative: hoodie.datasource.write.record.merger.strategy (deprecated) |
| hoodie.write.record.merge.custom.implementation.classes | N/A (Optional) | List of HoodieRecordMerger implementations constituting Hudi's merging strategy based on the engine used. Hudi selects the first implementation from this list that matches the following criteria: (1) has the same merge strategy ID as specified in hoodie.write.record.merge.strategy.id (if provided), (2) is compatible with the execution engine (e.g., SPARK merger for Spark, FLINK merger for Flink, AVRO for Java/Hive). The order in the list matters - place your preferred implementation first. Engine-specific implementations (SPARK, FLINK) are more efficient as they avoid Avro serialization/deserialization overhead.Config Param: RECORD_MERGE_IMPL_CLASSESSince Version: 0.13.0Alternative: hoodie.datasource.write.record.merger.impls (deprecated) |
Record Payloads (deprecated)
Deprecation Notice: As of release 1.1.0, the payload-based approach for record merging is deprecated. This approach is closely tied to Avro-formatted records, making it less compatible with native query engine formats (e.g., Spark InternalRow) and more challenging to maintain. We strongly recommends migrating to merge modes, which offer better flexibility, performance, and maintainability for modern lakehouse architectures.
Existing payload-based configurations will continue to work through backwards compatibility, but users are encouraged to migrate their implementations. For details, see RFC 97.
Record payload is an older abstraction/API for achieving similar record-level merge capabilities. While record payloads were very useful and popular, they had drawbacks like lower performance due to conversion of engine-native record formats to Apache Avro for merging and lack of cross-language support. As we shall see below, Hudi provides out-of-the-box support for different payloads for different use cases. Hudi implements fallback from record merger APIs to payload APIs internally, to provide backwards compatibility for existing payload implementations.
OverwriteWithLatestAvroPayload (deprecated)
hoodie.datasource.write.payload.class=org.apache.hudi.common.model.OverwriteWithLatestAvroPayload
This is the default record payload implementation. It picks the record with the greatest value (determined by calling
.compareTo() on the value of precombine key) to break ties and simply picks the latest record while merging. This gives
latest-write-wins style semantics.
DefaultHoodieRecordPayload (deprecated)
hoodie.datasource.write.payload.class=org.apache.hudi.common.model.DefaultHoodieRecordPayload
While OverwriteWithLatestAvroPayload precombines based on an ordering field and picks the latest record while merging,
DefaultHoodieRecordPayload honors the ordering field for both precombining and merging. Let's understand the difference with an example:
Let's say the ordering field is ts and record key is id and schema is:
{
[
{"name":"id","type":"string"},
{"name":"ts","type":"long"},
{"name":"name","type":"string"},
{"name":"price","type":"string"}
]
}
Current record in storage:
id ts name price
1 2 name_2 price_2
Incoming record:
id ts name price
1 1 name_1 price_1
Result data after merging using OverwriteWithLatestAvroPayload (latest-write-wins):
id ts name price
1 1 name_1 price_1
Result data after merging using DefaultHoodieRecordPayload (always honors ordering field):
id ts name price
1 2 name_2 price_2
EventTimeAvroPayload (deprecated)
hoodie.datasource.write.payload.class=org.apache.hudi.common.model.EventTimeAvroPayload
This is the default record payload for Flink-based writing. Some use cases require merging records by event time and thus event time plays the role of an ordering field. This payload is particularly useful in the case of late-arriving data. For such use cases, users need to set the payload event time field configuration.
OverwriteNonDefaultsWithLatestAvroPayload (deprecated)
hoodie.datasource.write.payload.class=org.apache.hudi.common.model.OverwriteNonDefaultsWithLatestAvroPayload
This payload is quite similar to OverwriteWithLatestAvroPayload with slight difference while merging records. For
precombining, just like OverwriteWithLatestAvroPayload, it picks the latest record for a key, based on an ordering
field. While merging, it overwrites the existing record on storage only for the specified fields that don't equal
default value for that field.
PartialUpdateAvroPayload (deprecated)
hoodie.datasource.write.payload.class=org.apache.hudi.common.model.PartialUpdateAvroPayload
This payload supports partial update. Typically, once the merge step resolves which record to pick, then the record on
storage is fully replaced by the resolved record. But, in some cases, the requirement is to update only certain fields
and not replace the whole record. This is called partial update. PartialUpdateAvroPayload provides out-of-the-box support
for such use cases. To illustrate the point, let us look at a simple example:
Let's say the ordering field is ts and record key is id and schema is:
{
[
{"name":"id","type":"string"},
{"name":"ts","type":"long"},
{"name":"name","type":"string"},
{"name":"price","type":"string"}
]
}
Current record in storage:
id ts name price
1 2 name_1 null
Incoming record:
id ts name price
1 1 null price_1
Result data after merging using PartialUpdateAvroPayload:
id ts name price
1 2 name_1 price_1
Record Payload Configs (deprecated)
Payload class can be specified using the below configs. For more advanced configs, refer to the configurations page
Spark based configs:
| Config Name | Default | Description |
|---|---|---|
| hoodie.datasource.write.payload.class | org.apache.hudi.common.model.OverwriteWithLatestAvroPayload (Optional) | Payload class used. Override this, if you like to roll your own merge logic, when upserting/inserting. This will render any value set for PRECOMBINE_FIELD_OPT_VAL in-effectiveConfig Param: WRITE_PAYLOAD_CLASS_NAME |
Flink-based configs:
| Config Name | Default | Description |
|---|---|---|
| payload.class | org.apache.hudi.common.model.EventTimeAvroPayload (Optional) | Payload class used. Override this, if you like to roll your own merge logic, when upserting/inserting. This will render any value set for the option in-effectiveConfig Param: PAYLOAD_CLASS_NAME |
There are also quite a few other implementations. Developers may be interested in looking at the hierarchy of HoodieRecordPayload interface. For
example, MySqlDebeziumAvroPayload and PostgresDebeziumAvroPayload provide support for seamlessly applying changes
captured via Debezium for MySQL and PostgresDB. AWSDmsAvroPayload provides support for applying changes captured via Amazon Database Migration Service onto S3.
For full configurations, see the configurations page and please check out the FAQ if you want to implement your own custom payloads.