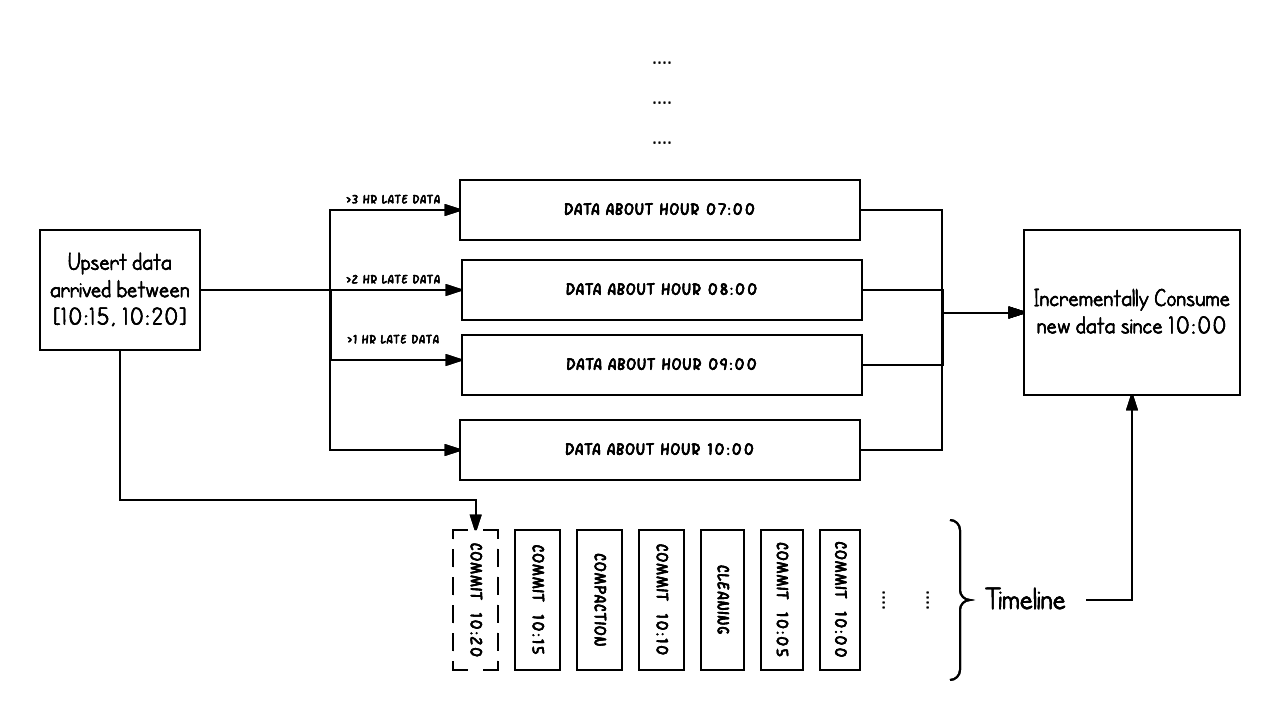
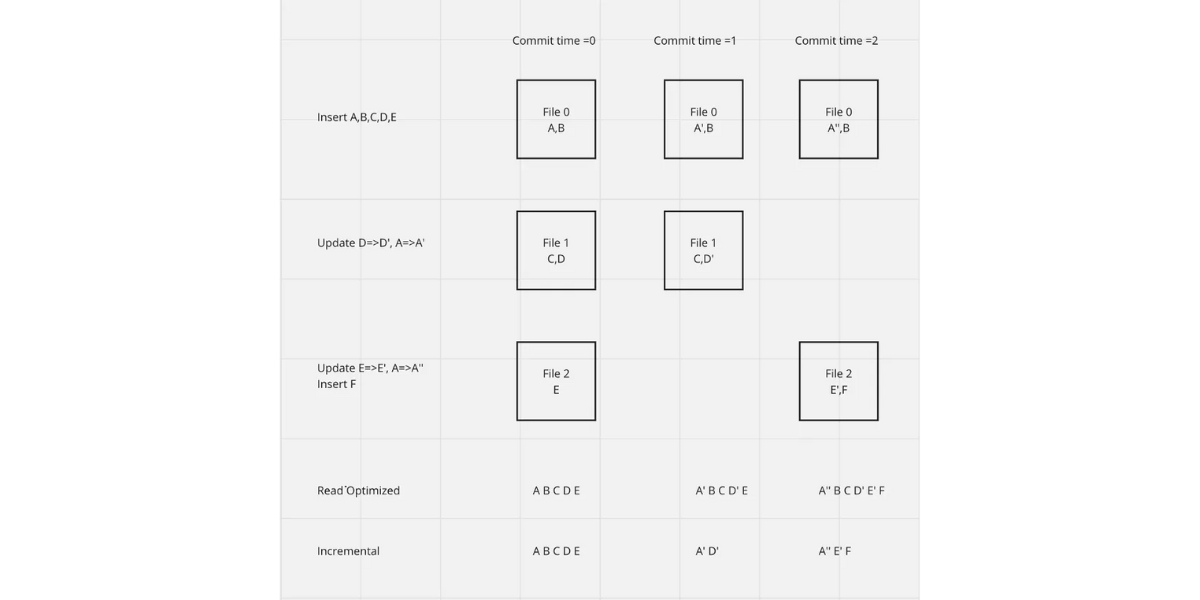
Exploring various storage types in Apache Hudi

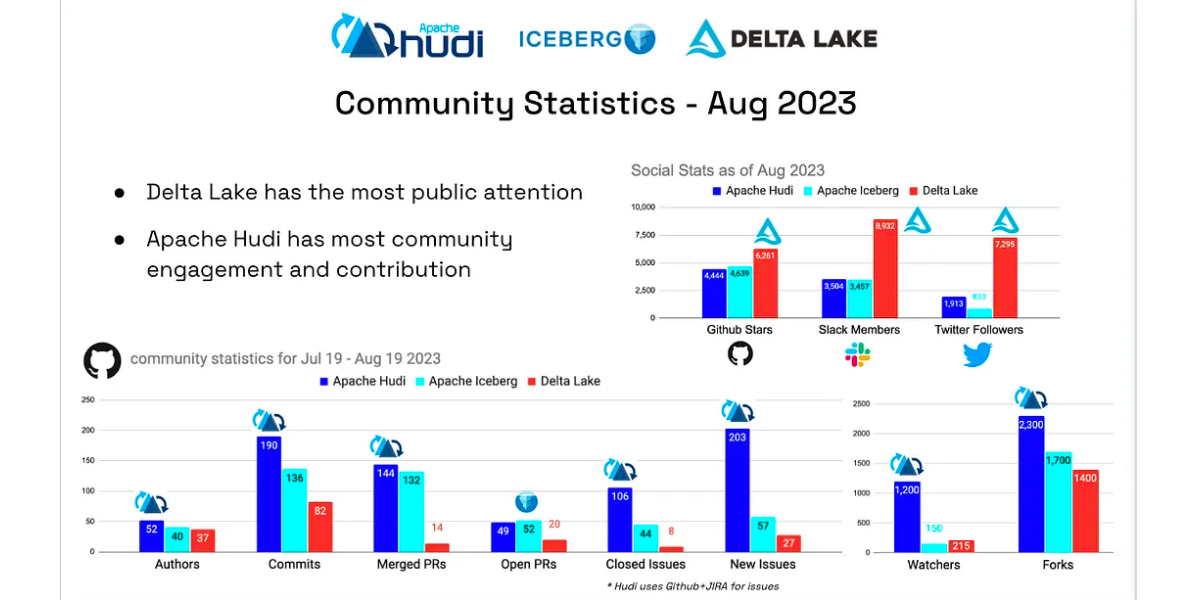
Lakehouse Trifecta — Delta Lake, Apache Iceberg & Apache Hudi

Data Lakehouse Architecture for Big Data with Apache Hudi
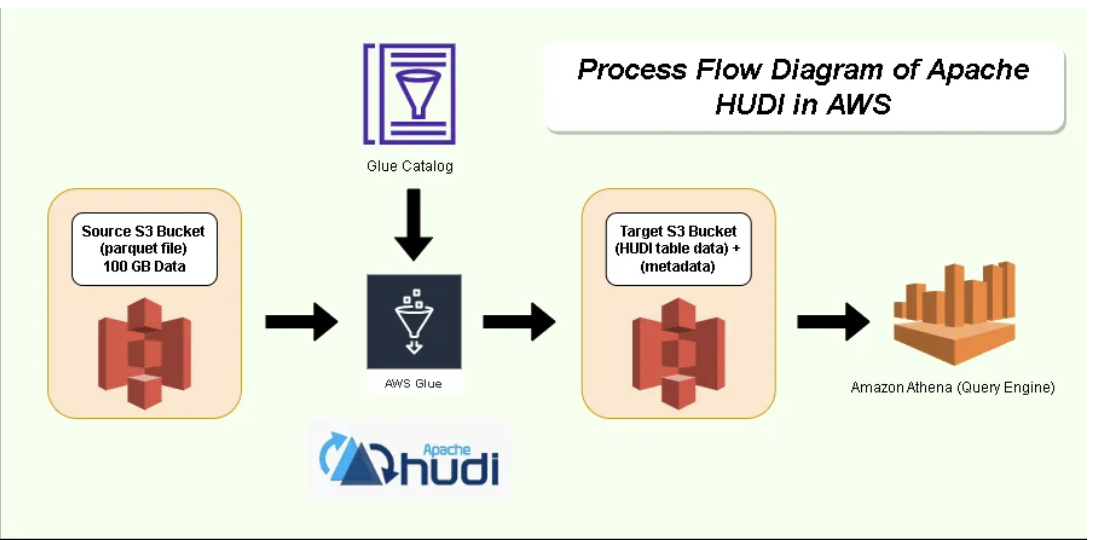
Apache Hudi on AWS Glue: A Step-by-Step Guide
Create an Apache Hudi-based-near-real-time transactional data lake using AWS DMS, Amazon Kinesis, AWS Glue streaming ETL, and data visualization using Amazon QuickSight

Data lake Table formats: Apache Iceberg vs Apache Hudi vs Delta lake

Apache Hudi: Revolutionizing Big Data Management for Real-Time Analytics

AWS Glue Crawlers now supports Apache Hudi Tables
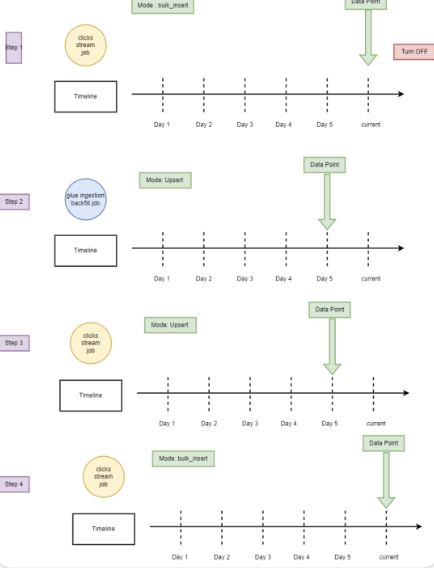
Backfilling Apache Hudi Tables in Production: Techniques & Approaches Using AWS Glue by Job Target LLC