Developer Setup
Pre-requisites
To contribute code, you need
- a GitHub account
- a Linux (or) macOS development environment with Java JDK 8, Apache Maven (3.x+) installed
- Docker installed for running demo, integ tests or building website
- for large contributions, a signed Individual Contributor License Agreement (ICLA) to the Apache Software Foundation (ASF).
- (Recommended) Create an account on JIRA to open issues/find similar issues.
- (Recommended) Join our dev mailing list & slack channel, listed on community page.
IntelliJ Setup
IntelliJ is the recommended IDE for developing Hudi. To contribute, you would need to do the following
-
Fork the Hudi code on Github & then clone your own fork locally. Once cloned, we recommend building as per instructions on spark quickstart or flink quickstart.
-
In IntelliJ, select
File>New>Project from Existing Sources...and select thepom.xmlfile under your local Hudi source folder. -
In
Project Structure, select Java 1.8 as the Project SDK.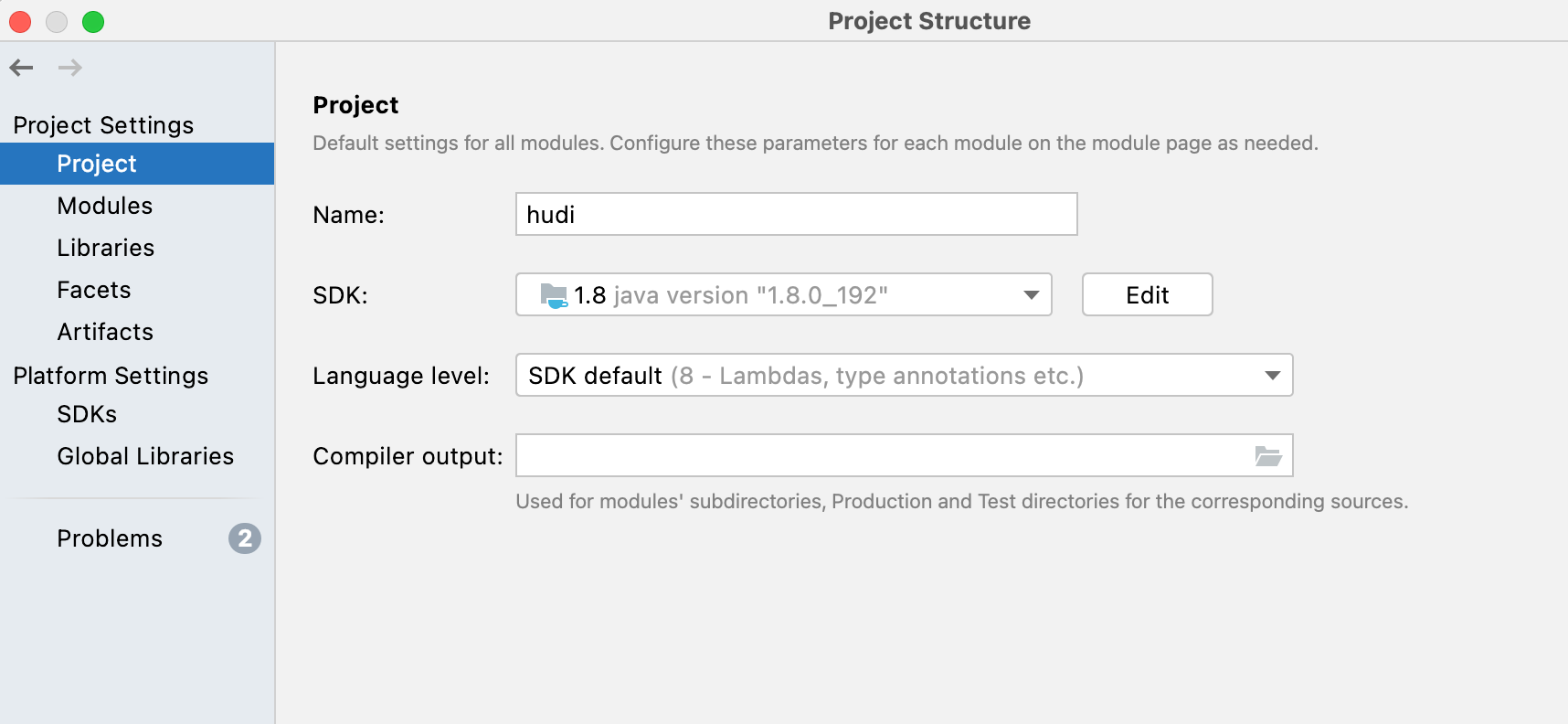
-
Make the following configuration in
PreferencesorSettingsin newer IntelliJ so the Hudi code can compile in the IDE:-
Enable annotation processing in compiler.
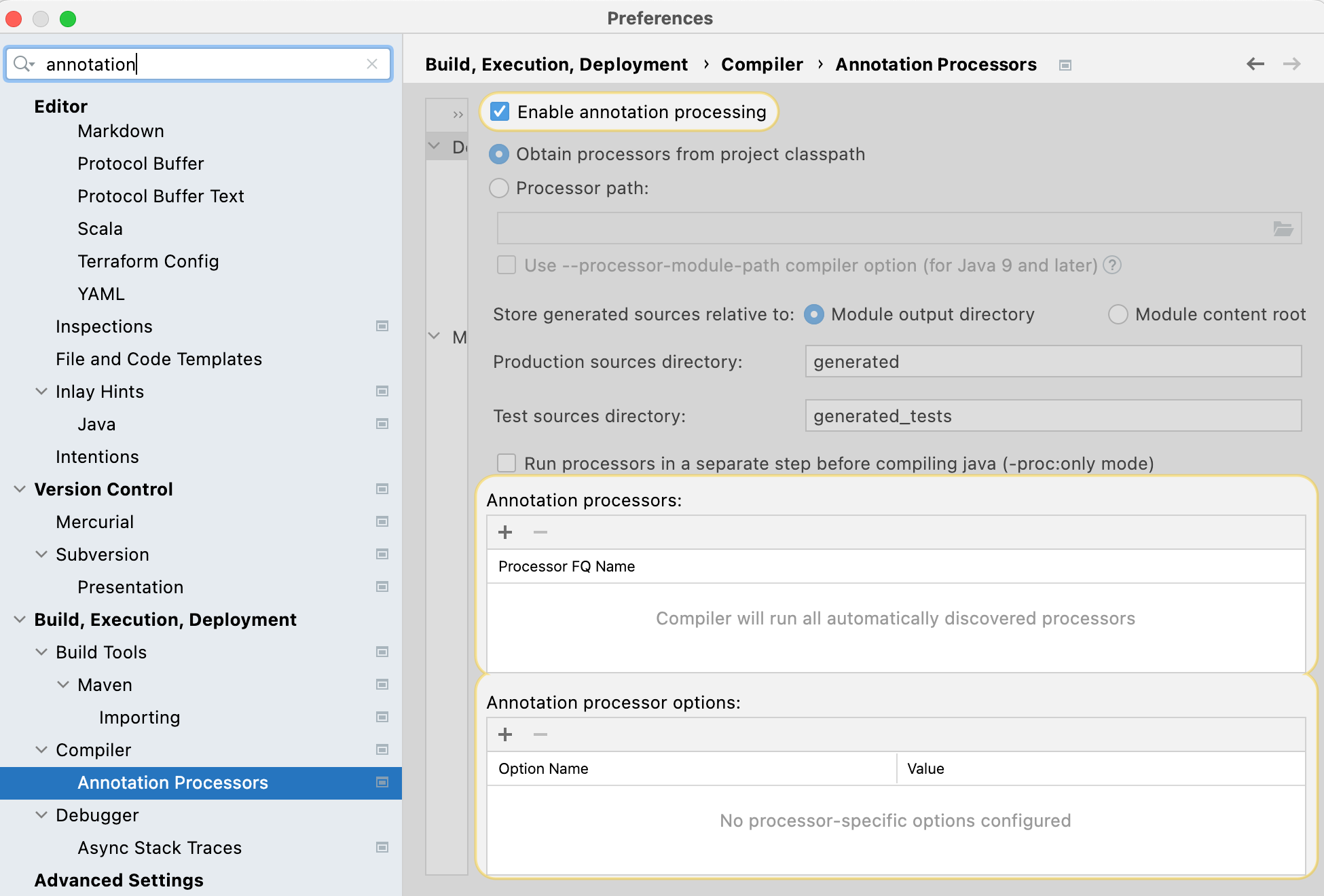
-
Configure Maven NOT to delegate IDE build/run actions to Maven so you can run tests in IntelliJ directly.
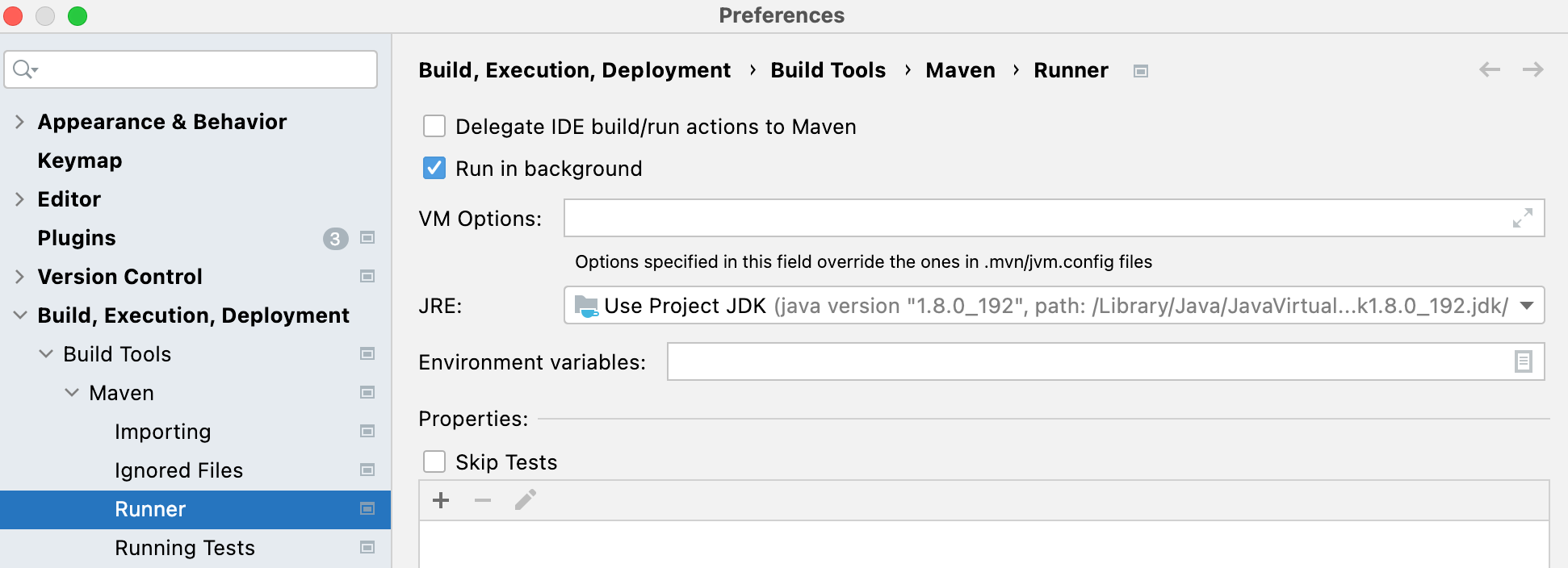
-
-
If you switch maven build profile, e.g., from Spark 3.2 to Spark 3.3, you need to first build Hudi in the command line first and
Reload All Maven Projectsin IntelliJ like below, so that IntelliJ re-indexes the code.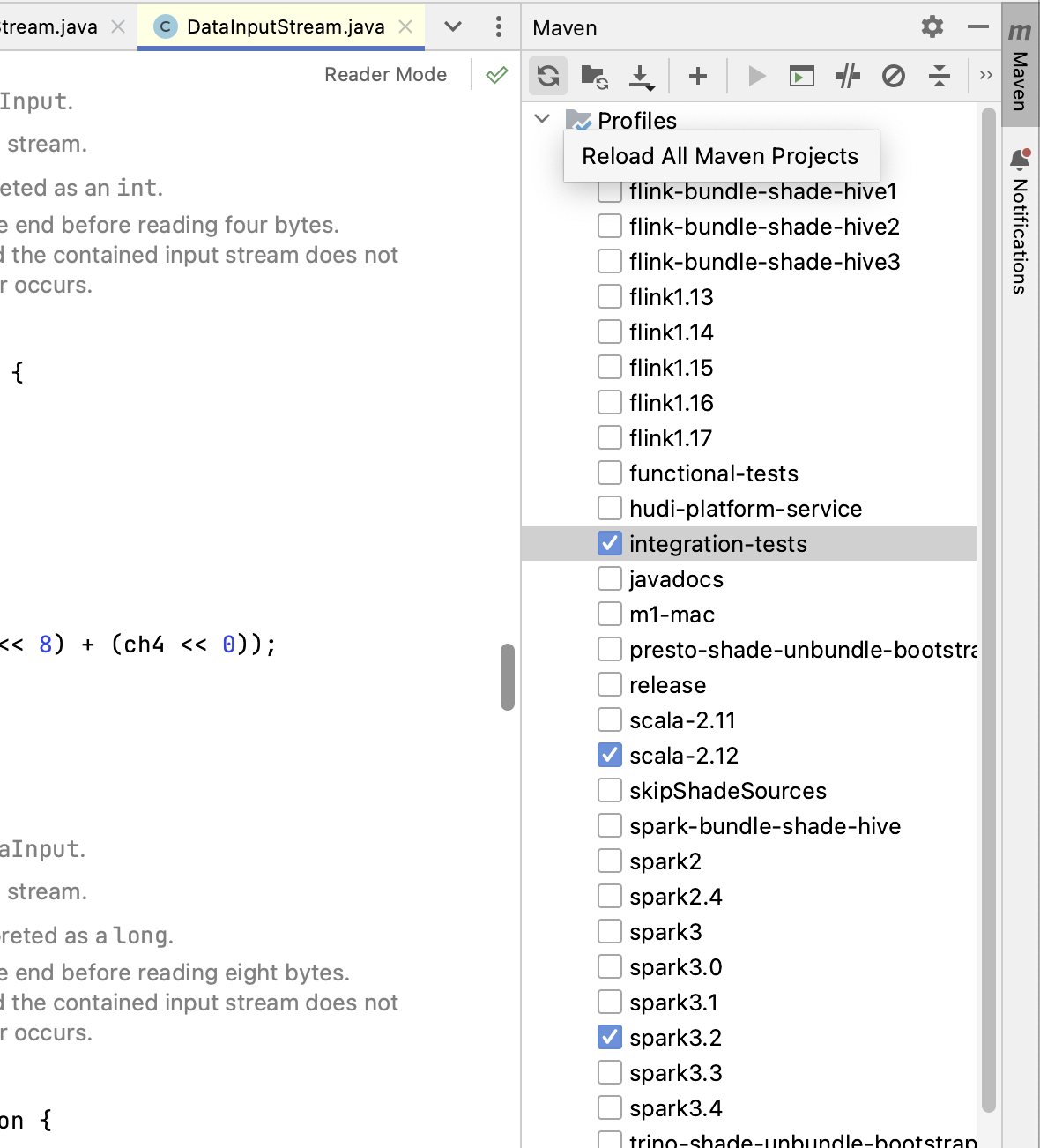
-
[Recommended] We have embraced the code style largely based on google format. Please set up your IDE with style files from <project root>/style/. These instructions have been tested on IntelliJ.
-
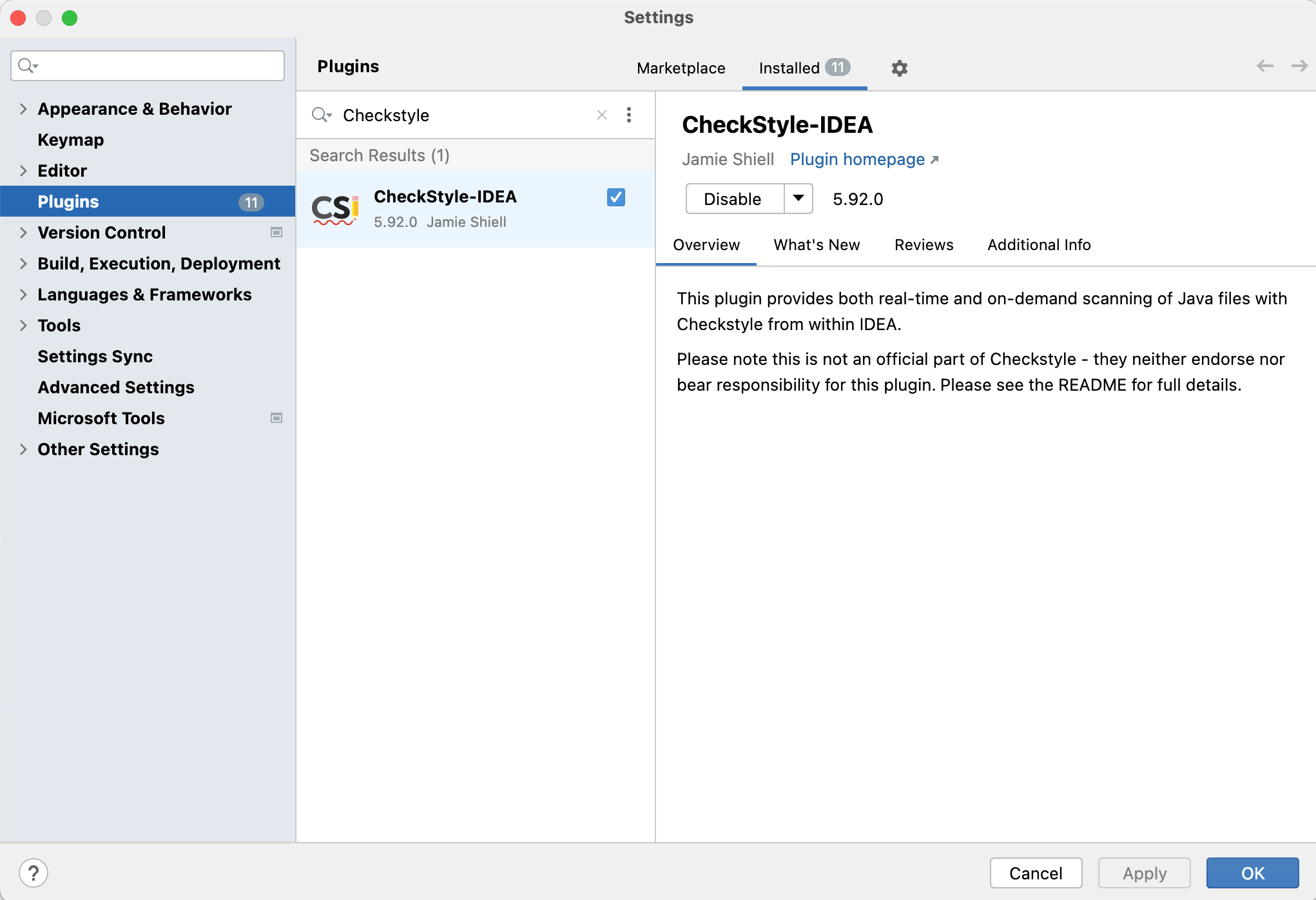
Open
Settingsin IntelliJ -
Install and activate CheckStyle plugin
-
In
Settings>Tools>Checkstyle, use a recent version, e.g., 10.17.0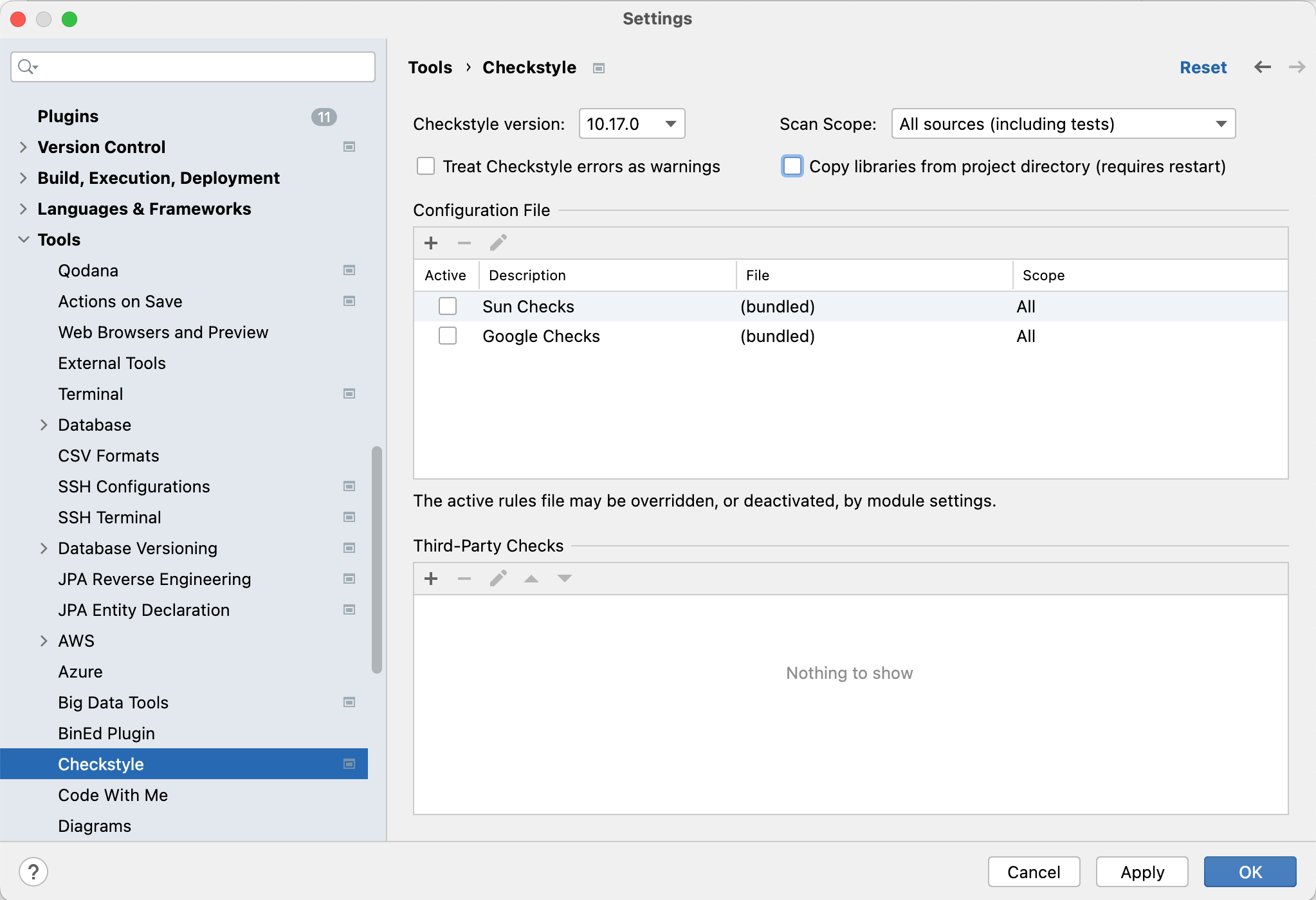
-
Click on
+, add the style/checkstyle.xml file, and name the configuration as "Hudi Checks"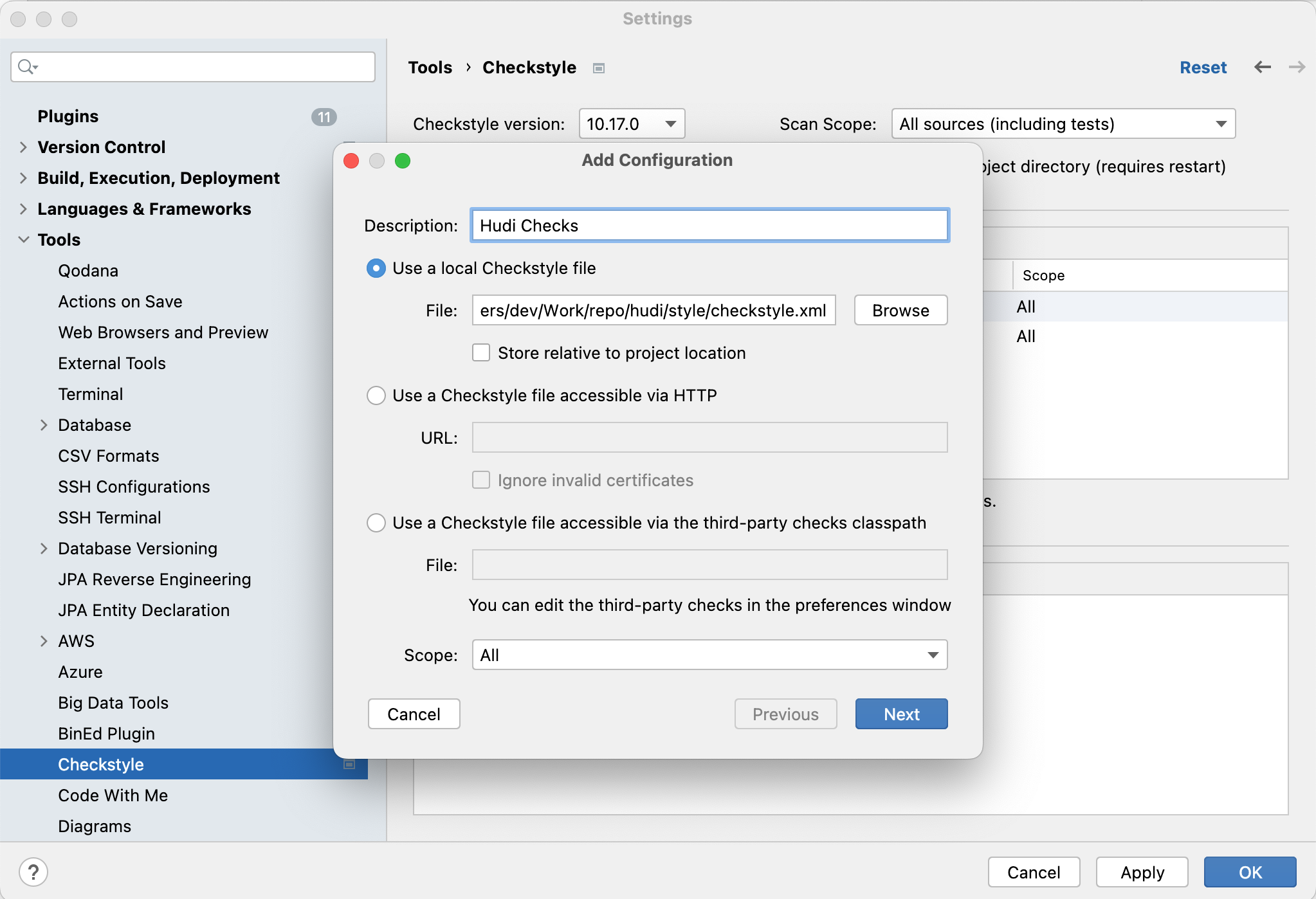
-
Activate the checkstyle configuration by checking
Active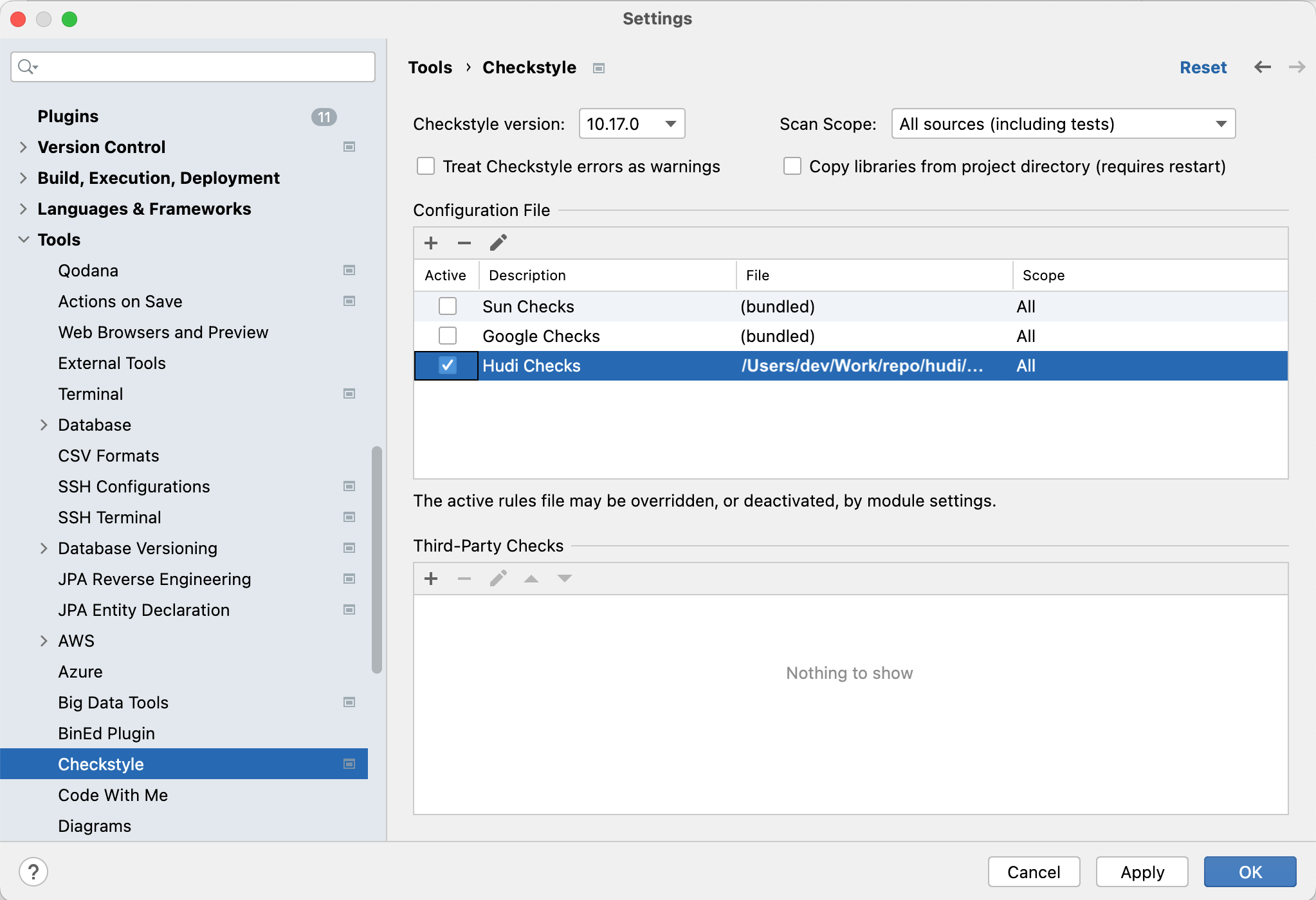
-
Open
Settings>Editor>Code Style>Java -
Select "Project" as the "Scheme". Then, go to the settings, open
Import Scheme>CheckStyle Configuration, selectstyle/checkstyle.xmlto load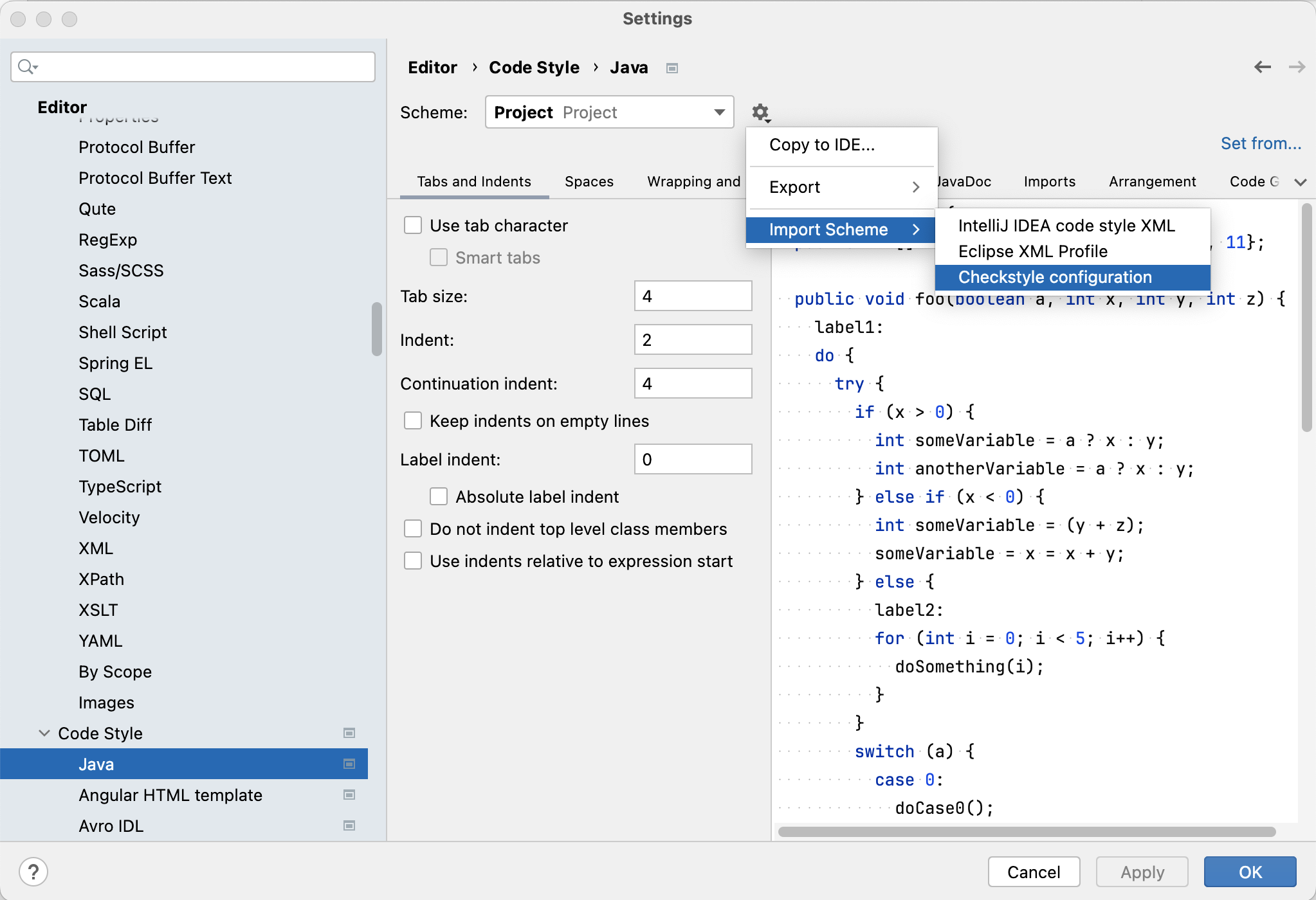
-
After loading the configuration, you should see that the
IndentandContinuation indentbecome 2 and 4, from 4 and 8, respectively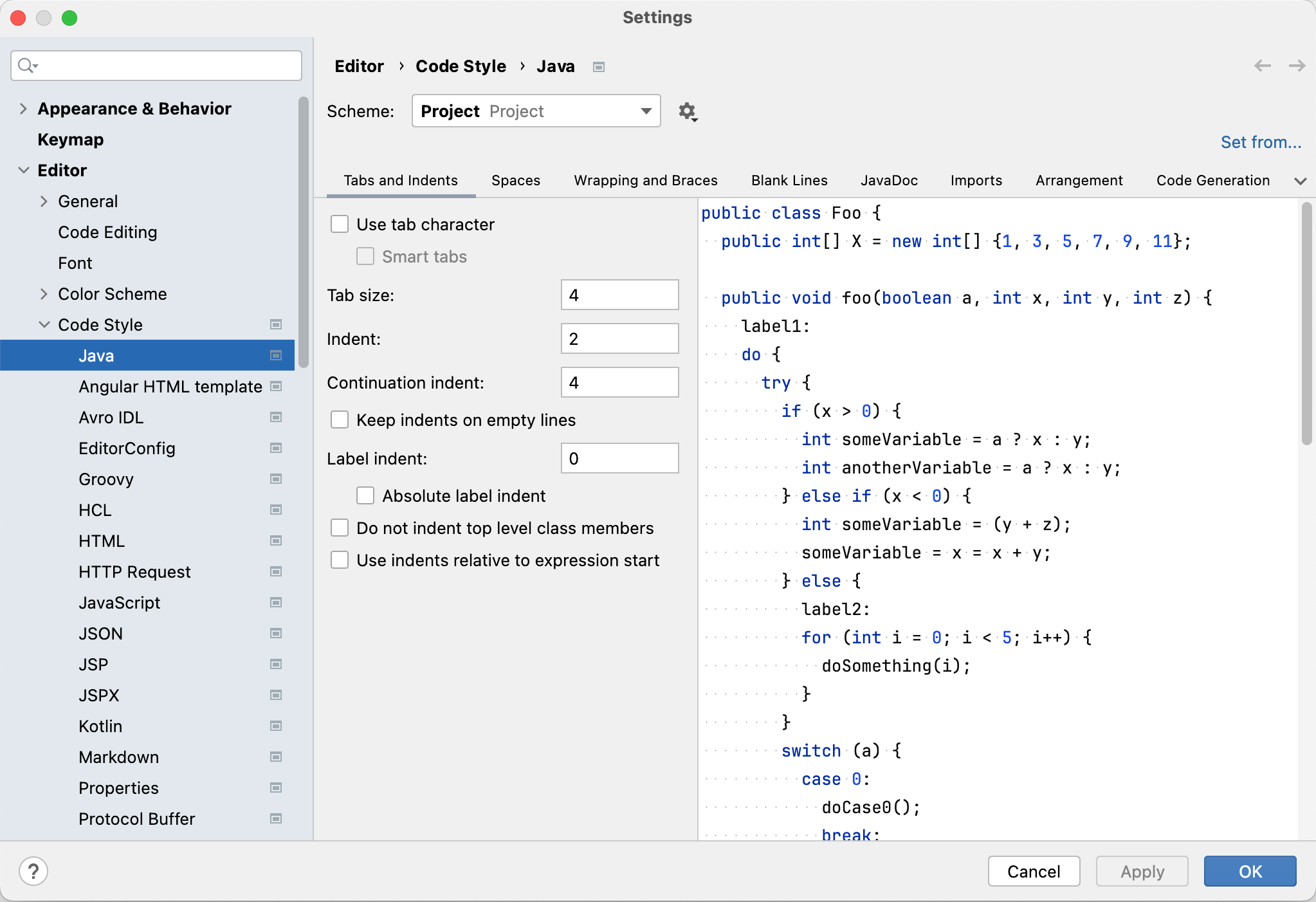
-
Apply/Save the changes
-
-
[Recommended] Set up the Save Action Plugin to auto format & organize imports on save. The Maven Compilation life-cycle will fail if there are checkstyle violations.
-
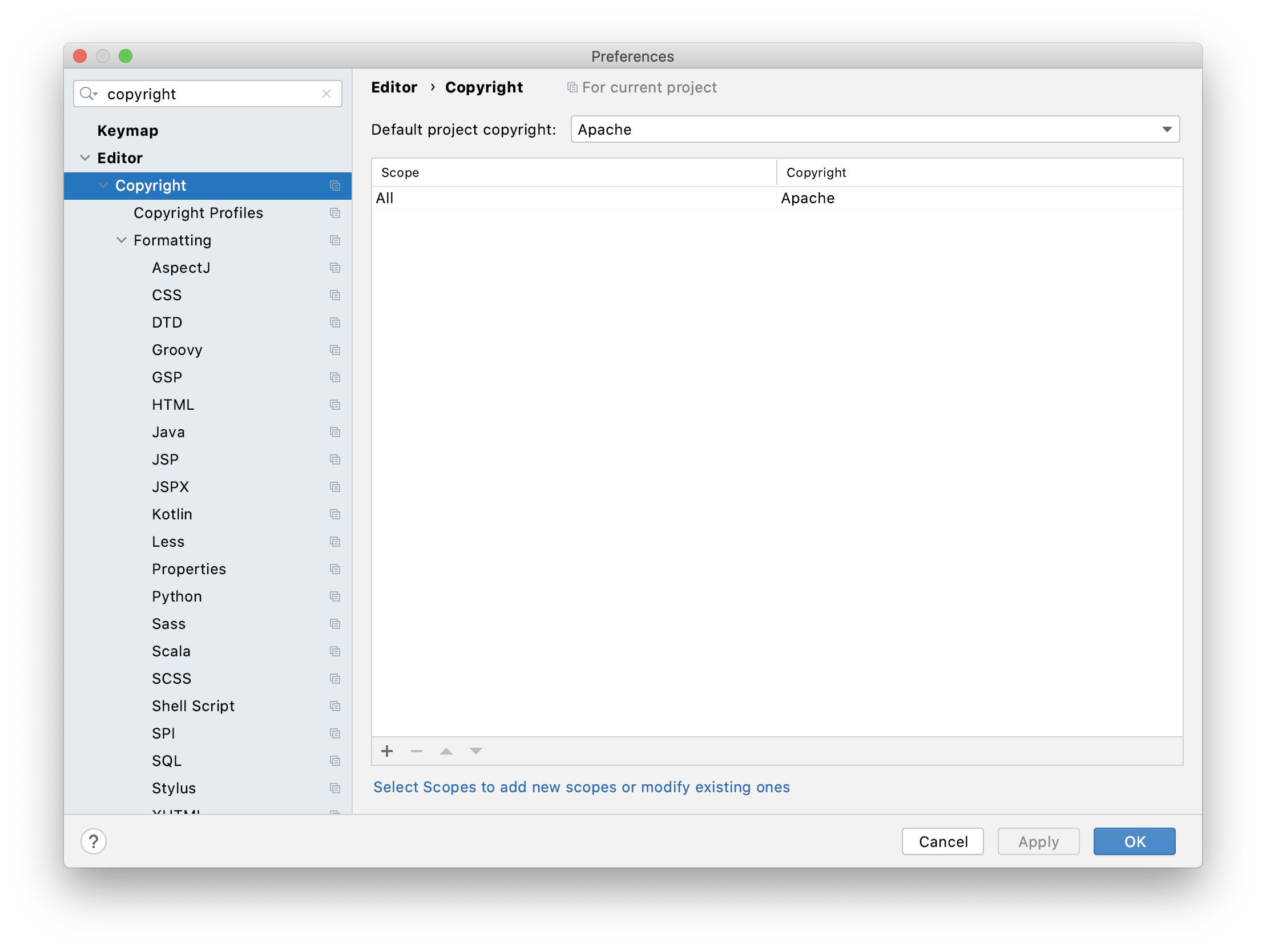
[Recommended] As it is required to add Apache License header to all source files, configuring "Copyright" settings as shown below will come in handy.
Accounts and Permissions
-
Hudi issue tracker (JIRA): Anyone can access it and browse issues. Anyone can register an account and login to create issues or add comments. Only contributors can be assigned issues. If you want to be assigned issues, a PMC member can add you to the project contributor group. Email the dev mailing list to ask to be added as a contributor, and include your ASF Jira username.
-
Hudi Wiki Space: Anyone has read access. If you wish to contribute changes, please create an account and request edit access on the dev@ mailing list (include your Wiki account user ID).
-
Pull requests can only be merged by a HUDI committer, listed here
-
Voting on a release: Everyone can vote. Only Hudi PMC members should mark their votes as binding.
Life of a Contributor
This document details processes and procedures we follow to make contributions to the project and take it forward. If you are looking to ramp up into the project as a contributor, we highly encourage you to read this guide in full, familiarize yourself with the workflow and more importantly also try to improve the process along the way as well.
Filing JIRAs
- Hudi uses JIRA to manage issues. First, familiarize yourself with the various components against which issues are filed in Hudi.
- Make an attempt to find an existing JIRA, that may solve the same issue you are reporting. When in doubt, you can always email the mailing list so that the community can provide early feedback, point out any similar JIRAs or RFCs.
- Try to gauge whether this JIRA needs an RFC. As always, email the mailing list if unsure. If you need an RFC since the change is large in scope, then please follow the wiki instructions to get the process rolling along.
- While raising a new JIRA or updating an existing one, please make sure to do the following
- The issue
typeandcomponents(when resolving the ticket) are set correctly - If you intend to target the JIRA for a specific release, please fill in the
fix version(s)field, with the release number. - Summary should be descriptive enough to catch the essence of the problem/ feature
- Where necessary, capture the version of Hudi/Spark/Hive/Hadoop/Cloud environments in the ticket
- Whenever possible, provide steps to reproduce via sample code or on the docker setup
- The issue
- All newly filed JIRAs are placed in the
NEWstate. If you are sure about this JIRA representing valid, scoped piece of work, please clickAccept Issueto move itOPENstate - If you are not sure, please wait for a PMC/Committer to confirm/triage the issue and accept it. This process avoids contributors spending time on JIRAs with unclear scope.
- Whenever possible, break down large JIRAs (e.g JIRAs resulting from an RFC) into
sub tasksby clickingMore > create sub-taskfrom the parent JIRA , so that the community can contribute at large and help implement it much quickly. We recommend prefixing such JIRA titles with[UMBRELLA]
Claiming JIRAs
- Finding a JIRA to work on
- If you are new to the project, you can ramp up by picking up any issues tagged with the newbie component.
- If you want to work on some higher priority issue, then scout for Open issues against the next release on the JIRA, engage on unassigned/inactive JIRAs and offer help.
- Issues tagged with
Usability,Code Cleanup,Testingcomponents often present excellent opportunities to make a great impact.
- If you don't have perms to self-assign JIRAs, please email the dev mailing list with your JIRA id and a small intro for yourself. We'd be happy to add you as a contributor.
- As courtesy, if you are unable to continue working on a JIRA, please move it back to "OPEN" state and un-assign yourself.
- If a JIRA or its corresponding pull request has been inactive for a week, awaiting feedback from you, PMC/Committers could choose to re-assign them to another contributor.
- Such re-assignment process would be communicated over JIRA/GitHub comments, checking with the original contributor on his/her intent to continue working on the issue.
- You can also contribute by helping others contribute. So, if you don't have cycles to work on a JIRA and another contributor offers help, take it!
Contributing Code
- Once you finalize on a project/task, please open a new JIRA or assign an existing one to yourself.
- Almost all PRs should be linked to a JIRA. It's always good to have a JIRA upfront to avoid duplicating efforts.
- If the changes are minor, then
[MINOR]prefix can be added to Pull Request title without a JIRA. Below are some tips to judge MINOR Pull Request :- trivial fixes (for example, a typo, a broken link, intellisense or an obvious error)
- the change does not alter functionality or performance in any way
- changed lines less than 100
- obviously judge that the PR would pass without waiting for CI / CD verification
- But, you may be asked to file a JIRA, if reviewer deems it necessary
- Before you begin work,
- Claim the JIRA using the process above and assign the JIRA to yourself.
- Click "Start Progress" on the JIRA, which tells everyone that you are working on the issue actively.
- [Optional] Familiarize yourself with internals of Hudi using content on this page, as well as wiki
- Make your code change
- Get existing tests to pass using
mvn clean install -DskipITs - Add adequate tests for your new functionality
- For involved changes, it's best to test the changes in real production environments and report the results in the PR.
- For website changes, please build the site locally & test navigation, formatting & links thoroughly
- If your code change changes some aspect of documentation (e.g new config, default value change), please ensure there is another PR to update the docs as well.
- Get existing tests to pass using
- Sending a Pull Request
- Format commit and the pull request title like
[HUDI-XXX] Fixes bug in Spark Datasource, where you replaceHUDI-XXXwith the appropriate JIRA issue. - Pull request titles must have either
[HUDI-XXX]or[MINOR]in their title. Note the brackets and capitalization. - Please ensure your commit message body is descriptive of the change. Bulleted summary would be appreciated.
- You must follow the instructions in the template and fill out all fields to pass our compliance checks.
- Do not remove or modify any headings in the template.
- Push your commit to your own fork/branch & create a pull request (PR) against the Hudi repo.
- If you don't hear back within 3 days on the PR, please send an email to the dev @ mailing list.
- Address code review comments & keep pushing changes to your fork/branch, which automatically updates the PR
- Before your change can be merged, it should be squashed into a single commit for cleaner commit history.
- Format commit and the pull request title like
- Finally, once your pull request is merged, make sure to
Closethe JIRA.
Coding guidelines
Our code can benefit from contributors speaking the same "language" when authoring code. After all, it gets read a lot more than it gets written. So optimizing for "reads" is a good goal. The list below is a set of guidelines, that contributors strive to upkeep and reflective of how we want to evolve our code in the future.
Style
- Formatting We should rely on checkstyle and spotless to auto fix formatting; automate this completely. Where we cannot, we will err on the side of not taxing contributors with manual effort.
- Refactoring
- Refactor with purpose; any refactor suggested should be attributable to functionality that now becomes easy to implement.
- A class is asking to be refactored, when it has several overloaded responsibilities/have sets of fields/methods which are used more cohesively than others.
- Try to name tests using the given-when-then model, that cleans separates preconditions (given), an action (when), and assertions (then).
- Naming things
- Let's name uniformly; using the same word to denote the same concept. e.g: bootstrap vs external vs source, when referring to bootstrapped tables. Maybe they all mean the same, but having one word makes the code lot more easily readable.
- Let's name consistently with Hudi terminology. e.g dataset vs table, base file vs data file.
- Class names preferably are nouns (e.g Runner) which reflect their responsibility and methods are verbs (e.g run()).
- Avoid filler words, that don't add value e.g xxxInfo, xxxData, etc.
- We name classes in code starting with
Hoodieand notHudiand we want to keep it that way for consistency/historical reasons.
- Methods
- Individual methods should short (~20-30 lines) and have a single purpose; If you feel like it has a secondary purpose, then maybe it needs to be broken down more.
- Lesser the number of arguments, the better;
- Place caller methods on top of callee methods, whenever possible.
- Avoid "output" arguments e.g passing in a list and filling its values within the method.
- Try to limit individual if/else blocks to few lines to aid readability.
- Separate logical blocks of code with a newline in between e.g read a file into memory, loop over the lines.
- Classes
- Like method, each Class should have a single purpose/responsibility.
- Try to keep class files to about 200 lines of length, nothing beyond 500.
- Avoid stating the obvious in comments; e.g each line does not deserve a comment; Document corner-cases/special perf considerations etc clearly.
- Try creating factory methods/builders and interfaces wherever you feel a specific implementation may be changed down the line.
Substance
- Try to avoid large PRs; if unavoidable (many times they are) please separate refactoring with the actual implementation of functionality. e.g renaming/breaking up a file and then changing code changes, makes the diff very hard to review.
- Licensing
- Every source file needs to include the Apache license header. Every new dependency needs to have an open source license compatible with Apache.
- If you are re-using code from another apache/open-source project, licensing needs to be compatible and attribution added to
LICENSEfile - Please DO NOT copy paste any code from StackOverflow or other online sources, since their license attribution would be unclear. Author them yourself!
- Code Organization
- Anything in
hudi-commoncannot depend on a specific engine runtime like Spark. - Any changes to bundles under
packaging, will be reviewed with additional scrutiny to avoid breakages across versions.
- Anything in
- Code reuse
- Whenever you can, please use/enhance use existing utils classes in code (
CollectionUtils,ParquetUtils,HoodieAvroUtils). Search for classes ending inUtils. - As a complex project, that must integrate with multiple systems, we tend to avoid dependencies like
guava,apache commonsfor the sake of easy integration. Please start a discussion on the mailing list, before attempting to reintroduce them - As a data system, that takes performance seriously, we also write pieces of infrastructure (e.g
ExternalSpillableMap) natively, that are optimized specifically for our scenarios. Please start with them first, when solving problems.
- Whenever you can, please use/enhance use existing utils classes in code (
- Breaking changes
- Any version changes for dependencies, needs to be ideally vetted across different user environments in the community, to get enough confidence before merging.
- Any changes to methods annotated with
PublicAPIMethodor classes annotated withPublicAPIClassrequire upfront discussion and potentially an RFC. - Any non-backwards compatible changes similarly need upfront discussion and the functionality needs to implement an upgrade-downgrade path.
Tests
- Categories
- unit - testing basic functionality at the class level, potentially using mocks. Expected to finish quicker
- functional - brings up the services needed and runs test without mocking
- integration - runs subset of functional tests, on a full fledged enviroment with dockerized services
- Prepare Test Data
- Many unit and functional test cases require a Hudi dataset to be prepared beforehand.
HoodieTestTableandHoodieWriteableTestTableare dedicated test utility classes for this purpose. Use them whenever appropriate, and add new APIs to them when needed. - When add new APIs in the test utility classes, overload APIs with variety of arguments to do more heavy-liftings for callers.
- In most scenarios, you won't need to use
FileCreateUtilsdirectly. - If test cases require interaction with actual
HoodieRecords, useHoodieWriteableTestTable(andHoodieTestDataGeneratorprobably). Otherwise,HoodieTestTablethat manipulates empty files shall serve the purpose.
- Many unit and functional test cases require a Hudi dataset to be prepared beforehand.
- Strive for Readability
- Avoid writing flow controls for different assertion cases. Split to a new test case when appropriate.
- Use plain for-loop to avoid try-catch in lambda block. Declare exceptions is okay.
- Use static import for constants and static helper methods to avoid lengthy code.
- Avoid reusing local variable names. Create new variables generously.
- Keep helper methods local to the test class until it becomes obviously generic and re-useable. When that happens, move the helper method to the right utility class. For example,
Assertionscontains common assert helpers, andSchemaTestUtilis for schema related helpers. - Avoid putting new helpers in
HoodieTestUtilsandHoodieClientTestUtils, which are named too generic. Eventually, all test helpers shall be categorized properly.
Reviewing Code/RFCs
- All pull requests would be subject to code reviews, from one or more of the PMC/Committers.
- Typically, each PR will get an "Assignee" based on their area of expertise, who will work with you to land the PR.
- Code reviews are vital, but also often time-consuming for everyone involved. Below are some principles which could help align us better.
- Reviewers need to provide actionable, concrete feedback that states what needs to be done to get the PR closer to landing.
- Reviewers need to make it explicit, which of the requested changes would block the PR vs good-to-dos.
- Both contributors/reviewers need to keep an open mind and ground themselves to making the most technically sound argument.
- If progress is hard, please involve another PMC member/Committer to share another perspective.
- Staying humble and eager to learn, goes a long way in ensuring these reviews are smooth.
- Reviewers are expected to uphold the code quality, standards outlined above.
- When merging PRs, always make sure you are squashing the commits using the "Squash and Merge" feature in Github
- When necessary/appropriate, reviewers could make changes themselves to PR branches, with the intent to get the PR landed sooner. (see how-to) Reviewers should seek explicit approval from author, before making large changes to the original PR.
Suggest Changes
We welcome new ideas and suggestions to improve the project, along any dimensions - management, processes, technical vision/direction. To kick start a discussion on the mailing thread
to effect change and source feedback, start a new email thread with the [DISCUSS] prefix and share your thoughts. If your proposal leads to a larger change, then it may be followed up
by a vote by a PMC member or others (depending on the specific scenario).
For technical suggestions, you can also leverage our RFC Process to outline your ideas in greater detail.
Useful Maven commands for developers.
Listing out some of the maven commands that could be useful for developers.
- Compile/build entire project
mvn clean package -DskipTests
Default profile is spark2 and scala2.11
- For continuous development, you may want to build only the modules of interest. for eg, if you have been working with deltastreamer, you can build using this command instead of entire project. Majority of time goes into building all different bundles we have like flink bundle, presto bundle, trino bundle etc. But if you are developing something confined to hudi-utilties, you can achieve faster build times.
mvn package -DskipTests -pl packaging/hudi-utilities-bundle/ -am
To enable multi-threaded building, you can add -T.
mvn -T 2C package -DskipTests -pl packaging/hudi-utilities-bundle/ -am
This command will use 2 parallel threads to build.
You can also confine the build to just one module if need be.
mvn -T 2C package -DskipTests -pl hudi-spark-datasource/hudi-spark -am
Note: "-am" will build all dependent modules as well. In local laptop, entire project build can take somewhere close to 7 to 10 mins. While buildig just hudi-spark-datasource/hudi-spark with multi-threaded, could get your compilation in 1.5 to 2 mins.
If you wish to run any single test class in java.
mvn test -Punit-tests -pl hudi-spark-datasource/hudi-spark/ -am -B -DfailIfNoTests=false -Dtest=TestCleaner
If you wish to run a single test method in java.
mvn test -Punit-tests -pl hudi-spark-datasource/hudi-spark/ -am -B -DfailIfNoTests=false -Dtest=TestCleaner#testKeepLatestCommitsMOR
To filter particular scala test:
mvn -Dsuites="org.apache.spark.sql.hudi.TestSpark3DDL @Test Chinese table " -Dtest=abc -DfailIfNoTests=false test -pl packaging/hudi-spark-bundle -am
-Dtest=abc will assist in skipping all java tests. -Dsuites="org.apache.spark.sql.hudi.TestSpark3DDL @Test Chinese table " filters for a single scala test.
- Run an Integration Test
mvn -T 2C -Pintegration-tests -DfailIfNoTests=false -Dit.test=ITTestHoodieSanity#testRunHoodieJavaAppOnMultiPartitionKeysMORTable verify
verify phase runs the integration test and cleans up the docker cluster after execution. To retain the docker cluster use
integration-test phase instead.
Note: If you encounter unknown shorthand flag: 'H' in -H, this error occurs when local environment has docker-compose version >= 2.0.
The latest docker-compose is accessible using docker-compose whereas v1 version is accessible using docker-compose-v1 locally.
You can use alt def command to define different docker-compose versions. Refer https://github.com/dotboris/alt.
Use alt use to use v1 version of docker-compose while running integration test locally.
Releases
- Apache Hudi community plans to do minor version releases every 6 weeks or so.
- If your contribution merged onto the
masterbranch after the last release, it will become part of the next release. - Website changes are regenerated on-demand basis (until automation in place to reflect immediately)
Communication
All communication is expected to align with the Code of Conduct. Discussion about contributing code to Hudi happens on the dev@ mailing list. Introduce yourself!
Code & Project Structure
docker: Docker containers used by demo and integration tests. Brings up a mini data ecosystem locallyhudi-cli: CLI to inspect, manage and administer datasetshudi-client: Spark client library to take a bunch of inserts + updates and apply them to a Hoodie tablehudi-common: Common classes used across moduleshudi-hadoop-mr: InputFormat implementations for ReadOptimized, Incremental, Realtime viewshudi-hive: Manage hive tables off Hudi datasets and houses the HiveSyncToolhudi-integ-test: Longer running integration test processeshudi-spark: Spark datasource for writing and reading Hudi datasets. Streaming sink.hudi-utilities: Houses tools like DeltaStreamer, SnapshotCopierpackaging: Poms for building out bundles for easier drop in to Spark, Hive, Presto, Utilitiesstyle: Code formatting, checkstyle files
Code WalkThrough
This Quick Video will give a code walkthrough to start with watch.
Running unit tests and local debugger via Intellij IDE
IMPORTANT REMINDER FOR BELOW STEPS: When submitting a PR please make sure to NOT commit the changes mentioned in these steps, instead once testing is done make sure to revert the changes and then submit a pr.
- Build the project with the intended profiles via the
mvncli, for example for spark 3.2 usemvn clean package -Dspark3.2 -Dscala-2.12 -DskipTests. - Install the "Maven Helper" plugin from the Intellij IDE.
- Make sure IDEA uses Maven to build/run tests:
- You need to select the intended Maven profiles (using Maven tool pane in IDEA): select profiles you are targeting for example
spark2.4andscala-2.11orspark3.2,scala-2.12etc. - Add
.mvn/maven.configfile at the root of the repo w/ the the profiles you selected in the pane:-Dspark3.2-Dscala-2.12 - Add
.mvn/to the.gitignorefile located in the root of the project.
- You need to select the intended Maven profiles (using Maven tool pane in IDEA): select profiles you are targeting for example
- Make sure you change (temporarily) the
scala.binary.versionin the rootpom.xmlto the intended scala profile version. For example if running with spark3scala.binary.versionshould be2.12 - Finally right click on the unit test's method signature you are trying to run, there should be an option with a mvn symbol that allows you to
run <test-name>, as well as an option todebug <test-name>.- For debugging make sure to first set breakpoints in the src code see (https://www.jetbrains.com/help/idea/debugging-code.html)
Docker Setup
We encourage you to test your code on docker cluster please follow this for docker setup.
Remote Debugging
if your code fails on docker cluster you can remotely debug your code please follow the below steps.
Step 1 :- Run your Delta Streamer Job with --conf as defined this will ensure to wait till you attach your intellij with Remote Debugging on port 4044
spark-submit \
--conf spark.driver.extraJavaOptions="-Dconfig.resource=myapp.conf -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=4044" \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer $HUDI_UTILITIES_BUNDLE \
--table-type COPY_ON_WRITE \
--source-class org.apache.hudi.utilities.sources.JsonKafkaSource \
--source-ordering-field ts \
--base-file-format parquet \
--target-base-path /user/hive/warehouse/stock_ticks_cow \
--target-table stock_ticks_cow --props /var/demo/config/kafka-source.properties \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider
Step 2 :- Attaching Intellij (tested on Intellij Version > 2019. this steps may change acc. to intellij version)
- Come to Intellij --> Edit Configurations -> Remote -> Add Remote - > Put Below Configs -> Apply & Save -> Put Debug Point -> Start.
- Name : Hudi Remote
- Port : 4044
- Command Line Args for Remote JVM : -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=4044
- Use Module ClassPath : select hudi
Website
Apache Hudi site is hosted on a special asf-site branch. Please follow the README file under docs on that branch for
instructions on making changes to the website.