Timeline
At its core, Hudi maintains a timeline which is a log of all actions performed on the table at different instants of time that helps provide instantaneous views of the table,
while also efficiently supporting retrieval of data in the order of arrival. A Hudi instant consists of the following components
Instant action: Type of action performed on the tableInstant time: Instant time is typically a timestamp (e.g: 20190117010349), which monotonically increases in the order of action's begin time.state: current state of the instant
Hudi guarantees that the actions performed on the timeline are atomic & timeline consistent based on the instant time.
Atomicity is achieved by relying on the atomic puts to the underlying storage to move the write operations through various states in the timeline.
This is achieved on the underlying DFS (in the case of S3/Cloud Storage, by an atomic PUT operation) and can be observed by files of the pattern <instant>.<action>.<state> in Hudi’s timeline.
Actions
Key actions performed include
COMMITS- A commit denotes an atomic write of a batch of records into a table.CLEANS- Background activity that gets rid of older versions of files in the table, that are no longer needed.DELTA_COMMIT- A delta commit refers to an atomic write of a batch of records into a MergeOnRead type table, where some/all of the data could be just written to delta logs.COMPACTION- Background activity to reconcile differential data structures within Hudi e.g: moving updates from row based log files to columnar formats. Internally, compaction manifests as a special commit on the timelineROLLBACK- Indicates that a commit/delta commit was unsuccessful & rolled back, removing any partial files produced during such a writeSAVEPOINT- Marks certain file groups as "saved", such that cleaner will not delete them. It helps restore the table to a point on the timeline, in case of disaster/data recovery scenarios.
States
Any given instant can be in one of the following states
REQUESTED- Denotes an action has been scheduled, but has not initiatedINFLIGHT- Denotes that the action is currently being performedCOMPLETED- Denotes completion of an action on the timeline
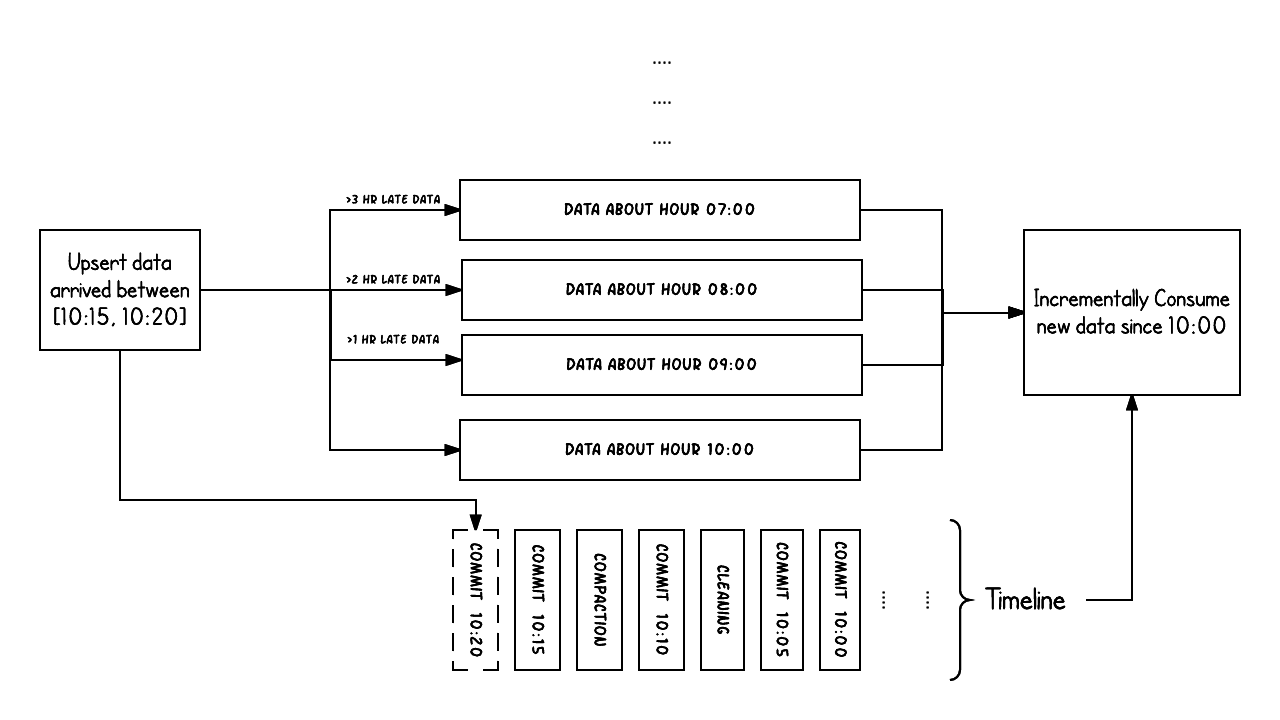
Example above shows upserts happenings between 10:00 and 10:20 on a Hudi table, roughly every 5 mins, leaving commit metadata on the Hudi timeline, along
with other background cleaning/compactions. One key observation to make is that the commit time indicates the arrival time of the data (10:20AM), while the actual data
organization reflects the actual time or event time, the data was intended for (hourly buckets from 07:00). These are two key concepts when reasoning about tradeoffs between latency and completeness of data.
When there is late arriving data (data intended for 9:00 arriving >1 hr late at 10:20), we can see the upsert producing new data into even older time buckets/folders. With the help of the timeline, an incremental query attempting to get all new data that was committed successfully since 10:00 hours, is able to very efficiently consume only the changed files without say scanning all the time buckets > 07:00.
Active and Archived timeline
Hudi divides the entire timeline into active and archived timeline. As the name suggests active timeline is consulted all the time to serve metadata on valid data files and to ensure reads on the timeline does not incur unnecessary latencies as timeline grows, the active timeline needs to be bounded on the metadata (timeline instants) it can serve. To ensure this, after certain thresholds the archival kicks in to move older timeline events to the archived timeline. In general, archival timeline is never contacted for regular operations of the table and is merely used for book-keeping and debugging purposes. Any instants seen under “.hoodie” directory refers to active timeline and those archived goes into “.hoodie/archived” folder.
Archival Configs
Basic configurations that control archival.
Spark write client configs
| Config Name | Default | Description |
|---|---|---|
| hoodie.keep.max.commits | 30 (Optional) | Archiving service moves older entries from timeline into an archived log after each write, to keep the metadata overhead constant, even as the table size grows. This config controls the maximum number of instants to retain in the active timeline. |
| hoodie.keep.min.commits | 20 (Optional) | Similar to hoodie.keep.max.commits, but controls the minimum number of instants to retain in the active timeline. |
For more advanced configs refer here.
Flink Options
Flink jobs using the SQL can be configured through the options in WITH clause. The actual datasource level configs are listed below.
| Config Name | Default | Description |
|---|---|---|
| archive.max_commits | 50 (Optional) | Max number of commits to keep before archiving older commits into a sequential log, default 50Config Param: ARCHIVE_MAX_COMMITS |
| archive.min_commits | 40 (Optional) | Min number of commits to keep before archiving older commits into a sequential log, default 40Config Param: ARCHIVE_MIN_COMMITS |
Refer here for more details.