Deployment Guide
This section provides all the help you need to deploy and operate Hudi tables at scale. Specifically, we will cover the following aspects.
- Deployment Model : How various Hudi components are deployed and managed.
- Upgrading Versions : Picking up new releases of Hudi, guidelines and general best-practices.
- Migrating to Hudi : How to migrate your existing tables to Apache Hudi.
- Interacting via CLI : Using the CLI to perform maintenance or deeper introspection.
- Monitoring : Tracking metrics from your hudi tables using popular tools.
- Troubleshooting : Uncovering, triaging and resolving issues in production.
Deploying
All in all, Hudi deploys with no long running servers or additional infrastructure cost to your data lake. In fact, Hudi pioneered this model of building a transactional distributed storage layer using existing infrastructure and its heartening to see other systems adopting similar approaches as well. Hudi writing is done via Spark jobs (DeltaStreamer or custom Spark datasource jobs), deployed per standard Apache Spark recommendations. Querying Hudi tables happens via libraries installed into Apache Hive, Apache Spark or PrestoDB and hence no additional infrastructure is necessary.
A typical Hudi data ingestion can be achieved in 2 modes. In a single run mode, Hudi ingestion reads next batch of data, ingest them to Hudi table and exits. In continuous mode, Hudi ingestion runs as a long-running service executing ingestion in a loop.
With Merge_On_Read Table, Hudi ingestion needs to also take care of compacting delta files. Again, compaction can be performed in an asynchronous-mode by letting compaction run concurrently with ingestion or in a serial fashion with one after another.
DeltaStreamer
DeltaStreamer is the standalone utility to incrementally pull upstream changes from varied sources such as DFS, Kafka and DB Changelogs and ingest them to hudi tables. It runs as a spark application in 2 modes.
- Run Once Mode : In this mode, Deltastreamer performs one ingestion round which includes incrementally pulling events from upstream sources and ingesting them to hudi table. Background operations like cleaning old file versions and archiving hoodie timeline are automatically executed as part of the run. For Merge-On-Read tables, Compaction is also run inline as part of ingestion unless disabled by passing the flag "--disable-compaction". By default, Compaction is run inline for every ingestion run and this can be changed by setting the property "hoodie.compact.inline.max.delta.commits". You can either manually run this spark application or use any cron trigger or workflow orchestrator (most common deployment strategy) such as Apache Airflow to spawn this application. See command line options in this section for running the spark application.
Here is an example invocation for reading from kafka topic in a single-run mode and writing to Merge On Read table type in a yarn cluster.
[hoodie]$ spark-submit --packages org.apache.hudi:hudi-utilities-bundle_2.11:0.5.3,org.apache.spark:spark-avro_2.11:2.4.4 \
--master yarn \
--deploy-mode cluster \
--num-executors 10 \
--executor-memory 3g \
--driver-memory 6g \
--conf spark.driver.extraJavaOptions="-XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/varadarb_ds_driver.hprof" \
--conf spark.executor.extraJavaOptions="-XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/varadarb_ds_executor.hprof" \
--queue hadoop-platform-queue \
--conf spark.scheduler.mode=FAIR \
--conf spark.yarn.executor.memoryOverhead=1072 \
--conf spark.yarn.driver.memoryOverhead=2048 \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=1 \
--conf spark.task.maxFailures=10 \
--conf spark.memory.fraction=0.4 \
--conf spark.rdd.compress=true \
--conf spark.kryoserializer.buffer.max=200m \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.memory.storageFraction=0.1 \
--conf spark.shuffle.service.enabled=true \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.ui.port=5555 \
--conf spark.driver.maxResultSize=3g \
--conf spark.executor.heartbeatInterval=120s \
--conf spark.network.timeout=600s \
--conf spark.eventLog.overwrite=true \
--conf spark.eventLog.enabled=true \
--conf spark.eventLog.dir=hdfs:///user/spark/applicationHistory \
--conf spark.yarn.max.executor.failures=10 \
--conf spark.sql.catalogImplementation=hive \
--conf spark.sql.shuffle.partitions=100 \
--driver-class-path $HADOOP_CONF_DIR \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
--table-type MERGE_ON_READ \
--source-class org.apache.hudi.utilities.sources.JsonKafkaSource \
--source-ordering-field ts \
--target-base-path /user/hive/warehouse/stock_ticks_mor \
--target-table stock_ticks_mor \
--props /var/demo/config/kafka-source.properties \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider
- Continuous Mode : Here, deltastreamer runs an infinite loop with each round performing one ingestion round as described in Run Once Mode. The frequency of data ingestion can be controlled by the configuration "--min-sync-interval-seconds". For Merge-On-Read tables, Compaction is run in asynchronous fashion concurrently with ingestion unless disabled by passing the flag "--disable-compaction". Every ingestion run triggers a compaction request asynchronously and this frequency can be changed by setting the property "hoodie.compact.inline.max.delta.commits". As both ingestion and compaction is running in the same spark context, you can use resource allocation configuration in DeltaStreamer CLI such as ("--delta-sync-scheduling-weight", "--compact-scheduling-weight", ""--delta-sync-scheduling-minshare", and "--compact-scheduling-minshare") to control executor allocation between ingestion and compaction.
Here is an example invocation for reading from kafka topic in a continuous mode and writing to Merge On Read table type in a yarn cluster.
[hoodie]$ spark-submit --packages org.apache.hudi:hudi-utilities-bundle_2.11:0.5.3,org.apache.spark:spark-avro_2.11:2.4.4 \
--master yarn \
--deploy-mode cluster \
--num-executors 10 \
--executor-memory 3g \
--driver-memory 6g \
--conf spark.driver.extraJavaOptions="-XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/varadarb_ds_driver.hprof" \
--conf spark.executor.extraJavaOptions="-XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/varadarb_ds_executor.hprof" \
--queue hadoop-platform-queue \
--conf spark.scheduler.mode=FAIR \
--conf spark.yarn.executor.memoryOverhead=1072 \
--conf spark.yarn.driver.memoryOverhead=2048 \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=1 \
--conf spark.task.maxFailures=10 \
--conf spark.memory.fraction=0.4 \
--conf spark.rdd.compress=true \
--conf spark.kryoserializer.buffer.max=200m \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.memory.storageFraction=0.1 \
--conf spark.shuffle.service.enabled=true \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.ui.port=5555 \
--conf spark.driver.maxResultSize=3g \
--conf spark.executor.heartbeatInterval=120s \
--conf spark.network.timeout=600s \
--conf spark.eventLog.overwrite=true \
--conf spark.eventLog.enabled=true \
--conf spark.eventLog.dir=hdfs:///user/spark/applicationHistory \
--conf spark.yarn.max.executor.failures=10 \
--conf spark.sql.catalogImplementation=hive \
--conf spark.sql.shuffle.partitions=100 \
--driver-class-path $HADOOP_CONF_DIR \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
--table-type MERGE_ON_READ \
--source-class org.apache.hudi.utilities.sources.JsonKafkaSource \
--source-ordering-field ts \
--target-base-path /user/hive/warehouse/stock_ticks_mor \
--target-table stock_ticks_mor \
--props /var/demo/config/kafka-source.properties \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \
--continuous
Spark Datasource Writer Jobs
As described in Writing Data, you can use spark datasource to ingest to hudi table. This mechanism allows you to ingest any spark dataframe in Hudi format. Hudi Spark DataSource also supports spark streaming to ingest a streaming source to Hudi table. For Merge On Read table types, inline compaction is turned on by default which runs after every ingestion run. The compaction frequency can be changed by setting the property "hoodie.compact.inline.max.delta.commits".
Here is an example invocation using spark datasource
inputDF.write()
.format("org.apache.hudi")
.options(clientOpts) // any of the Hudi client opts can be passed in as well
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY(), "_row_key")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY(), "partition")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY(), "timestamp")
.option(HoodieWriteConfig.TABLE_NAME, tableName)
.mode(SaveMode.Append)
.save(basePath);
Upgrading
New Hudi releases are listed on the releases page, with detailed notes which list all the changes, with highlights in each release. At the end of the day, Hudi is a storage system and with that comes a lot of responsibilities, which we take seriously.
As general guidelines,
- We strive to keep all changes backwards compatible (i.e new code can read old data/timeline files) and when we cannot, we will provide upgrade/downgrade tools via the CLI
- We cannot always guarantee forward compatibility (i.e old code being able to read data/timeline files written by a greater version). This is generally the norm, since no new features can be built otherwise. However any large such changes, will be turned off by default, for smooth transition to newer release. After a few releases and once enough users deem the feature stable in production, we will flip the defaults in a subsequent release.
- Always upgrade the query bundles (mr-bundle, presto-bundle, spark-bundle) first and then upgrade the writers (deltastreamer, spark jobs using datasource). This often provides the best experience and it's easy to fix any issues by rolling forward/back the writer code (which typically you might have more control over)
- With large, feature rich releases we recommend migrating slowly, by first testing in staging environments and running your own tests. Upgrading Hudi is no different than upgrading any database system.
Note that release notes can override this information with specific instructions, applicable on case-by-case basis.
Migrating
Currently migrating to Hudi can be done using two approaches
- Convert newer partitions to Hudi : This model is suitable for large event tables (e.g: click streams, ad impressions), which also typically receive writes for the last few days alone. You can convert the last N partitions to Hudi and proceed writing as if it were a Hudi table to begin with. The Hudi query side code is able to correctly handle both hudi and non-hudi data partitions.
- Full conversion to Hudi : This model is suitable if you are currently bulk/full loading the table few times a day (e.g database ingestion). The full conversion of Hudi is simply a one-time step (akin to 1 run of your existing job), which moves all of the data into the Hudi format and provides the ability to incrementally update for future writes.
For more details, refer to the detailed migration guide. In the future, we will be supporting seamless zero-copy bootstrap of existing tables with all the upsert/incremental query capabilities fully supported.
CLI
Once hudi has been built, the shell can be fired by via cd hudi-cli && ./hudi-cli.sh. A hudi table resides on DFS, in a location referred to as the basePath and
we would need this location in order to connect to a Hudi table. Hudi library effectively manages this table internally, using .hoodie subfolder to track all metadata.
To initialize a hudi table, use the following command.
===================================================================
* ___ ___ *
* /\__\ ___ /\ \ ___ *
* / / / /\__\ / \ \ /\ \ *
* / /__/ / / / / /\ \ \ \ \ \ *
* / \ \ ___ / / / / / \ \__\ / \__\ *
* / /\ \ /\__\ / /__/ ___ / /__/ \ |__| / /\/__/ *
* \/ \ \/ / / \ \ \ /\__\ \ \ \ / / / /\/ / / *
* \ / / \ \ / / / \ \ / / / \ /__/ *
* / / / \ \/ / / \ \/ / / \ \__\ *
* / / / \ / / \ / / \/__/ *
* \/__/ \/__/ \/__/ Apache Hudi CLI *
* *
===================================================================
hudi->create --path /user/hive/warehouse/table1 --tableName hoodie_table_1 --tableType COPY_ON_WRITE
.....
To see the description of hudi table, use the command:
hudi:hoodie_table_1->desc
18/09/06 15:57:19 INFO timeline.HoodieActiveTimeline: Loaded instants []
_________________________________________________________
| Property | Value |
|========================================================|
| basePath | ... |
| metaPath | ... |
| fileSystem | hdfs |
| hoodie.table.name | hoodie_table_1 |
| hoodie.table.type | COPY_ON_WRITE |
| hoodie.archivelog.folder| |
Following is a sample command to connect to a Hudi table contains uber trips.
hudi:trips->connect --path /app/uber/trips
16/10/05 23:20:37 INFO model.HoodieTableMetadata: All commits :HoodieCommits{commitList=[20161002045850, 20161002052915, 20161002055918, 20161002065317, 20161002075932, 20161002082904, 20161002085949, 20161002092936, 20161002105903, 20161002112938, 20161002123005, 20161002133002, 20161002155940, 20161002165924, 20161002172907, 20161002175905, 20161002190016, 20161002192954, 20161002195925, 20161002205935, 20161002215928, 20161002222938, 20161002225915, 20161002232906, 20161003003028, 20161003005958, 20161003012936, 20161003022924, 20161003025859, 20161003032854, 20161003042930, 20161003052911, 20161003055907, 20161003062946, 20161003065927, 20161003075924, 20161003082926, 20161003085925, 20161003092909, 20161003100010, 20161003102913, 20161003105850, 20161003112910, 20161003115851, 20161003122929, 20161003132931, 20161003142952, 20161003145856, 20161003152953, 20161003155912, 20161003162922, 20161003165852, 20161003172923, 20161003175923, 20161003195931, 20161003210118, 20161003212919, 20161003215928, 20161003223000, 20161003225858, 20161004003042, 20161004011345, 20161004015235, 20161004022234, 20161004063001, 20161004072402, 20161004074436, 20161004080224, 20161004082928, 20161004085857, 20161004105922, 20161004122927, 20161004142929, 20161004163026, 20161004175925, 20161004194411, 20161004203202, 20161004211210, 20161004214115, 20161004220437, 20161004223020, 20161004225321, 20161004231431, 20161004233643, 20161005010227, 20161005015927, 20161005022911, 20161005032958, 20161005035939, 20161005052904, 20161005070028, 20161005074429, 20161005081318, 20161005083455, 20161005085921, 20161005092901, 20161005095936, 20161005120158, 20161005123418, 20161005125911, 20161005133107, 20161005155908, 20161005163517, 20161005165855, 20161005180127, 20161005184226, 20161005191051, 20161005193234, 20161005203112, 20161005205920, 20161005212949, 20161005223034, 20161005225920]}
Metadata for table trips loaded
Once connected to the table, a lot of other commands become available. The shell has contextual autocomplete help (press TAB) and below is a list of all commands, few of which are reviewed in this section are reviewed
hudi:trips->help
* ! - Allows execution of operating system (OS) commands
* // - Inline comment markers (start of line only)
* ; - Inline comment markers (start of line only)
* addpartitionmeta - Add partition metadata to a table, if not present
* clear - Clears the console
* cls - Clears the console
* commit rollback - Rollback a commit
* commits compare - Compare commits with another Hoodie table
* commit showfiles - Show file level details of a commit
* commit showpartitions - Show partition level details of a commit
* commits refresh - Refresh the commits
* commits show - Show the commits
* commits sync - Compare commits with another Hoodie table
* connect - Connect to a hoodie table
* date - Displays the local date and time
* exit - Exits the shell
* help - List all commands usage
* quit - Exits the shell
* records deduplicate - De-duplicate a partition path contains duplicates & produce repaired files to replace with
* script - Parses the specified resource file and executes its commands
* stats filesizes - File Sizes. Display summary stats on sizes of files
* stats wa - Write Amplification. Ratio of how many records were upserted to how many records were actually written
* sync validate - Validate the sync by counting the number of records
* system properties - Shows the shell's properties
* utils loadClass - Load a class
* version - Displays shell version
hudi:trips->
Inspecting Commits
The task of upserting or inserting a batch of incoming records is known as a commit in Hudi. A commit provides basic atomicity guarantees such that only committed data is available for querying. Each commit has a monotonically increasing string/number called the commit number. Typically, this is the time at which we started the commit.
To view some basic information about the last 10 commits,
hudi:trips->commits show --sortBy "Total Bytes Written" --desc true --limit 10
________________________________________________________________________________________________________________________________________________________________________
| CommitTime | Total Bytes Written| Total Files Added| Total Files Updated| Total Partitions Written| Total Records Written| Total Update Records Written| Total Errors|
|=======================================================================================================================================================================|
....
....
....
At the start of each write, Hudi also writes a .inflight commit to the .hoodie folder. You can use the timestamp there to estimate how long the commit has been inflight
$ hdfs dfs -ls /app/uber/trips/.hoodie/*.inflight
-rw-r--r-- 3 vinoth supergroup 321984 2016-10-05 23:18 /app/uber/trips/.hoodie/20161005225920.inflight
Drilling Down to a specific Commit
To understand how the writes spread across specific partiions,
hudi:trips->commit showpartitions --commit 20161005165855 --sortBy "Total Bytes Written" --desc true --limit 10
__________________________________________________________________________________________________________________________________________
| Partition Path| Total Files Added| Total Files Updated| Total Records Inserted| Total Records Updated| Total Bytes Written| Total Errors|
|=========================================================================================================================================|
....
....
If you need file level granularity , we can do the following
hudi:trips->commit showfiles --commit 20161005165855 --sortBy "Partition Path"
________________________________________________________________________________________________________________________________________________________
| Partition Path| File ID | Previous Commit| Total Records Updated| Total Records Written| Total Bytes Written| Total Errors|
|=======================================================================================================================================================|
....
....
FileSystem View
Hudi views each partition as a collection of file-groups with each file-group containing a list of file-slices in commit order (See concepts). The below commands allow users to view the file-slices for a data-set.
hudi:stock_ticks_mor->show fsview all
....
_______________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
| Partition | FileId | Base-Instant | Data-File | Data-File Size| Num Delta Files| Total Delta File Size| Delta Files |
|==============================================================================================================================================================================================================================================================================================================================================================================================================|
| 2018/08/31| 111415c3-f26d-4639-86c8-f9956f245ac3| 20181002180759| hdfs://namenode:8020/user/hive/warehouse/stock_ticks_mor/2018/08/31/111415c3-f26d-4639-86c8-f9956f245ac3_0_20181002180759.parquet| 432.5 KB | 1 | 20.8 KB | [HoodieLogFile {hdfs://namenode:8020/user/hive/warehouse/stock_ticks_mor/2018/08/31/.111415c3-f26d-4639-86c8-f9956f245ac3_20181002180759.log.1}]|
hudi:stock_ticks_mor->show fsview latest --partitionPath "2018/08/31"
......
__________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
| Partition | FileId | Base-Instant | Data-File | Data-File Size| Num Delta Files| Total Delta Size| Delta Size - compaction scheduled| Delta Size - compaction unscheduled| Delta To Base Ratio - compaction scheduled| Delta To Base Ratio - compaction unscheduled| Delta Files - compaction scheduled | Delta Files - compaction unscheduled|
|=================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================|
| 2018/08/31| 111415c3-f26d-4639-86c8-f9956f245ac3| 20181002180759| hdfs://namenode:8020/user/hive/warehouse/stock_ticks_mor/2018/08/31/111415c3-f26d-4639-86c8-f9956f245ac3_0_20181002180759.parquet| 432.5 KB | 1 | 20.8 KB | 20.8 KB | 0.0 B | 0.0 B | 0.0 B | [HoodieLogFile {hdfs://namenode:8020/user/hive/warehouse/stock_ticks_mor/2018/08/31/.111415c3-f26d-4639-86c8-f9956f245ac3_20181002180759.log.1}]| [] |
Statistics
Since Hudi directly manages file sizes for DFS table, it might be good to get an overall picture
hudi:trips->stats filesizes --partitionPath 2016/09/01 --sortBy "95th" --desc true --limit 10
________________________________________________________________________________________________
| CommitTime | Min | 10th | 50th | avg | 95th | Max | NumFiles| StdDev |
|===============================================================================================|
| <COMMIT_ID> | 93.9 MB | 93.9 MB | 93.9 MB | 93.9 MB | 93.9 MB | 93.9 MB | 2 | 2.3 KB |
....
....
In case of Hudi write taking much longer, it might be good to see the write amplification for any sudden increases
hudi:trips->stats wa
__________________________________________________________________________
| CommitTime | Total Upserted| Total Written| Write Amplifiation Factor|
|=========================================================================|
....
....
Archived Commits
In order to limit the amount of growth of .commit files on DFS, Hudi archives older .commit files (with due respect to the cleaner policy) into a commits.archived file. This is a sequence file that contains a mapping from commitNumber => json with raw information about the commit (same that is nicely rolled up above).
Compactions
To get an idea of the lag between compaction and writer applications, use the below command to list down all pending compactions.
hudi:trips->compactions show all
___________________________________________________________________
| Compaction Instant Time| State | Total FileIds to be Compacted|
|==================================================================|
| <INSTANT_1> | REQUESTED| 35 |
| <INSTANT_2> | INFLIGHT | 27 |
To inspect a specific compaction plan, use
hudi:trips->compaction show --instant <INSTANT_1>
_________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
| Partition Path| File Id | Base Instant | Data File Path | Total Delta Files| getMetrics |
|================================================================================================================================================================================================================================================
| 2018/07/17 | <UUID> | <INSTANT_1> | viewfs://ns-default/.../../UUID_<INSTANT>.parquet | 1 | {TOTAL_LOG_FILES=1.0, TOTAL_IO_READ_MB=1230.0, TOTAL_LOG_FILES_SIZE=2.51255751E8, TOTAL_IO_WRITE_MB=991.0, TOTAL_IO_MB=2221.0}|
To manually schedule or run a compaction, use the below command. This command uses spark launcher to perform compaction operations.
NOTE: Make sure no other application is scheduling compaction for this table concurrently {: .notice--info}
hudi:trips->help compaction schedule
Keyword: compaction schedule
Description: Schedule Compaction
Keyword: sparkMemory
Help: Spark executor memory
Mandatory: false
Default if specified: '__NULL__'
Default if unspecified: '1G'
* compaction schedule - Schedule Compaction
hudi:trips->help compaction run
Keyword: compaction run
Description: Run Compaction for given instant time
Keyword: tableName
Help: Table name
Mandatory: true
Default if specified: '__NULL__'
Default if unspecified: '__NULL__'
Keyword: parallelism
Help: Parallelism for hoodie compaction
Mandatory: true
Default if specified: '__NULL__'
Default if unspecified: '__NULL__'
Keyword: schemaFilePath
Help: Path for Avro schema file
Mandatory: true
Default if specified: '__NULL__'
Default if unspecified: '__NULL__'
Keyword: sparkMemory
Help: Spark executor memory
Mandatory: true
Default if specified: '__NULL__'
Default if unspecified: '__NULL__'
Keyword: retry
Help: Number of retries
Mandatory: true
Default if specified: '__NULL__'
Default if unspecified: '__NULL__'
Keyword: compactionInstant
Help: Base path for the target hoodie table
Mandatory: true
Default if specified: '__NULL__'
Default if unspecified: '__NULL__'
* compaction run - Run Compaction for given instant time
Validate Compaction
Validating a compaction plan : Check if all the files necessary for compactions are present and are valid
hudi:stock_ticks_mor->compaction validate --instant 20181005222611
...
COMPACTION PLAN VALID
___________________________________________________________________________________________________________________________________________________________________________________________________________________________
| File Id | Base Instant Time| Base Data File | Num Delta Files| Valid| Error|
|==========================================================================================================================================================================================================================|
| 05320e98-9a57-4c38-b809-a6beaaeb36bd| 20181005222445 | hdfs://namenode:8020/user/hive/warehouse/stock_ticks_mor/2018/08/31/05320e98-9a57-4c38-b809-a6beaaeb36bd_0_20181005222445.parquet| 1 | true | |
hudi:stock_ticks_mor->compaction validate --instant 20181005222601
COMPACTION PLAN INVALID
_______________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
| File Id | Base Instant Time| Base Data File | Num Delta Files| Valid| Error |
|=====================================================================================================================================================================================================================================================================================================|
| 05320e98-9a57-4c38-b809-a6beaaeb36bd| 20181005222445 | hdfs://namenode:8020/user/hive/warehouse/stock_ticks_mor/2018/08/31/05320e98-9a57-4c38-b809-a6beaaeb36bd_0_20181005222445.parquet| 1 | false| All log files specified in compaction operation is not present. Missing .... |
NOTE: The following commands must be executed without any other writer/ingestion application running. {: .notice--warning}
Sometimes, it becomes necessary to remove a fileId from a compaction-plan inorder to speed-up or unblock compaction operation. Any new log-files that happened on this file after the compaction got scheduled will be safely renamed so that are preserved. Hudi provides the following CLI to support it
Unscheduling Compaction
hudi:trips->compaction unscheduleFileId --fileId <FileUUID>
....
No File renames needed to unschedule file from pending compaction. Operation successful.
In other cases, an entire compaction plan needs to be reverted. This is supported by the following CLI
hudi:trips->compaction unschedule --instant <compactionInstant>
.....
No File renames needed to unschedule pending compaction. Operation successful.
Repair Compaction
The above compaction unscheduling operations could sometimes fail partially (e:g -> DFS temporarily unavailable). With
partial failures, the compaction operation could become inconsistent with the state of file-slices. When you run
compaction validate, you can notice invalid compaction operations if there is one. In these cases, the repair
command comes to the rescue, it will rearrange the file-slices so that there is no loss and the file-slices are
consistent with the compaction plan
hudi:stock_ticks_mor->compaction repair --instant 20181005222611
......
Compaction successfully repaired
.....
Troubleshooting
Section below generally aids in debugging Hudi failures. Off the bat, the following metadata is added to every record to help triage issues easily using standard Hadoop SQL engines (Hive/PrestoDB/Spark)
- _hoodie_record_key - Treated as a primary key within each DFS partition, basis of all updates/inserts
- _hoodie_commit_time - Last commit that touched this record
- _hoodie_file_name - Actual file name containing the record (super useful to triage duplicates)
- _hoodie_partition_path - Path from basePath that identifies the partition containing this record
For performance related issues, please refer to the tuning guide
Missing records
Please check if there were any write errors using the admin commands above, during the window at which the record could have been written. If you do find errors, then the record was not actually written by Hudi, but handed back to the application to decide what to do with it.
Duplicates
First of all, please confirm if you do indeed have duplicates AFTER ensuring the query is accessing the Hudi table properly .
- If confirmed, please use the metadata fields above, to identify the physical files & partition files containing the records .
- If duplicates span files across partitionpath, then this means your application is generating different partitionPaths for same recordKey, Please fix your app
- if duplicates span multiple files within the same partitionpath, please engage with mailing list. This should not happen. You can use the
records deduplicatecommand to fix your data.
Spark failures
Typical upsert() DAG looks like below. Note that Hudi client also caches intermediate RDDs to intelligently profile workload and size files and spark parallelism. Also Spark UI shows sortByKey twice due to the probe job also being shown, nonetheless its just a single sort.
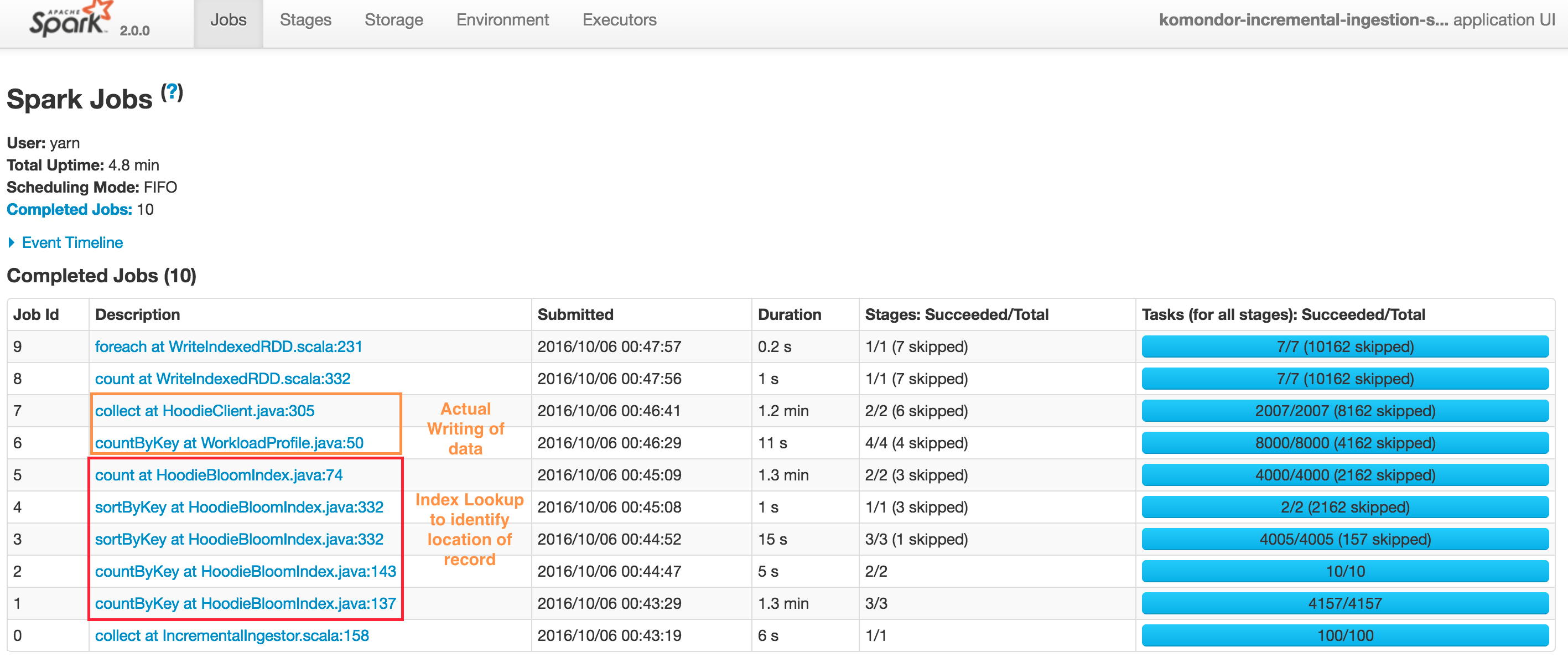
At a high level, there are two steps
Index Lookup to identify files to be changed
- Job 1 : Triggers the input data read, converts to HoodieRecord object and then stops at obtaining a spread of input records to target partition paths
- Job 2 : Load the set of file names which we need check against
- Job 3 & 4 : Actual lookup after smart sizing of spark join parallelism, by joining RDDs in 1 & 2 above
- Job 5 : Have a tagged RDD of recordKeys with locations
Performing the actual writing of data
- Job 6 : Lazy join of incoming records against recordKey, location to provide a final set of HoodieRecord which now contain the information about which file/partitionpath they are found at (or null if insert). Then also profile the workload again to determine sizing of files
- Job 7 : Actual writing of data (update + insert + insert turned to updates to maintain file size)
Depending on the exception source (Hudi/Spark), the above knowledge of the DAG can be used to pinpoint the actual issue. The most often encountered failures result from YARN/DFS temporary failures. In the future, a more sophisticated debug/management UI would be added to the project, that can help automate some of this debugging.