54 posts tagged with "how-to"
View All Tags
Automate schema evolution at scale with Apache Hudi in AWS Glue | Amazon Web Services

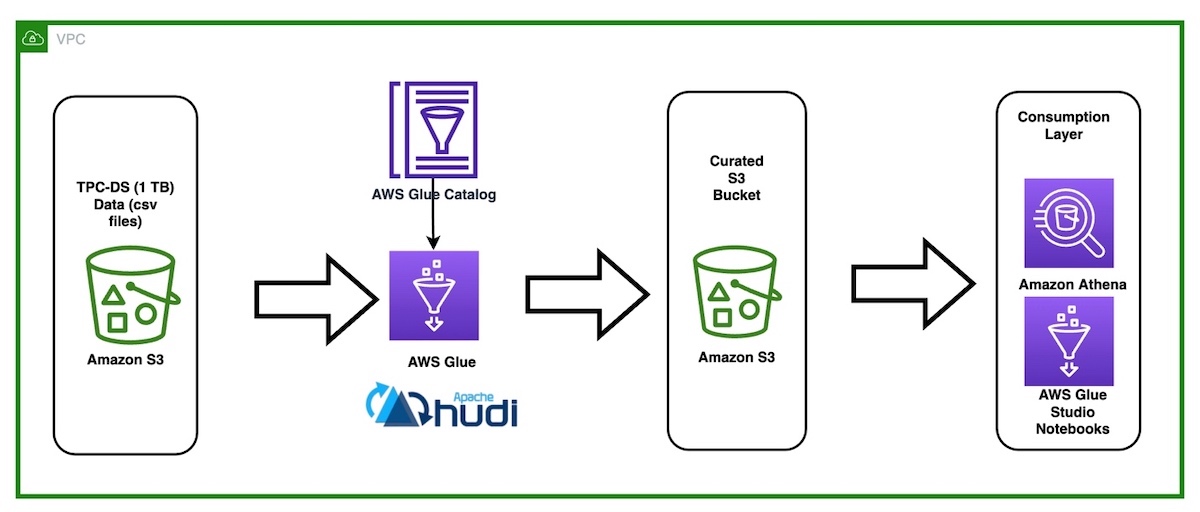
Build Your First Hudi Lakehouse with AWS S3 and AWS Glue
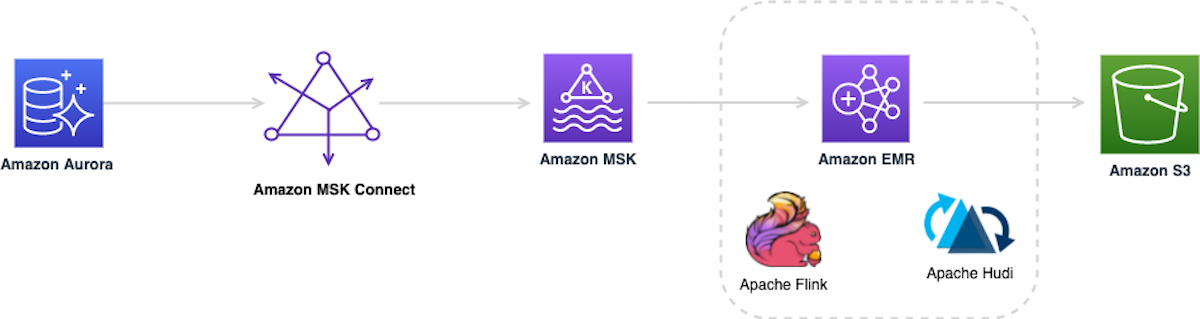
Build your Apache Hudi data lake on AWS using Amazon EMR – Part 1
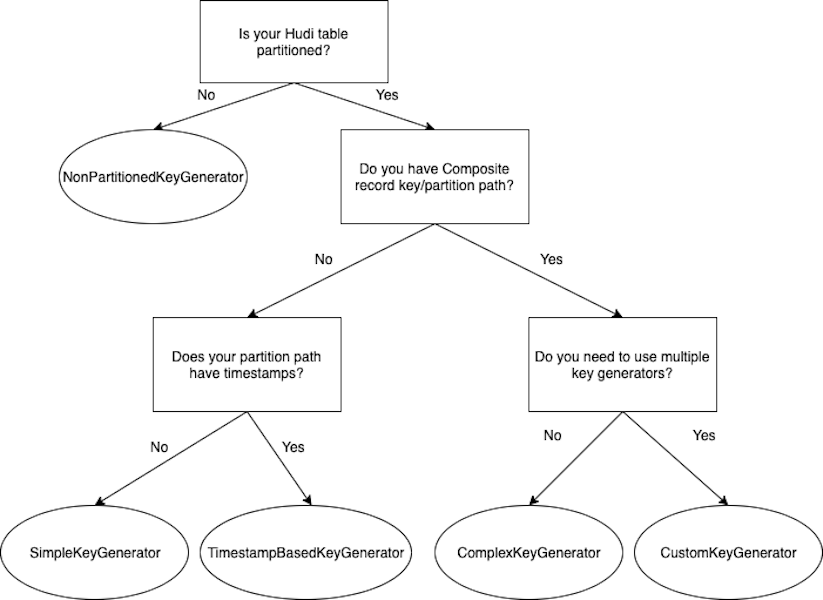
Get started with Apache Hudi using AWS Glue by implementing key design concepts – Part 1
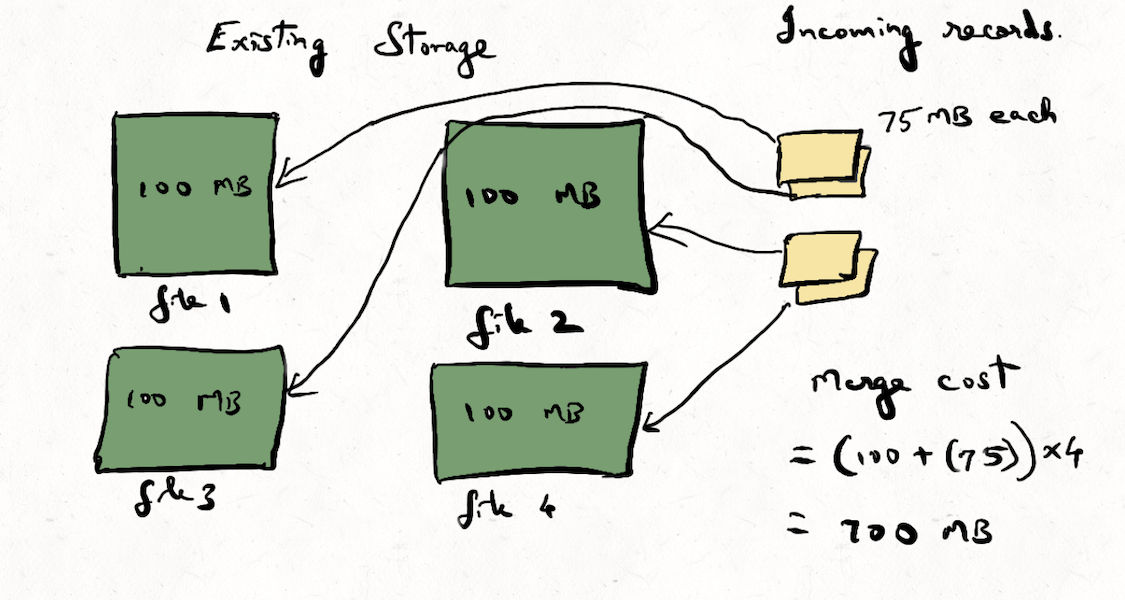
What, Why and How : Apache Hudi’s Bloom Index
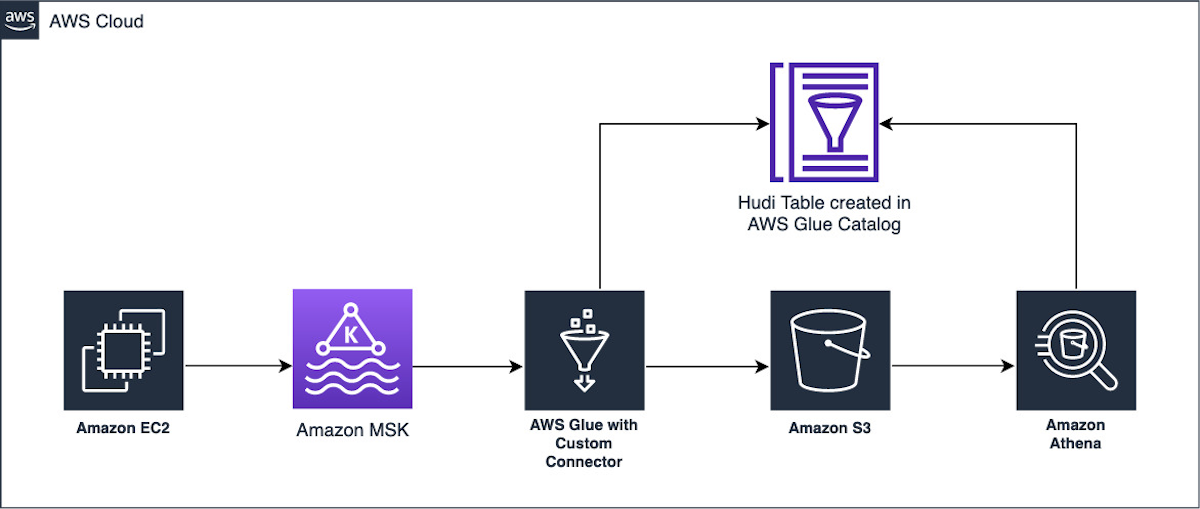
Ingest streaming data to Apache Hudi tables using AWS Glue and Apache Hudi DeltaStreamer

Data processing with Spark: time traveling

Building Streaming Data Lakes with Hudi and MinIO
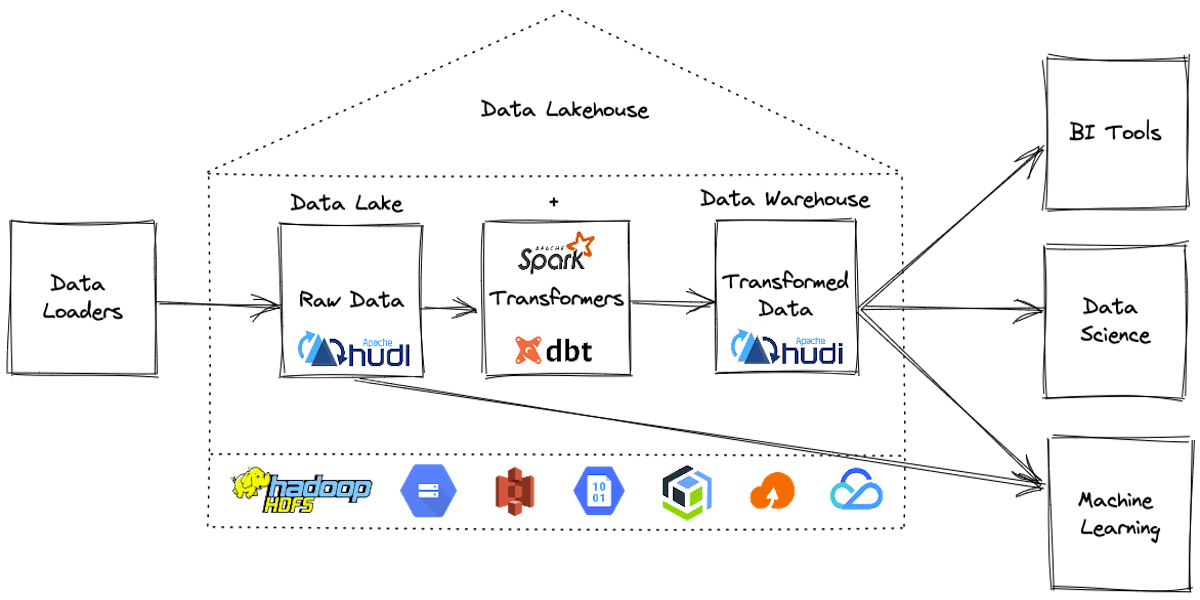
Build Open Lakehouse using Apache Hudi & dbt
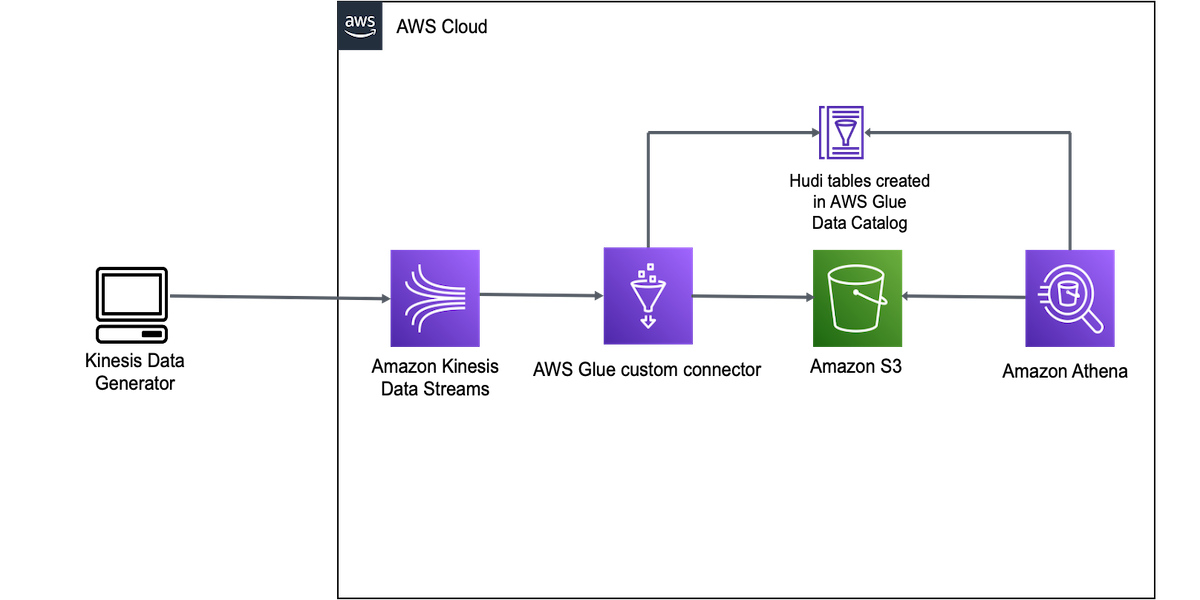
Build a serverless pipeline to analyze streaming data using AWS Glue, Apache Hudi, and Amazon S3