Clustering
Background
Apache Hudi brings stream processing to big data, providing fresh data while being an order of magnitude efficient over traditional batch processing. In a data lake/warehouse, one of the key trade-offs is between ingestion speed and query performance. Data ingestion typically prefers small files to improve parallelism and make data available to queries as soon as possible. However, query performance degrades poorly with a lot of small files. Also, during ingestion, data is typically co-located based on arrival time. However, the query engines perform better when the data frequently queried is co-located together. In most architectures each of these systems tend to add optimizations independently to improve performance which hits limitations due to un-optimized data layouts. This doc introduces a new kind of table service called clustering [RFC-19] to reorganize data for improved query performance without compromising on ingestion speed.
How is compaction different from clustering?
Hudi is modeled like a log-structured storage engine with multiple versions of the data. Particularly, Merge-On-Read tables in Hudi store data using a combination of base file in columnar format and row-based delta logs that contain updates. Compaction is a way to merge the delta logs with base files to produce the latest file slices with the most recent snapshot of data. Compaction helps to keep the query performance in check (larger delta log files would incur longer merge times on query side). On the other hand, clustering is a data layout optimization technique. One can stitch together small files into larger files using clustering. Additionally, data can be clustered by sort key so that queries can take advantage of data locality.
Clustering Architecture
At a high level, Hudi provides different operations such as insert/upsert/bulk_insert through it’s write client API to be able to write data to a Hudi table. To be able to choose a trade-off between file size and ingestion speed, Hudi provides a knob hoodie.parquet.small.file.limit to be able to configure the smallest allowable file size. Users are able to configure the small file soft limit to 0 to force new data to go into a new set of filegroups or set it to a higher value to ensure new data gets “padded” to existing files until it meets that limit that adds to ingestion latencies.
To be able to support an architecture that allows for fast ingestion without compromising query performance, we have introduced a ‘clustering’ service to rewrite the data to optimize Hudi data lake file layout.
Clustering table service can run asynchronously or synchronously adding a new action type called “REPLACE”, that will mark the clustering action in the Hudi metadata timeline.
Overall, there are 2 steps to clustering
- Scheduling clustering: Create a clustering plan using a pluggable clustering strategy.
- Execute clustering: Process the plan using an execution strategy to create new files and replace old files.
Schedule clustering
Following steps are followed to schedule clustering.
- Identify files that are eligible for clustering: Depending on the clustering strategy chosen, the scheduling logic will identify the files eligible for clustering.
- Group files that are eligible for clustering based on specific criteria. Each group is expected to have data size in multiples of ‘targetFileSize’. Grouping is done as part of ‘strategy’ defined in the plan. Additionally, there is an option to put a cap on group size to improve parallelism and avoid shuffling large amounts of data.
- Finally, the clustering plan is saved to the timeline in an avro metadata format.
Execute clustering
- Read the clustering plan and get the ‘clusteringGroups’ that mark the file groups that need to be clustered.
- For each group, we instantiate appropriate strategy class with strategyParams (example: sortColumns) and apply that strategy to rewrite the data.
- Create a “REPLACE” commit and update the metadata in HoodieReplaceCommitMetadata.
Clustering Service builds on Hudi’s MVCC based design to allow for writers to continue to insert new data while clustering action runs in the background to reformat data layout, ensuring snapshot isolation between concurrent readers and writers.
NOTE: Clustering can only be scheduled for tables / partitions not receiving any concurrent updates. In the future, concurrent updates use-case will be supported as well.
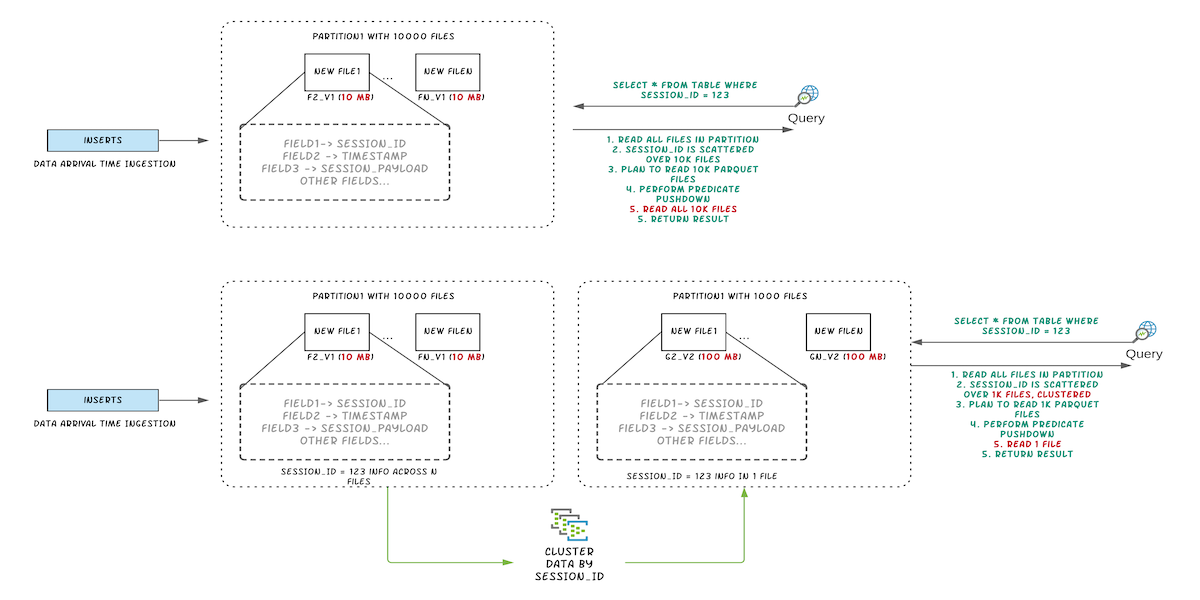 Figure: Illustrating query performance improvements by clustering
Figure: Illustrating query performance improvements by clustering
Clustering Usecases
Batching small files
As mentioned in the intro, streaming ingestion generally results in smaller files in your data lake. But having a lot of such small files could lead to higher query latency. From our experience supporting community users, there are quite a few users who are using Hudi just for small file handling capabilities. So, you could employ clustering to batch a lot of such small files into larger ones.
Cluster by sort key
Another classic problem in data lake is the arrival time vs event time problem. Generally you write data based on arrival time, while query predicates do not sit well with it. With clustering, you can re-write your data by sorting based on query predicates and so, your data skipping will be very efficient and your query can ignore scanning a lot of unnecessary data.

Clustering Strategies
On a high level, clustering creates a plan based on a configurable strategy, groups eligible files based on specific criteria and then executes the plan. As mentioned before, clustering plan as well as execution depends on configurable strategy. These strategies can be broadly classified into three types: clustering plan strategy, execution strategy and update strategy.
Plan Strategy
This strategy comes into play while creating clustering plan. It helps to decide what file groups should be clustered and how many output file groups should the clustering produce. Note that these strategies are easily pluggable using the config hoodie.clustering.plan.strategy.class.
Different plan strategies are as follows:
Size-based clustering strategies
This strategy creates clustering groups based on max size allowed per group. Also, it excludes files that are greater
than the small file limit from the clustering plan. Available strategies depending on write client
are: SparkSizeBasedClusteringPlanStrategy, FlinkSizeBasedClusteringPlanStrategy
and JavaSizeBasedClusteringPlanStrategy. Furthermore, Hudi provides flexibility to include or exclude partitions for
clustering, tune the file size limits, maximum number of output groups, as we will see below.
hoodie.clustering.plan.strategy.partition.selected: Comma separated list of partitions to be considered for
clustering.
hoodie.clustering.plan.strategy.partition.regex.pattern: Filters clustering partitions that matched regex pattern.
hoodie.clustering.plan.partition.filter.mode: In addition to previous filtering, we have few additional filtering as
well. Different values for this mode are NONE, RECENT_DAYS and SELECTED_PARTITIONS.
NONE: do not filter table partition and thus the clustering plan will include all partitions that have clustering candidate.RECENT_DAYS: keep a continuous range of partitions, works together with the below configs:hoodie.clustering.plan.strategy.daybased.lookback.partitions: Number of partitions to list to create ClusteringPlan.hoodie.clustering.plan.strategy.daybased.skipfromlatest.partitions: Number of partitions to skip from latest when choosing partitions to create ClusteringPlan. As the name implies, applicable only if partitioning is day based.
SELECTED_PARTITIONS: keep partitions that are in the specified range based on below configs:hoodie.clustering.plan.strategy.cluster.begin.partition: Begin partition used to filter partition (inclusive).hoodie.clustering.plan.strategy.cluster.end.partition: End partition used to filter partition (inclusive).
DAY_ROLLING: cluster partitions on a rolling basis by the hour to avoid clustering all partitions each time.
Small file limit
hoodie.clustering.plan.strategy.small.file.limit: Files smaller than the size in bytes specified here are candidates
for clustering. Larges file groups will be ignored.
Max number of groups
hoodie.clustering.plan.strategy.max.num.groups: Maximum number of groups to create as part of ClusteringPlan.
Increasing groups will increase parallelism. This does not imply the number of output file groups as such. This refers
to clustering groups (parallel tasks/threads that will work towards producing output file groups). Total output file
groups is also determined by based on target file size which we will discuss shortly.
Max bytes per group
hoodie.clustering.plan.strategy.max.bytes.per.group: Each clustering operation can create multiple output file groups.
Total amount of data processed by clustering operation is defined by below two properties (Max bytes per group * Max num
groups. Thus, this config will assist in capping the max amount of data to be included in one group.
Target file size max
hoodie.clustering.plan.strategy.target.file.max.bytes: Each group can produce ’N’ (max group size /target file size)
output file groups.
SparkSingleFileSortPlanStrategy
In this strategy, clustering group for each partition is built in the same way as SparkSizeBasedClusteringPlanStrategy
. The difference is that the output group is 1 and file group id remains the same,
while SparkSizeBasedClusteringPlanStrategy can create multiple file groups with newer fileIds.
SparkConsistentBucketClusteringPlanStrategy
This strategy is specifically used for consistent bucket index. This will be leveraged to expand your bucket index (from static partitioning to dynamic). Typically, users don’t need to use this strategy. Hudi internally uses this for dynamically expanding the buckets for bucket index datasets.
Execution Strategy
After building the clustering groups in the planning phase, Hudi applies execution strategy, for each group, primarily based on sort columns and size. The strategy can be specified using the config hoodie.clustering.execution.strategy.class. By default, Hudi sorts the file groups in the plan by the specified columns, while meeting the configured target file sizes.
The available strategies are as follows:
SPARK_SORT_AND_SIZE_EXECUTION_STRATEGY: Uses bulk_insert to re-write data from input file groups.- Set
hoodie.clustering.execution.strategy.classtoorg.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy. hoodie.clustering.plan.strategy.sort.columns: Columns to sort the data while clustering. This goes in conjunction with layout optimization strategies depending on your query predicates. One can set comma separated list of columns that needs to be sorted in this config.
- Set
JAVA_SORT_AND_SIZE_EXECUTION_STRATEGY: Similar toSPARK_SORT_AND_SIZE_EXECUTION_STRATEGY, for the Java and Flink engines. Sethoodie.clustering.execution.strategy.classtoorg.apache.hudi.client.clustering.run.strategy.JavaSortAndSizeExecutionStrategy.SPARK_CONSISTENT_BUCKET_EXECUTION_STRATEGY: As the name implies, this is applicable to dynamically expand consistent bucket index and only applicable to the Spark engine. Sethoodie.clustering.execution.strategy.classtoorg.apache.hudi.client.clustering.run.strategy.SparkConsistentBucketClusteringExecutionStrategy.
Update Strategy
Currently, clustering can only be scheduled for tables/partitions not receiving any concurrent updates. By default, the config for update strategy is set to SparkRejectUpdateStrategy. If some file group has updates during clustering then it will reject updates and throw an exception. However, in some use-cases updates are very sparse and do not touch most file groups. The default strategy to simply reject updates does not seem fair. In such use-cases, users can set the config to SparkAllowUpdateStrategy.
We discussed the critical strategy configurations. All other configurations related to clustering are listed here. Out of this list, a few configurations that will be very useful for inline or async clustering are shown below with code samples.
Inline clustering
Inline clustering happens synchronously with the regular ingestion writer, which means the next round of ingestion cannot proceed until the clustering is complete. Inline clustering can be setup easily using spark dataframe options. See sample below
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val df = //generate data frame
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, "tableName").
option("hoodie.parquet.small.file.limit", "0").
option("hoodie.clustering.inline", "true").
option("hoodie.clustering.inline.max.commits", "4").
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").
option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").
option("hoodie.clustering.plan.strategy.sort.columns", "column1,column2"). //optional, if sorting is needed as part of rewriting data
mode(Append).
save("dfs://location");
Async Clustering
Async clustering runs the clustering table service in the background without blocking the regular ingestions writers. Hudi supports multi-writers which provides snapshot isolation between multiple table services, thus allowing writers to continue with ingestion while clustering runs in the background.
| Config key | Remarks | Default |
|---|---|---|
hoodie.clustering.async.enabled | Enable running of clustering service, asynchronously as writes happen on the table. | False |
hoodie.clustering.async.max.commits | Control frequency of async clustering by specifying after how many commits clustering should be triggered. | 4 |
hoodie.clustering.preserve.commit.metadata | When rewriting data, preserves existing _hoodie_commit_time. This means users can run incremental queries on clustered data without any side-effects. | False |
Setup Asynchronous Clustering
Users can leverage HoodieClusteringJob to setup 2-step asynchronous clustering.
HoodieClusteringJob
By specifying the scheduleAndExecute mode both schedule as well as clustering can be achieved in the same step.
The appropriate mode can be specified using -mode or -m option. There are three modes:
schedule: Make a clustering plan. This gives an instant which can be passed in execute mode.execute: Execute a clustering plan at a particular instant. If no instant-time is specified, HoodieClusteringJob will execute for the earliest instant on the Hudi timeline.scheduleAndExecute: Make a clustering plan first and execute that plan immediately.
Note that to run this job while the original writer is still running, please enable multi-writing:
hoodie.write.concurrency.mode=optimistic_concurrency_control
hoodie.write.lock.provider=org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider
A sample spark-submit command to setup HoodieClusteringJob is as below:
spark-submit \
--class org.apache.hudi.utilities.HoodieClusteringJob \
/path/to/hudi-utilities-bundle/target/hudi-utilities-bundle_2.12-0.9.0-SNAPSHOT.jar \
--props /path/to/config/clusteringjob.properties \
--mode scheduleAndExecute \
--base-path /path/to/hudi_table/basePath \
--table-name hudi_table_schedule_clustering \
--spark-memory 1g
A sample clusteringjob.properties file:
hoodie.clustering.async.enabled=true
hoodie.clustering.async.max.commits=4
hoodie.clustering.plan.strategy.target.file.max.bytes=1073741824
hoodie.clustering.plan.strategy.small.file.limit=629145600
hoodie.clustering.execution.strategy.class=org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy
hoodie.clustering.plan.strategy.sort.columns=column1,column2
HoodieDeltaStreamer
This brings us to our users' favorite utility in Hudi. Now, we can trigger asynchronous clustering with DeltaStreamer.
Just set the hoodie.clustering.async.enabled config to true and specify other clustering config in properties file
whose location can be pased as —props when starting the deltastreamer (just like in the case of HoodieClusteringJob).
A sample spark-submit command to setup HoodieDeltaStreamer is as below:
spark-submit \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
/path/to/hudi-utilities-bundle/target/hudi-utilities-bundle_2.12-0.9.0-SNAPSHOT.jar \
--props /path/to/config/clustering_kafka.properties \
--schemaprovider-class org.apache.hudi.utilities.schema.SchemaRegistryProvider \
--source-class org.apache.hudi.utilities.sources.AvroKafkaSource \
--source-ordering-field impresssiontime \
--table-type COPY_ON_WRITE \
--target-base-path /path/to/hudi_table/basePath \
--target-table impressions_cow_cluster \
--op INSERT \
--hoodie-conf hoodie.clustering.async.enabled=true \
--continuous
Spark Structured Streaming
We can also enable asynchronous clustering with Spark structured streaming sink as shown below.
val commonOpts = Map(
"hoodie.insert.shuffle.parallelism" -> "4",
"hoodie.upsert.shuffle.parallelism" -> "4",
DataSourceWriteOptions.RECORDKEY_FIELD.key -> "_row_key",
DataSourceWriteOptions.PARTITIONPATH_FIELD.key -> "partition",
DataSourceWriteOptions.PRECOMBINE_FIELD.key -> "timestamp",
HoodieWriteConfig.TBL_NAME.key -> "hoodie_test"
)
def getAsyncClusteringOpts(isAsyncClustering: String,
clusteringNumCommit: String,
executionStrategy: String):Map[String, String] = {
commonOpts + (DataSourceWriteOptions.ASYNC_CLUSTERING_ENABLE.key -> isAsyncClustering,
HoodieClusteringConfig.ASYNC_CLUSTERING_MAX_COMMITS.key -> clusteringNumCommit,
HoodieClusteringConfig.EXECUTION_STRATEGY_CLASS_NAME.key -> executionStrategy
)
}
def initStreamingWriteFuture(hudiOptions: Map[String, String]): Future[Unit] = {
val streamingInput = // define the source of streaming
Future {
println("streaming starting")
streamingInput
.writeStream
.format("org.apache.hudi")
.options(hudiOptions)
.option("checkpointLocation", basePath + "/checkpoint")
.mode(Append)
.start()
.awaitTermination(10000)
println("streaming ends")
}
}
def structuredStreamingWithClustering(): Unit = {
val df = //generate data frame
val hudiOptions = getClusteringOpts("true", "1", "org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy")
val f1 = initStreamingWriteFuture(hudiOptions)
Await.result(f1, Duration.Inf)
}