Deployment
This section provides all the help you need to deploy and operate Hudi tables at scale. Specifically, we will cover the following aspects.
- Deployment Model : How various Hudi components are deployed and managed.
- Upgrading Versions : Picking up new releases of Hudi, guidelines and general best-practices.
- Downgrading Versions : Reverting back to an older version of Hudi
- Migrating to Hudi : How to migrate your existing tables to Apache Hudi.
Deploying
All in all, Hudi deploys with no long running servers or additional infrastructure cost to your data lake. In fact, Hudi pioneered this model of building a transactional distributed storage layer using existing infrastructure and its heartening to see other systems adopting similar approaches as well. Hudi writing is done via Spark jobs (Hudi Streamer or custom Spark datasource jobs), deployed per standard Apache Spark recommendations. Querying Hudi tables happens via libraries installed into Apache Hive, Apache Spark or PrestoDB and hence no additional infrastructure is necessary.
A typical Hudi data ingestion can be achieved in 2 modes. In a single run mode, Hudi ingestion reads next batch of data, ingest them to Hudi table and exits. In continuous mode, Hudi ingestion runs as a long-running service executing ingestion in a loop.
With Merge_On_Read Table, Hudi ingestion needs to also take care of compacting delta files. Again, compaction can be performed in an asynchronous-mode by letting compaction run concurrently with ingestion or in a serial fashion with one after another.
Hudi Streamer
Hudi Streamer is the standalone utility to incrementally pull upstream changes from varied sources such as DFS, Kafka and DB Changelogs and ingest them to hudi tables. It runs as a spark application in two modes.
To use Hudi Streamer in Spark, the hudi-utilities-slim-bundle and Hudi Spark bundle are required, by adding
--packages org.apache.hudi:hudi-utilities-slim-bundle_2.12:1.0.1,org.apache.hudi:hudi-spark3.5-bundle_2.12:1.0.1 to the spark-submit command.
Pick the Spark bundle that matches your Spark runtime — for example, hudi-spark3.3-bundle_2.12, hudi-spark3.4-bundle_2.12, hudi-spark3.5-bundle_2.12 (Scala 2.12 or 2.13), hudi-spark3.5-bundle_2.13, hudi-spark4.0-bundle_2.13, or hudi-spark4.1-bundle_2.13. Spark 4.0 and 4.1 require Java 17 or later at runtime; Spark 3.x runs on Java 8 or later.
- Run Once Mode : In this mode, Hudi Streamer performs one ingestion round which includes incrementally pulling events from upstream sources and ingesting them to hudi table. Background operations like cleaning old file versions and archiving hoodie timeline are automatically executed as part of the run. For Merge-On-Read tables, Compaction is also run inline as part of ingestion unless disabled by passing the flag "--disable-compaction". By default, Compaction is run inline for every ingestion run and this can be changed by setting the property "hoodie.compact.inline.max.delta.commits". You can either manually run this spark application or use any cron trigger or workflow orchestrator (most common deployment strategy) such as Apache Airflow to spawn this application. See command line options in this section for running the spark application.
Here is an example invocation for reading from kafka topic in a single-run mode and writing to Merge On Read table type in a yarn cluster.
spark-submit \
--packages org.apache.hudi:hudi-utilities-slim-bundle_2.12:1.0.1,org.apache.hudi:hudi-spark3.5-bundle_2.12:1.0.1 \
--master yarn \
--deploy-mode cluster \
--num-executors 10 \
--executor-memory 3g \
--driver-memory 6g \
--conf spark.driver.extraJavaOptions="-XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/varadarb_ds_driver.hprof" \
--conf spark.executor.extraJavaOptions="-XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/varadarb_ds_executor.hprof" \
--queue hadoop-platform-queue \
--conf spark.scheduler.mode=FAIR \
--conf spark.yarn.executor.memoryOverhead=1072 \
--conf spark.yarn.driver.memoryOverhead=2048 \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=1 \
--conf spark.task.maxFailures=10 \
--conf spark.memory.fraction=0.4 \
--conf spark.rdd.compress=true \
--conf spark.kryoserializer.buffer.max=200m \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.memory.storageFraction=0.1 \
--conf spark.shuffle.service.enabled=true \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.ui.port=5555 \
--conf spark.driver.maxResultSize=3g \
--conf spark.executor.heartbeatInterval=120s \
--conf spark.network.timeout=600s \
--conf spark.eventLog.overwrite=true \
--conf spark.eventLog.enabled=true \
--conf spark.eventLog.dir=hdfs:///user/spark/applicationHistory \
--conf spark.yarn.max.executor.failures=10 \
--conf spark.sql.catalogImplementation=hive \
--conf spark.sql.shuffle.partitions=100 \
--driver-class-path $HADOOP_CONF_DIR \
--class org.apache.hudi.utilities.streamer.HoodieStreamer \
--table-type MERGE_ON_READ \
--source-class org.apache.hudi.utilities.sources.JsonKafkaSource \
--source-ordering-field ts \
--target-base-path /user/hive/warehouse/stock_ticks_mor \
--target-table stock_ticks_mor \
--props /var/demo/config/kafka-source.properties \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider
- Continuous Mode : Here, Hudi Streamer runs an infinite loop with each round performing one ingestion round as described in Run Once Mode. The frequency of data ingestion can be controlled by the configuration "--min-sync-interval-seconds". For Merge-On-Read tables, Compaction is run in asynchronous fashion concurrently with ingestion unless disabled by passing the flag "--disable-compaction". Every ingestion run triggers a compaction request asynchronously and this frequency can be changed by setting the property "hoodie.compact.inline.max.delta.commits". As both ingestion and compaction is running in the same spark context, you can use resource allocation configuration in Hudi Streamer CLI such as ("--delta-sync-scheduling-weight", "--compact-scheduling-weight", ""--delta-sync-scheduling-minshare", and "--compact-scheduling-minshare") to control executor allocation between ingestion and compaction.
Here is an example invocation for reading from kafka topic in a continuous mode and writing to Merge On Read table type in a yarn cluster.
spark-submit \
--packages org.apache.hudi:hudi-utilities-slim-bundle_2.12:1.0.1,org.apache.hudi:hudi-spark3.5-bundle_2.12:1.0.1 \
--master yarn \
--deploy-mode cluster \
--num-executors 10 \
--executor-memory 3g \
--driver-memory 6g \
--conf spark.driver.extraJavaOptions="-XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/varadarb_ds_driver.hprof" \
--conf spark.executor.extraJavaOptions="-XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/varadarb_ds_executor.hprof" \
--queue hadoop-platform-queue \
--conf spark.scheduler.mode=FAIR \
--conf spark.yarn.executor.memoryOverhead=1072 \
--conf spark.yarn.driver.memoryOverhead=2048 \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=1 \
--conf spark.task.maxFailures=10 \
--conf spark.memory.fraction=0.4 \
--conf spark.rdd.compress=true \
--conf spark.kryoserializer.buffer.max=200m \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.memory.storageFraction=0.1 \
--conf spark.shuffle.service.enabled=true \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.ui.port=5555 \
--conf spark.driver.maxResultSize=3g \
--conf spark.executor.heartbeatInterval=120s \
--conf spark.network.timeout=600s \
--conf spark.eventLog.overwrite=true \
--conf spark.eventLog.enabled=true \
--conf spark.eventLog.dir=hdfs:///user/spark/applicationHistory \
--conf spark.yarn.max.executor.failures=10 \
--conf spark.sql.catalogImplementation=hive \
--conf spark.sql.shuffle.partitions=100 \
--driver-class-path $HADOOP_CONF_DIR \
--class org.apache.hudi.utilities.streamer.HoodieStreamer \
--table-type MERGE_ON_READ \
--source-class org.apache.hudi.utilities.sources.JsonKafkaSource \
--source-ordering-field ts \
--target-base-path /user/hive/warehouse/stock_ticks_mor \
--target-table stock_ticks_mor \
--props /var/demo/config/kafka-source.properties \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \
--continuous
Spark Datasource Writer Jobs
As described in Batch Writes, you can use spark datasource to ingest to hudi table. This mechanism allows you to ingest any spark dataframe in Hudi format. Hudi Spark DataSource also supports spark streaming to ingest a streaming source to Hudi table. For Merge On Read table types, inline compaction is turned on by default which runs after every ingestion run. The compaction frequency can be changed by setting the property "hoodie.compact.inline.max.delta.commits".
Here is an example invocation using spark datasource
inputDF.write()
.format("org.apache.hudi")
.options(clientOpts) // any of the Hudi client opts can be passed in as well
.option("hoodie.datasource.write.recordkey.field", "_row_key")
.option("hoodie.datasource.write.partitionpath.field", "partition")
.option("hoodie.table.ordering.fields", "timestamp")
.option("hoodie.table.name", tableName)
.mode(SaveMode.Append)
.save(basePath);
Upgrading
New Hudi releases are listed on the releases page, with detailed notes which list all the changes, with highlights in each release. At the end of the day, Hudi is a storage system and with that comes a lot of responsibilities, which we take seriously.
As general guidelines,
- We strive to keep all changes backwards compatible (i.e new code can read old data/timeline files) and when we cannot, we will provide upgrade/downgrade tools via the CLI
- We cannot always guarantee forward compatibility (i.e old code being able to read data/timeline files written by a greater version). This is generally the norm, since no new features can be built otherwise. However any large such changes, will be turned off by default, for smooth transition to newer release. After a few releases and once enough users deem the feature stable in production, we will flip the defaults in a subsequent release.
- Always upgrade the query bundles (mr-bundle, presto-bundle, spark-bundle) first and then upgrade the writers (Hudi Streamer, spark jobs using datasource). This often provides the best experience and it's easy to fix any issues by rolling forward/back the writer code (which typically you might have more control over)
- With large, feature rich releases we recommend migrating slowly, by first testing in staging environments and running your own tests. Upgrading Hudi is no different than upgrading any database system.
Note that release notes can override this information with specific instructions, applicable on case-by-case basis.
Upgrading to 1.0.0
1.0.0 is a major release with significant format changes. To ensure a smooth migration experience, we recommend the following steps:
- Stop any async table services in 0.x completely.
- Upgrade writers to 1.x with table version (tv) 6,
autoUpgradeand metadata disabled (this won't auto-upgrade anything); 0.x readers will continue to work; writers can also be readers and will continue to read both tv=6. a. Sethoodie.write.auto.upgradeto false. b. Sethoodie.metadata.enableto false.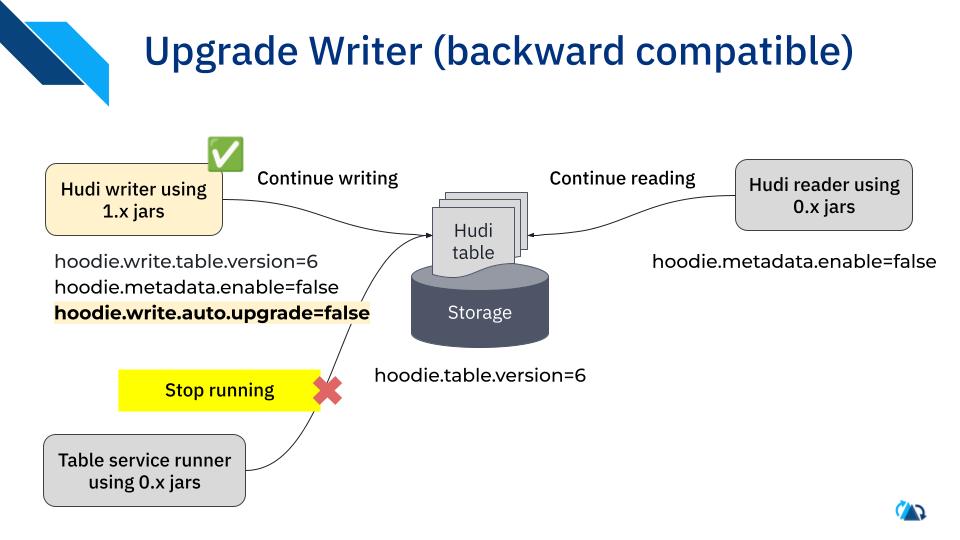
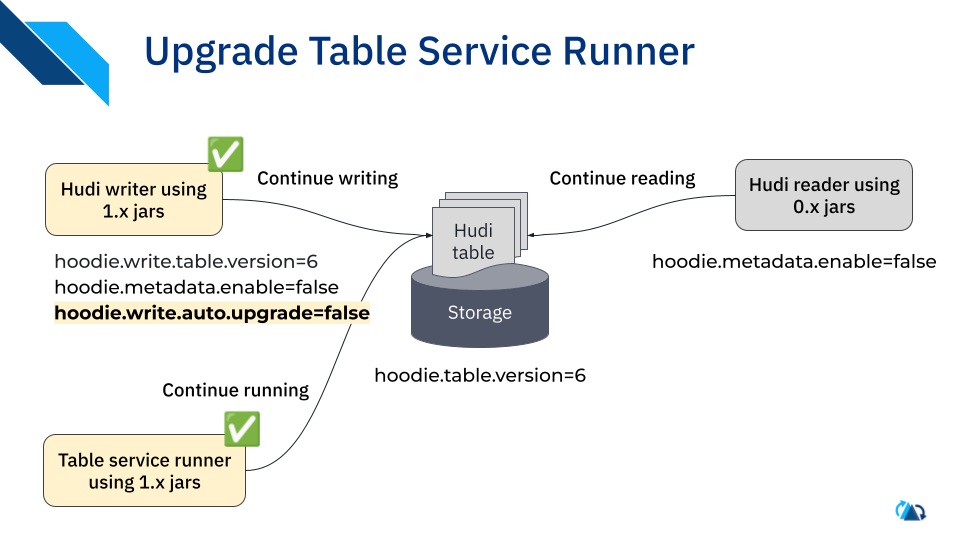
- Upgrade table services to 1.x with tv=6, and resume operations.
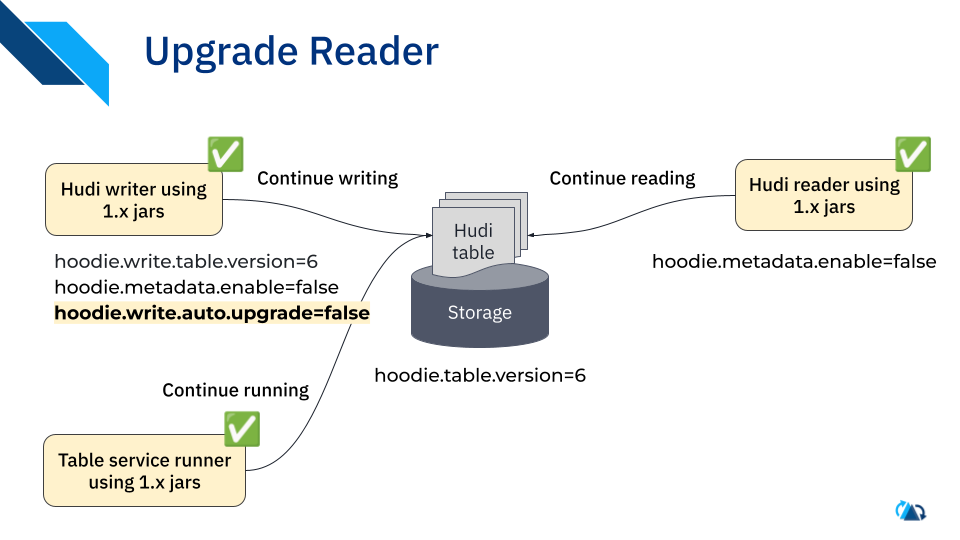
- Upgrade all remaining readers to 1.x, with tv=6.
- Redeploy writers with tv=8; table services and readers will adapt/pick up tv=8 on the fly.
- Once all readers and writers are in 1.x, we are good to enable any new features, including metadata, with 1.x tables.
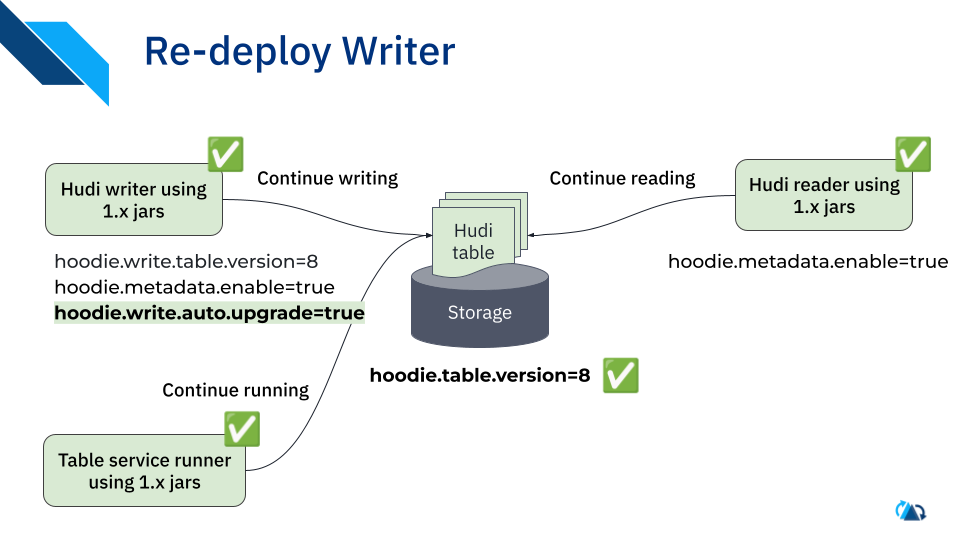
During the upgrade, metadata table will not be updated and it will be behind the data table. It is important to note that metadata table will be updated only when the writer is upgraded to tv=8. So, even the readers should keep metadata disabled during rolling upgrade until all writers are upgraded to tv=8.
Most things are seamlessly handled by the auto upgrade process, but there are some limitations. Please read through the limitations of the upgrade downgrade process before proceeding to migrate. Please check RFC-78 for more details.
Downgrading
Upgrade is automatic whenever a new Hudi version is used whereas downgrade is a manual step. We need to use the Hudi CLI to downgrade a table from a higher version to lower version. Let's consider an example where we create a table using 0.12.0, upgrade it to 0.13.0 and then downgrade it via Hudi CLI.
Launch spark shell with Hudi 0.11.0 version.
spark-shell \
--packages org.apache.hudi:hudi-spark3.2-bundle_2.12:0.11.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
Create a hudi table by using the scala script below.
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecord
import org.apache.hudi.common.table.timeline.HoodieTimeline
import org.apache.hudi.common.fs.FSUtils
import org.apache.hudi.HoodieDataSourceHelpers
val dataGen = new DataGenerator
val tableType = MOR_TABLE_TYPE_OPT_VAL
val basePath = "file:///tmp/hudi_table"
val tableName = "hudi_table"
val inserts = convertToStringList(dataGen.generateInserts(100)).toList
val insertDf = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
insertDf.write.format("hudi").
options(getQuickstartWriteConfigs).
option("hoodie.table.ordering.fields", "ts").
option("hoodie.datasource.write.recordkey.field", "uuid").
option("hoodie.datasource.write.partitionpath.field", "partitionpath").
option("hoodie.table.name", tableName).
option("hoodie.datasource.write.operation", "insert").
mode(Append).
save(basePath)
You will see an entry for table version in hoodie.properties which states the table version is 4.
bash$ cat /tmp/hudi_table/.hoodie/hoodie.properties | grep hoodie.table.version
hoodie.table.version=4
Launch a new spark shell using version 0.13.0 and append to the same table using the script above. Note the upgrade happens automatically with the new version.
spark-shell \
--packages org.apache.hudi:hudi-spark3.2-bundle_2.12:0.13.1 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
After upgrade, the table version is updated to 5.
bash$ cat /tmp/hudi_table/.hoodie/hoodie.properties | grep hoodie.table.version
hoodie.table.version=5
Lets try downgrading the table back to version 4. For downgrading we will need to use Hudi CLI and execute downgrade. For more details on downgrade, please refer documentation here.
connect --path /tmp/hudi_table
downgrade table --toVersion 4
After downgrade, the table version is updated to 4.
bash$ cat /tmp/hudi_table/.hoodie/hoodie.properties | grep hoodie.table.version
hoodie.table.version=4
Migrating
Currently migrating to Hudi can be done using two approaches
- Convert newer partitions to Hudi : This model is suitable for large event tables (e.g: click streams, ad impressions), which also typically receive writes for the last few days alone. You can convert the last N partitions to Hudi and proceed writing as if it were a Hudi table to begin with. The Hudi query side code is able to correctly handle both hudi and non-hudi data partitions.
- Full conversion to Hudi : This model is suitable if you are currently bulk/full loading the table few times a day (e.g database ingestion). The full conversion of Hudi is simply a one-time step (akin to 1 run of your existing job), which moves all of the data into the Hudi format and provides the ability to incrementally update for future writes.
For more details, refer to the detailed migration guide. In the future, we will be supporting seamless zero-copy bootstrap of existing tables with all the upsert/incremental query capabilities fully supported.