Using Flink
CDC Ingestion
CDC(change data capture) keep track of the data changes evolving in a source system so a downstream process or system can action that change. We recommend two ways for syncing CDC data into Hudi:
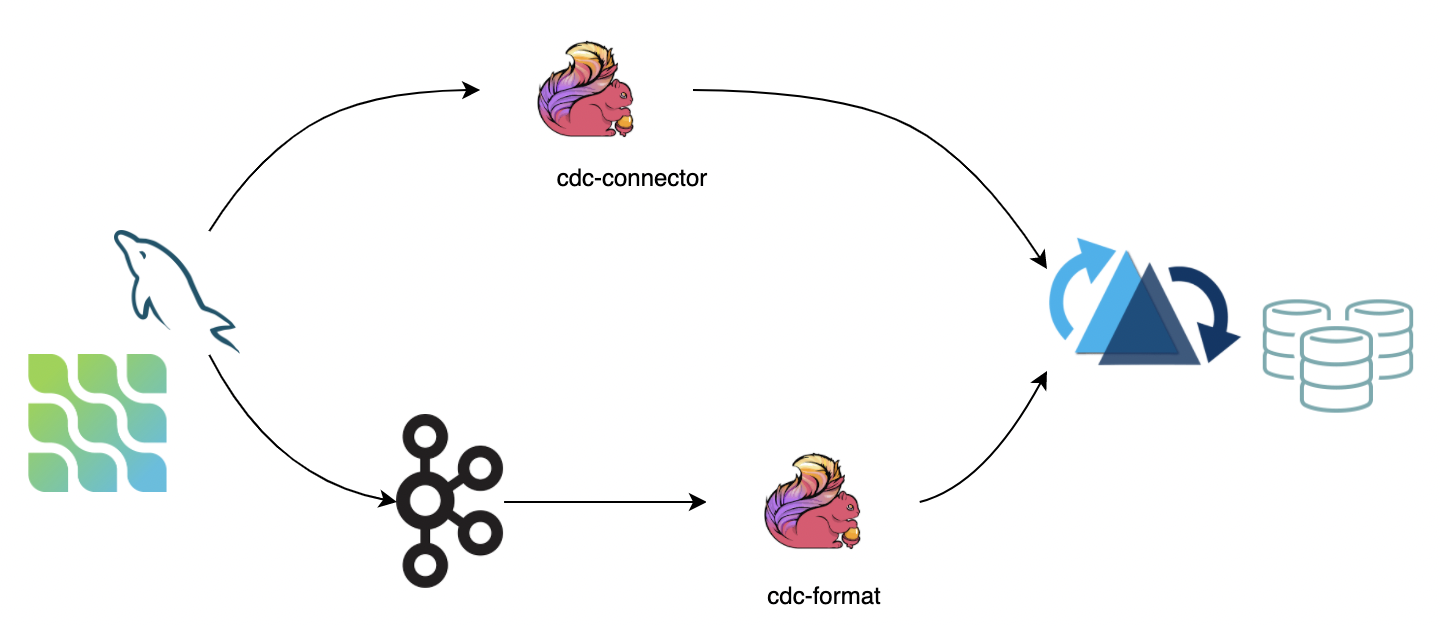
- Using the Ververica flink-cdc-connectors directly connect to DB Server to sync the binlog data into Hudi. The advantage is that it does not rely on message queues, but the disadvantage is that it puts pressure on the db server;
- Consume data from a message queue (for e.g, the Kafka) using the flink cdc format, the advantage is that it is highly scalable, but the disadvantage is that it relies on message queues.
- If the upstream data cannot guarantee the order, you need to specify option
write.precombine.fieldexplicitly;
Bulk Insert
For the demand of snapshot data import. If the snapshot data comes from other data sources, use the bulk_insert mode to quickly
import the snapshot data into Hudi.
bulk_insert eliminates the serialization and data merging. The data deduplication is skipped, so the user need to guarantee the uniqueness of the data.
bulk_insert is more efficient in the batch execution mode. By default, the batch execution mode sorts the input records
by the partition path and writes these records to Hudi, which can avoid write performance degradation caused by
frequent file handle switching.
The parallelism of bulk_insert is specified by write.tasks. The parallelism will affect the number of small files.
In theory, the parallelism of bulk_insert is the number of buckets (In particular, when each bucket writes to maximum file size, it
will rollover to the new file handle. Finally, the number of files >= write.bucket_assign.tasks.
Options
| Option Name | Required | Default | Remarks |
|---|---|---|---|
write.operation | true | upsert | Setting as bulk_insert to open this function |
write.tasks | false | 4 | The parallelism of bulk_insert, the number of files >= write.bucket_assign.tasks |
write.bulk_insert.shuffle_input | false | true | Whether to shuffle data according to the input field before writing. Enabling this option will reduce the number of small files, but there may be a risk of data skew |
write.bulk_insert.sort_input | false | true | Whether to sort data according to the input field before writing. Enabling this option will reduce the number of small files when a write task writes multiple partitions |
write.sort.memory | false | 128 | Available managed memory of sort operator. default 128 MB |
Index Bootstrap
For the demand of snapshot data + incremental data import. If the snapshot data already insert into Hudi by bulk insert.
User can insert incremental data in real time and ensure the data is not repeated by using the index bootstrap function.
If you think this process is very time-consuming, you can add resources to write in streaming mode while writing snapshot data,
and then reduce the resources to write incremental data (or open the rate limit function).
Options
| Option Name | Required | Default | Remarks |
|---|---|---|---|
index.bootstrap.enabled | true | false | When index bootstrap is enabled, the remain records in Hudi table will be loaded into the Flink state at one time |
index.partition.regex | false | * | Optimize option. Setting regular expressions to filter partitions. By default, all partitions are loaded into flink state |
How To Use
CREATE TABLEcreates a statement corresponding to the Hudi table. Note that thetable.typemust be correct.- Setting
index.bootstrap.enabled=trueto enable the index bootstrap function. - Setting Flink checkpoint failure tolerance in
flink-conf.yaml:execution.checkpointing.tolerable-failed-checkpoints = n(depending on Flink checkpoint scheduling times). - Waiting until the first checkpoint succeeds, indicating that the index bootstrap completed.
- After the index bootstrap completed, user can exit and save the savepoint (or directly use the externalized checkpoint).
- Restart the job, setting
index.bootstrap.enableasfalse.
- Index bootstrap is blocking, so checkpoint cannot be completed during index bootstrap.
- Index bootstrap triggers by the input data. User need to ensure that there is at least one record in each partition.
- Index bootstrap executes concurrently. User can search in log by
finish loading the index under partitionandLoad record form fileto observe the progress of index bootstrap. - The first successful checkpoint indicates that the index bootstrap completed. There is no need to load the index again when recovering from the checkpoint.
Changelog Mode
Hudi can keep all the intermediate changes (I / -U / U / D) of messages, then consumes through stateful computing of flink to have a near-real-time data warehouse ETL pipeline (Incremental computing). Hudi MOR table stores messages in the forms of rows, which supports the retention of all change logs (Integration at the format level). All changelog records can be consumed with Flink streaming reader.
Options
| Option Name | Required | Default | Remarks |
|---|---|---|---|
changelog.enabled | false | false | It is turned off by default, to have the upsert semantics, only the merged messages are ensured to be kept, intermediate changes may be merged. Setting to true to support consumption of all changes |
Batch (Snapshot) read still merge all the intermediate changes, regardless of whether the format has stored the intermediate changelog messages.
After setting changelog.enable as true, the retention of changelog records are only best effort: the asynchronous compaction task will merge the changelog records into one record, so if the
stream source does not consume timely, only the merged record for each key can be read after compaction. The solution is to reserve some buffer time for the reader by adjusting the compaction strategy, such as
the compaction options: compaction.delta_commits and compaction.delta_seconds.
Append Mode
For INSERT mode write operation, the current work flow is:
- For Merge_On_Read table, the small file strategies are by default applied: tries to append to the small avro log files first
- For Copy_On_Write table, write new parquet files directly, no small file strategies are applied
Hudi supports rich clustering strategies to optimize the files layout for INSERT mode:
Inline Clustering
Only Copy_On_Write table is supported.
| Option Name | Required | Default | Remarks |
|---|---|---|---|
write.insert.cluster | false | false | Whether to merge small files while ingesting, for COW table, open the option to enable the small file merging strategy(no deduplication for keys but the throughput will be affected) |
Async Clustering
| Option Name | Required | Default | Remarks |
|---|---|---|---|
clustering.schedule.enabled | false | false | Whether to schedule clustering plan during write process, by default false |
clustering.delta_commits | false | 4 | Delta commits to schedule the clustering plan, only valid when clustering.schedule.enabled is true |
clustering.async.enabled | false | false | Whether to execute clustering plan asynchronously, by default false |
clustering.tasks | false | 4 | Parallelism of the clustering tasks |
clustering.plan.strategy.target.file.max.bytes | false | 1024*1024*1024 | The target file size for clustering group, by default 1GB |
clustering.plan.strategy.small.file.limit | false | 600 | The file that has less size than the threshold (unit MB) are candidates for clustering |
clustering.plan.strategy.sort.columns | false | N/A | The columns to sort by when clustering |
Clustering Plan Strategy
Custom clustering strategy is supported.
| Option Name | Required | Default | Remarks |
|---|---|---|---|
clustering.plan.partition.filter.mode | false | NONE | Valid options 1) NONE: no limit; 2) RECENT_DAYS: choose partitions that represent recent days; 3) SELECTED_PARTITIONS: specific partitions |
clustering.plan.strategy.daybased.lookback.partitions | false | 2 | Valid for RECENT_DAYS mode |
clustering.plan.strategy.cluster.begin.partition | false | N/A | Valid for SELECTED_PARTITIONS mode, specify the partition to begin with(inclusive) |
clustering.plan.strategy.cluster.end.partition | false | N/A | Valid for SELECTED_PARTITIONS mode, specify the partition to end with(inclusive) |
clustering.plan.strategy.partition.regex.pattern | false | N/A | The regex to filter the partitions |
clustering.plan.strategy.partition.selected | false | N/A | Specific partitions separated by comma , |
Bucket Index
By default, flink uses the state-backend to keep the file index: the mapping from primary key to fileId. When the input data set is large, there is possibility the cost of the state be a bottleneck, the bucket index use deterministic hash algorithm for shuffling the records into buckets, thus can avoid the storage and query overhead of indexes.
Options
| Option Name | Required | Default | Remarks |
|---|---|---|---|
index.type | false | FLINK_STATE | Set up as BUCKET to use bucket index |
hoodie.bucket.index.hash.field | false | Primary key | Can be a subset of the primary key |
hoodie.bucket.index.num.buckets | false | 4 | The number of buckets per-partition, it is immutable once set up |
Comparing to state index:
- Bucket index has no computing and storage cost of state-backend index, thus has better performance
- Bucket index can not expand the buckets dynamically, the state-backend index can expand the buckets dynamically based on current file layout
- Bucket index can not handle changes among partitions(no limit if the input itself is CDC stream), state-backend index has no limit
Rate Limit
There are many use cases that user put the full history data set onto the message queue together with the realtime incremental data. Then they consume the data from the queue into the hudi from the earliest offset using flink. Consuming history data set has these characteristics: 1). The instant throughput is huge 2). It has serious disorder (with random writing partitions). It will lead to degradation of writing performance and throughput glitches. For this case, the speed limit parameter can be turned on to ensure smooth writing of the flow.
Options
| Option Name | Required | Default | Remarks |
|---|---|---|---|
write.rate.limit | false | 0 | Default disable the rate limit |