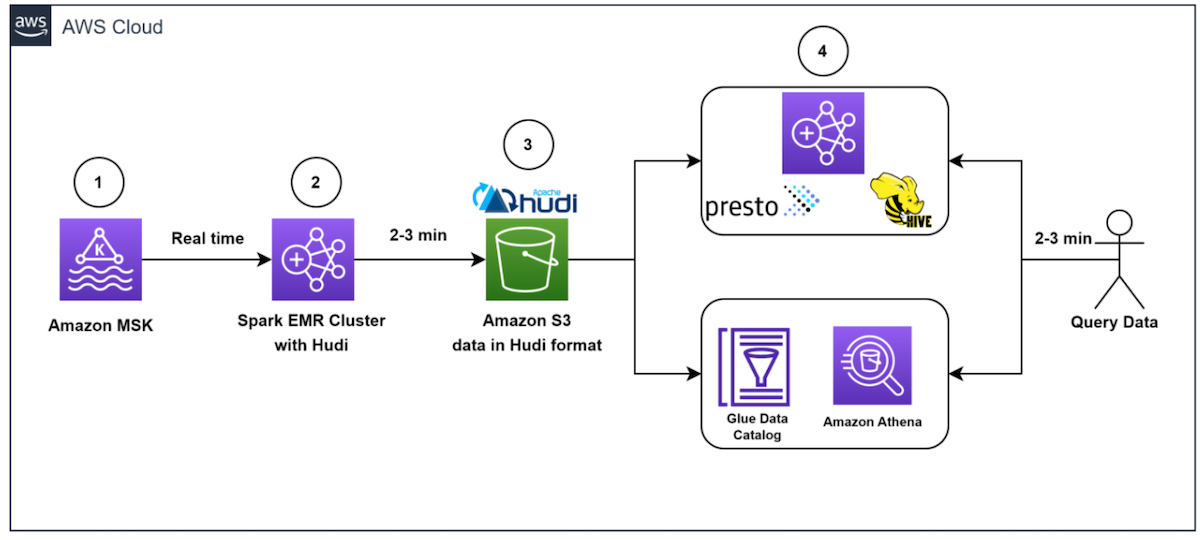
Ingesting data to Apache Hudi using Spark sql

Top 3 Things You Can Do to Get Fast Upsert Performance in Apache Hudi

Amazon Athena now supports Apache Hudi 0.12.2

Lakehouse at Fortune 1 Scale

An Introduction to the Hudi and Flink Integration
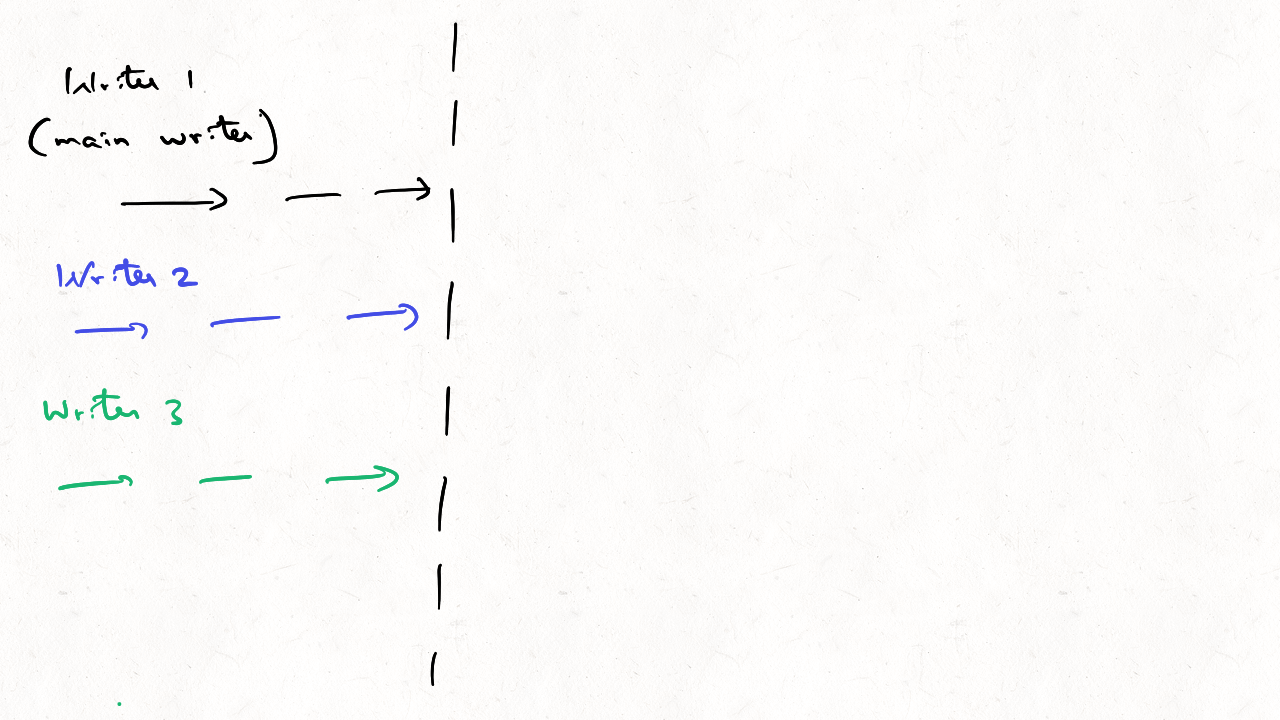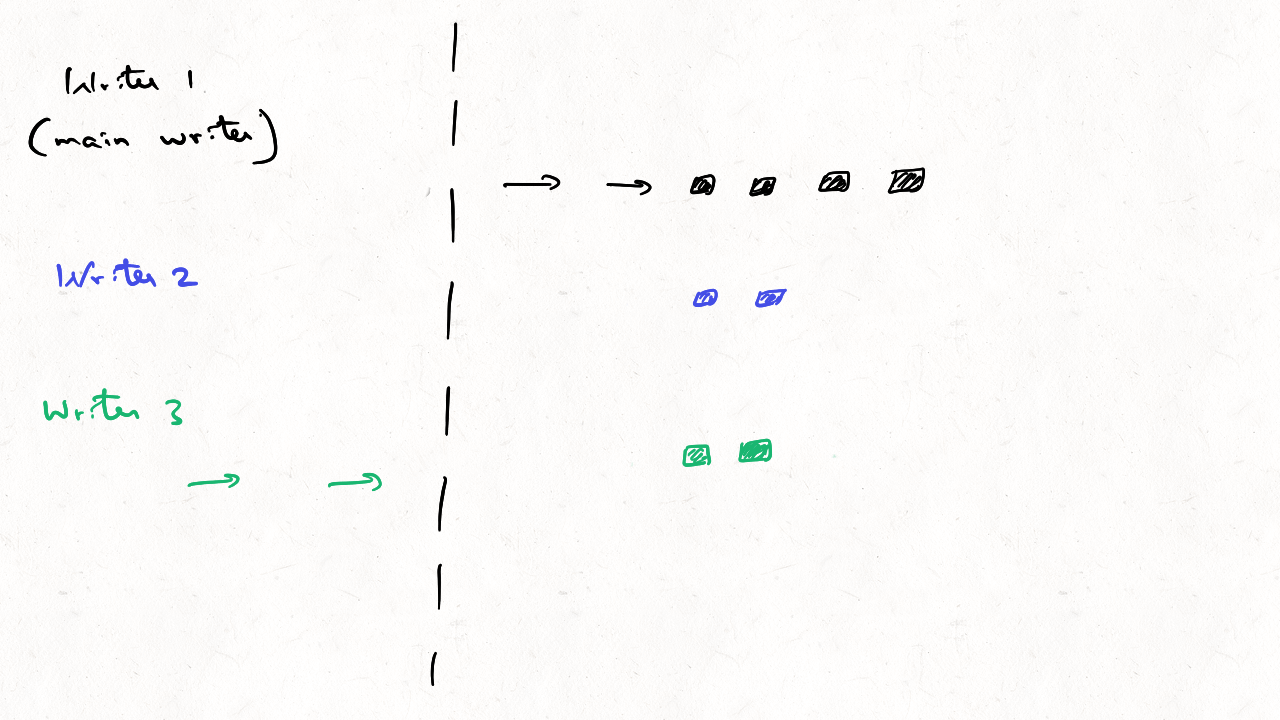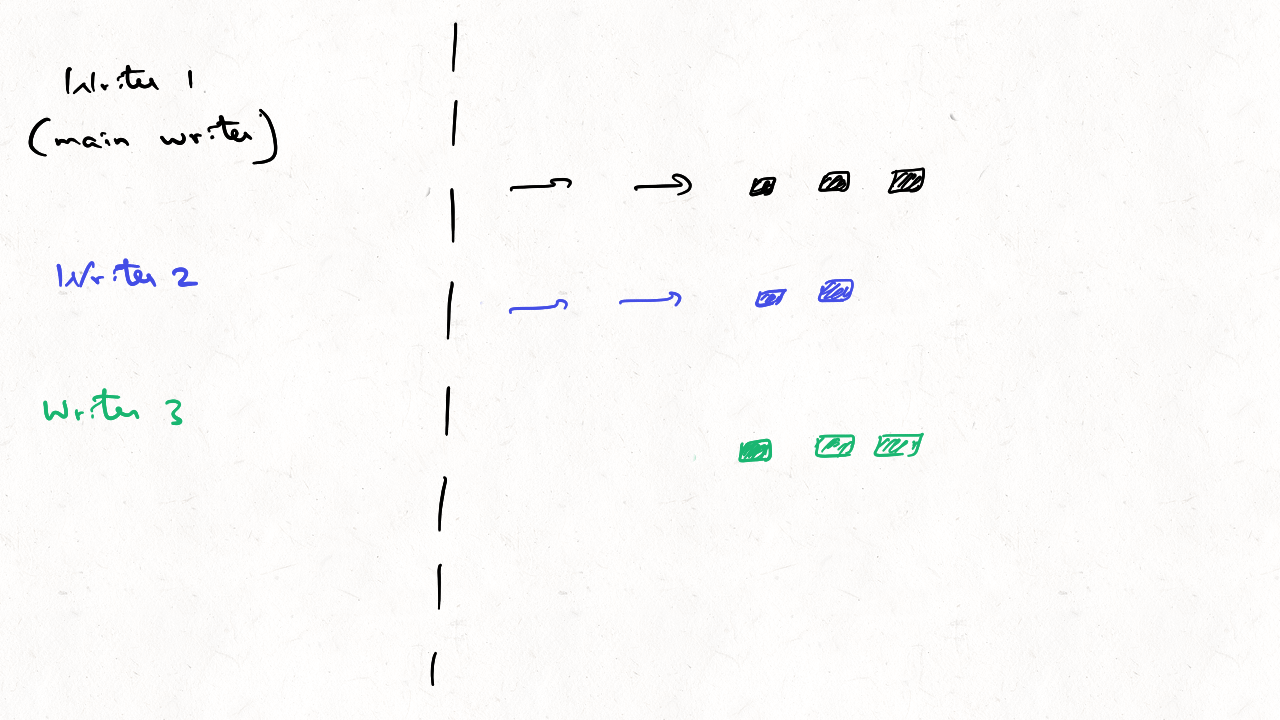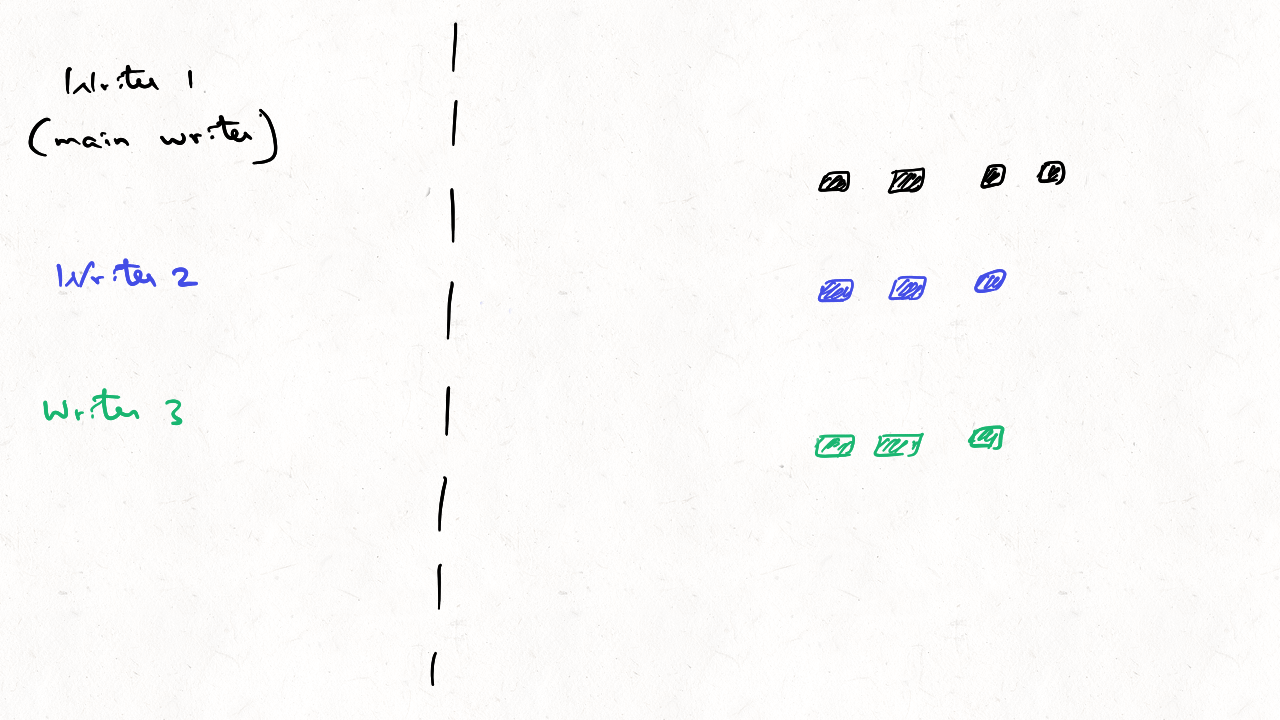
Can you concurrently write data to Apache Hudi w/o any lock provider?

Delta, Hudi, and Iceberg: The Data Lakehouse Trifecta
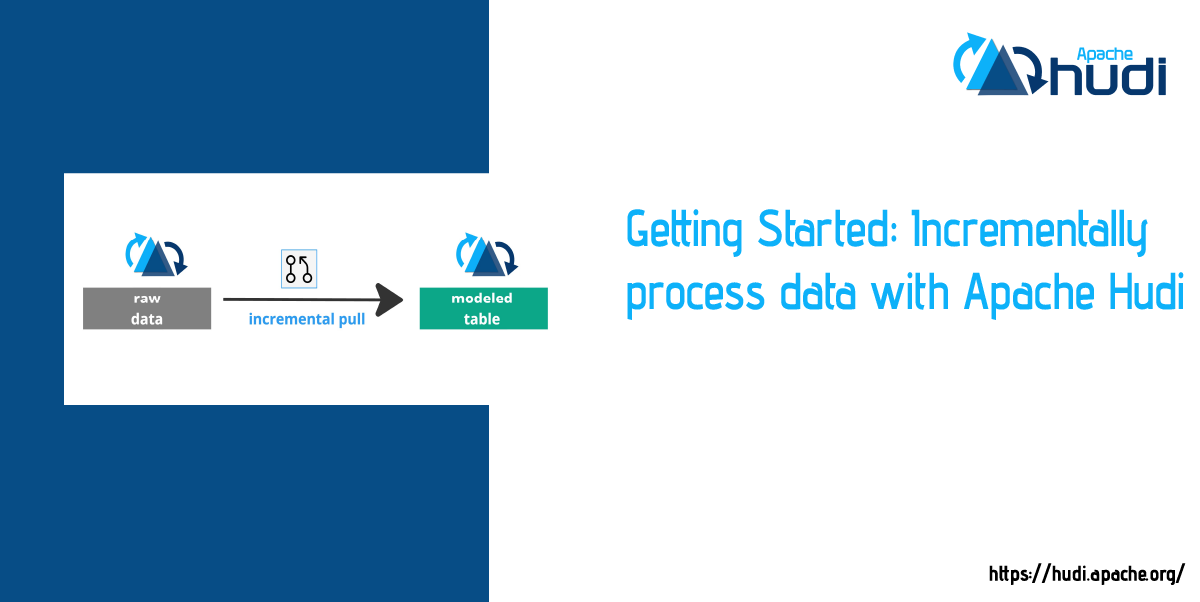
Getting Started: Incrementally process data with Apache Hudi
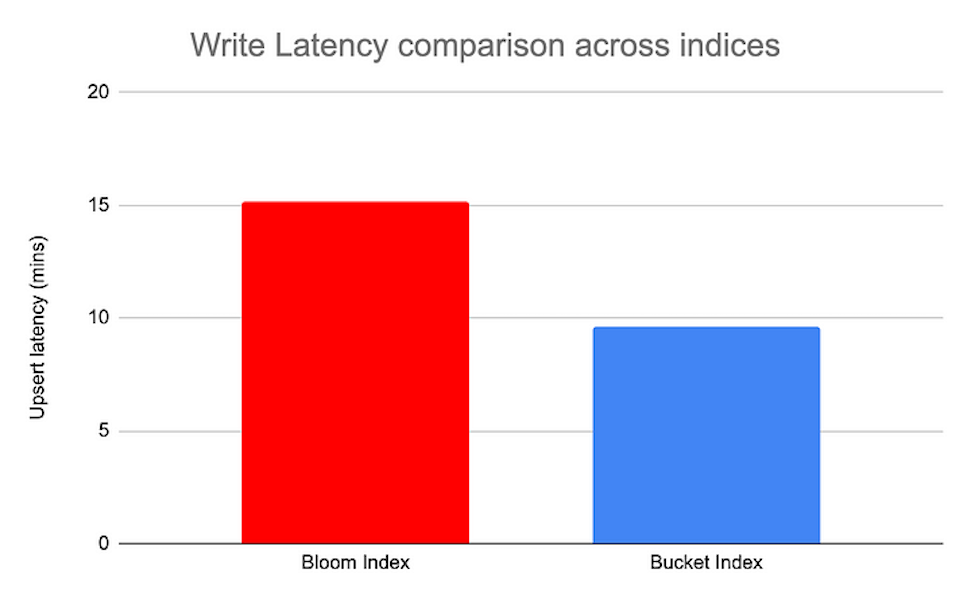
Speed up your write latencies using Bucket Index in Apache Hudi
Global vs Non-global index in Apache Hudi