Streaming Responsibly - How Apache Hudi maintains optimum sized files
Apache Hudi is a data lake platform technology that provides several functionalities needed to build and manage data lakes. One such key feature that hudi provides is self-managing file sizing so that users don’t need to worry about manual table maintenance. Having a lot of small files will make it harder to achieve good query performance, due to query engines having to open/read/close files way too many times, to plan and execute queries. But for streaming data lake use-cases, inherently ingests are going to end up having smaller volume of writes, which might result in lot of small files if no special handling is done.
During Write vs After Write
Common approaches to writing very small files and then later stitching them together solve for system scalability issues posed by small files but might violate query SLA's by exposing small files to them. In fact, you can easily do so on a Hudi table, by running a clustering operation, as detailed in a previous blog.
In this blog, we discuss file sizing optimizations in Hudi, during the initial write time, so we don't have to effectively re-write all data again, just for file sizing. If you want to have both (a) self managed file sizing and (b) Avoid exposing small files to queries, automatic file sizing feature saves the day.
Hudi has the ability to maintain a configured target file size, when performing inserts/upsert operations.
(Note: bulk_insert operation does not provide this functionality and is designed as a simpler replacement for
normal spark.write.parquet).
Configs
For illustration purposes, we are going to consider only COPY_ON_WRITE table.
Configs of interest before we dive into the algorithm:
- Max file size: Max size for a given data file. Hudi will try to maintain file sizes to this configured value
- Soft file limit: Max file size below which a given data file is considered to a small file
- Insert split size: Number of inserts grouped for a single partition. This value should match the number of records in a single file (you can determine based on max file size and per record size)
For instance, if your first config value is 120MB and 2nd config value is set to 100MB, any file whose size is < 100MB would be considered a small file.
If you wish to turn off this feature, set the config value for soft file limit to 0.
Example
Let’s say this is the layout of data files for a given partition.
 Figure: Initial data file sizes for a given partition of interest
Figure: Initial data file sizes for a given partition of interest
Let’s assume the configured values for max file size and small file size limit are 120MB and 100MB. File_1’s current size is 40MB, File_2’s size is 80MB, File_3’s size is 90MB, File_4’s size is 130MB and File_5’s size is 105MB. Let’s see what happens when a new write happens.
Step 1: Assigning updates to files. In this step, We look up the index to find the tagged location and records are assigned to respective files. Note that we assume updates are only going to increase the file size and that would simply result in a much bigger file. When updates lower the file size (by say, nulling out lot of fields), then a subsequent write will deem it a small file.
Step 2: Determine small files for each partition path. The soft file limit config value will be leveraged here to determine eligible small files. In our example, given the config value is set to 100MB, the small files are File_1(40MB) and File_2(80MB) and file_3’s (90MB).
Step 3: Once small files are determined, incoming inserts are assigned to them so that they reach their max capacity of 120MB. File_1 will be ingested with 80MB worth of inserts, file_2 will be ingested with 40MB worth of inserts and File_3 will be ingested with 30MB worth of inserts.
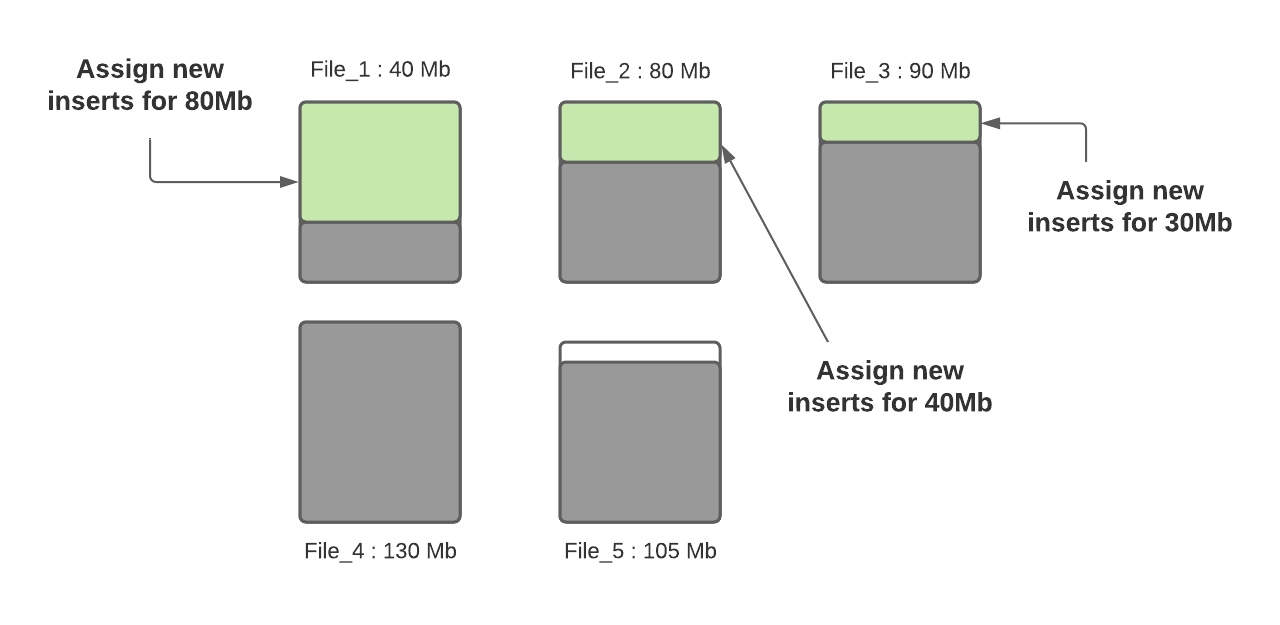 Figure: Incoming records are bin packed to existing small files
Figure: Incoming records are bin packed to existing small files
Step 4: Once all small files are bin packed to its max capacity and if there are pending inserts unassigned, new file groups/data files are created and inserts are assigned to them. Number of records per new data file is determined from insert split size config. Assuming the insert split size is configured to 120k records, if there are 300k remaining records, 3 new files will be created in which 2 of them (File_6 and File_7) will be filled with 120k records and the last one (File_8) will be filled with 60k records (assuming each record is 1000 bytes). In future ingestions, 3rd new file will be considered as a small file to be packed with more data.
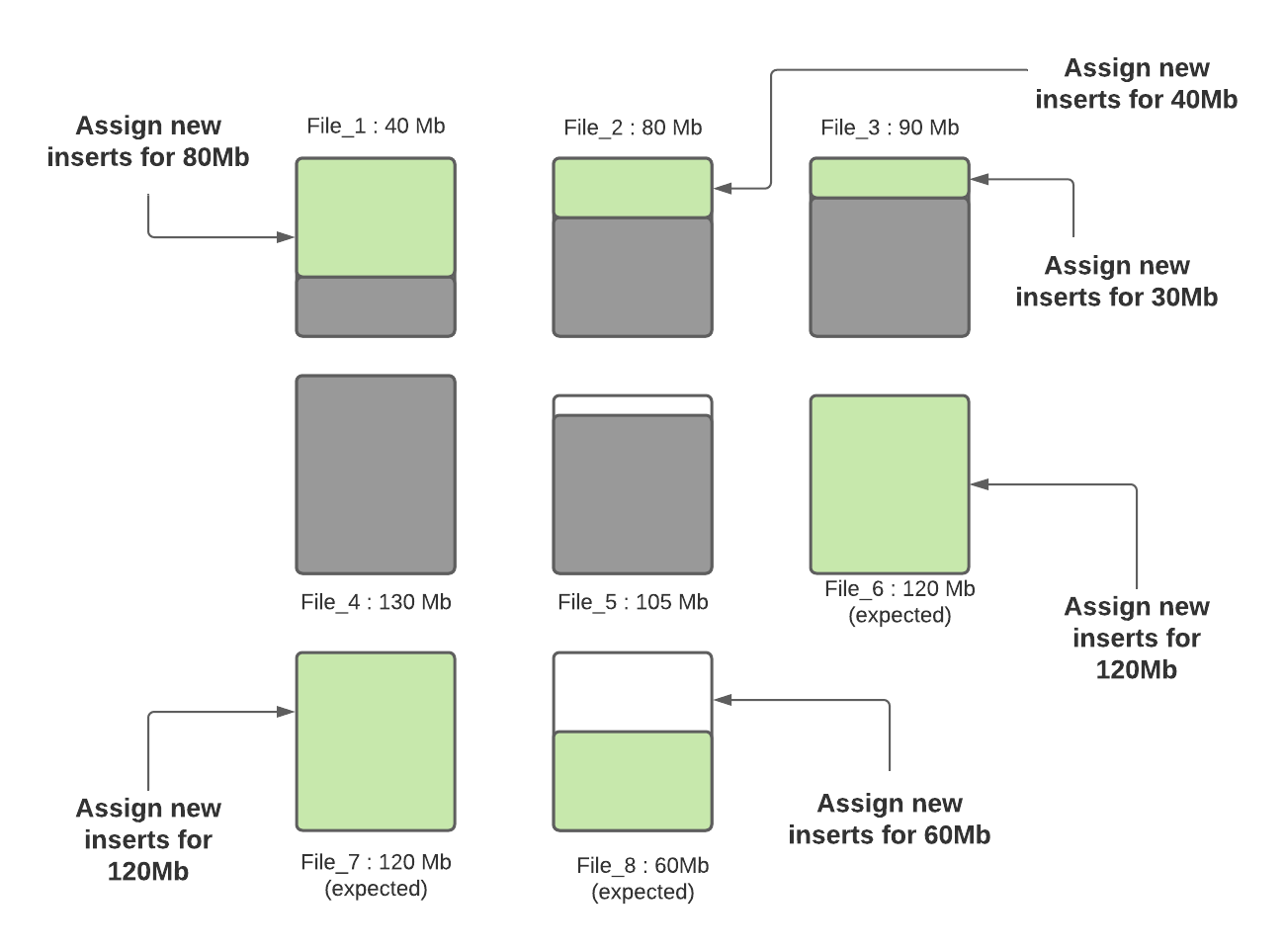 Figure: Remaining records are assigned to new files
Figure: Remaining records are assigned to new files
Hudi leverages mechanisms such as custom partitioning for optimized record distribution to different files, executing the algorithm above. After this round of ingestion is complete, all files except File_8 are nicely sized to the optimum size. This process is followed during every ingestion to ensure there are no small files in your Hudi tables.
Hopefully the blog gave you an overview into how hudi manages small files and assists in boosting your query performance.