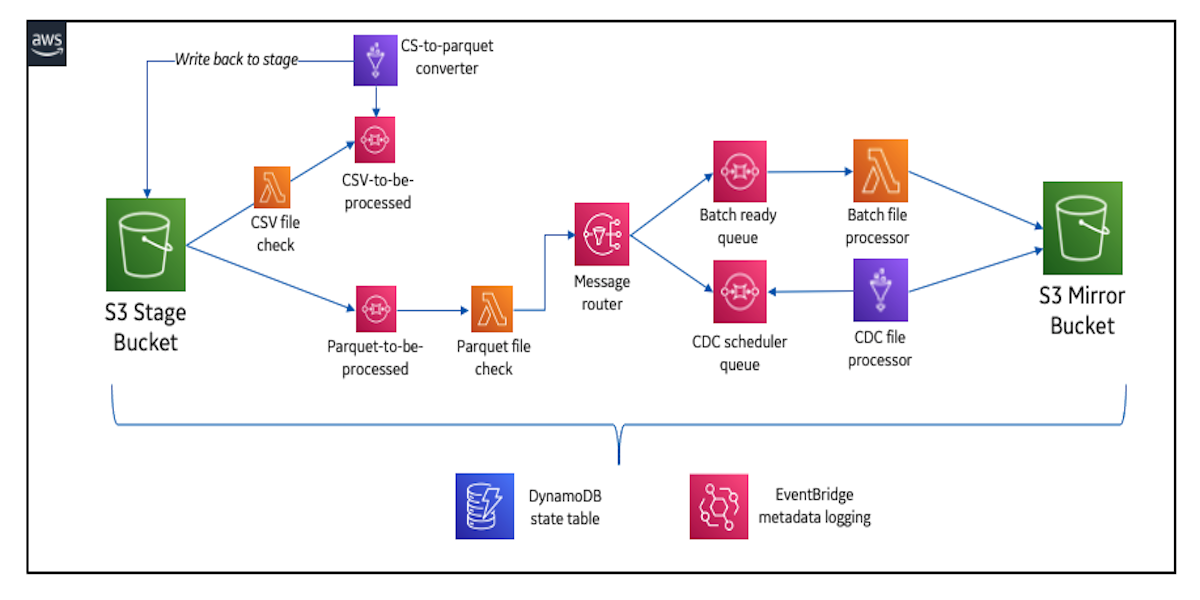
How GE Aviation built cloud-native data pipelines at enterprise scale using the AWS platformNovember 16, 2021 by Alcuin Weidus and Suresh Patnamuse-caseanalytics at scaleamazon
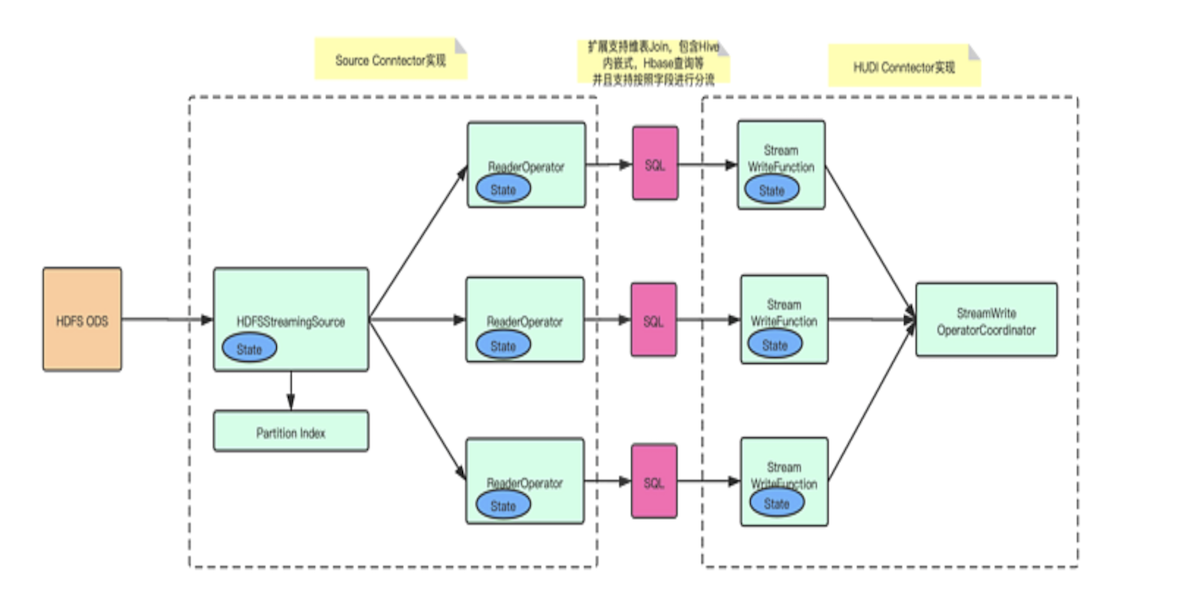
Practice of Apache Hudi in building real-time data lake at station BOctober 21, 2021 by Yu Zhaojinguse-casereal-time datalakedeveloppaper
How Amazon Transportation Service enabled near-real-time event analytics at petabyte scale using AWS Glue with Apache HudiOctober 14, 2021 by Madhavan Sriram, Diego Menin, Gabriele Cacciola and Kunal Gautamuse-casenear real-time analyticsanalytics at scaleamazon
Building an ExaByte-level Data Lake Using Apache Hudi at ByteDanceSeptember 1, 2021 by Ziyue Guan, translated to English by yihuause-caseapache hudi
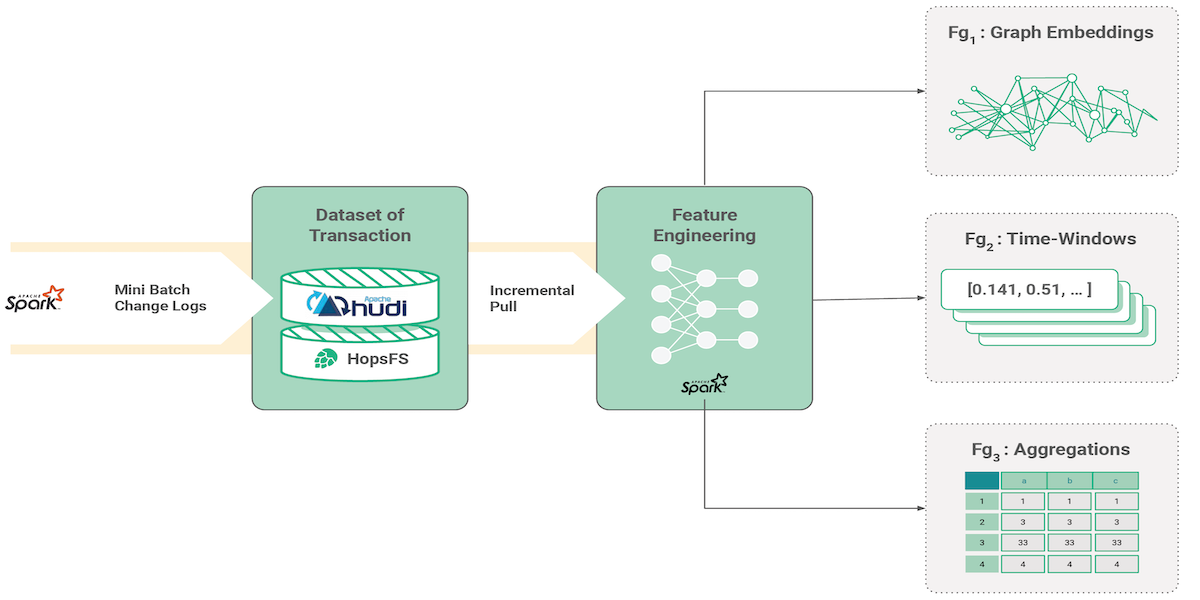
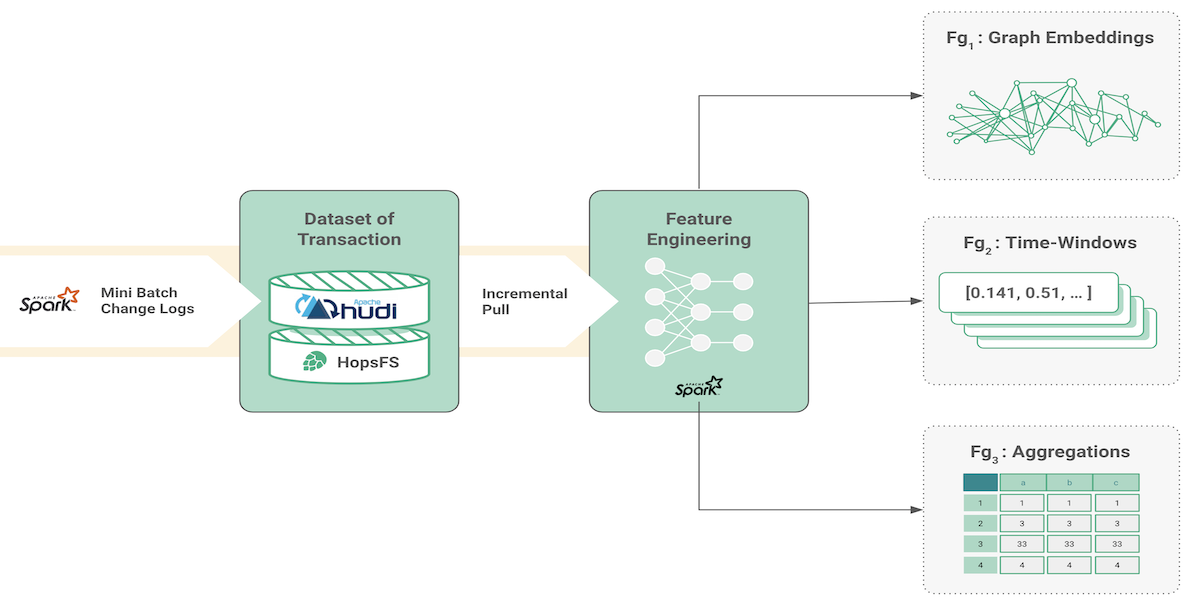
MLOps Wars: Versioned Feature Data with a LakehouseAugust 3, 2021 by David Bzhalava and Jim Dowlinguse-casemlopsfeature storeincremental processingtime travel querylogicalclocks
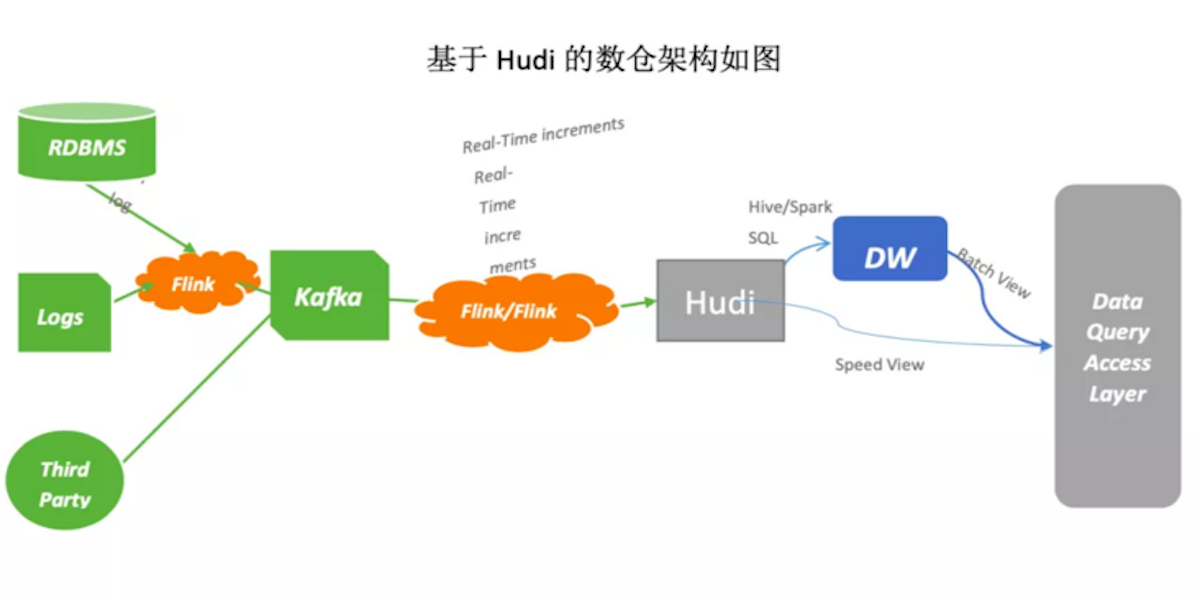
Baixin bank’s real-time data lake evolution scheme based on Apache HudiJuly 26, 2021use-casereal-time datalakeincremental processingdeveloppaper
Time travel operations in Hopsworks Feature StoreFebruary 24, 2021use-caseincremental processingfeature storetime travel queryhopsworks
Building High-Performance Data Lake Using Apache Hudi and Alluxio at T3GoDecember 1, 2020 by t3gouse-casenear real-time analyticsincremental processingcachingapache hudi
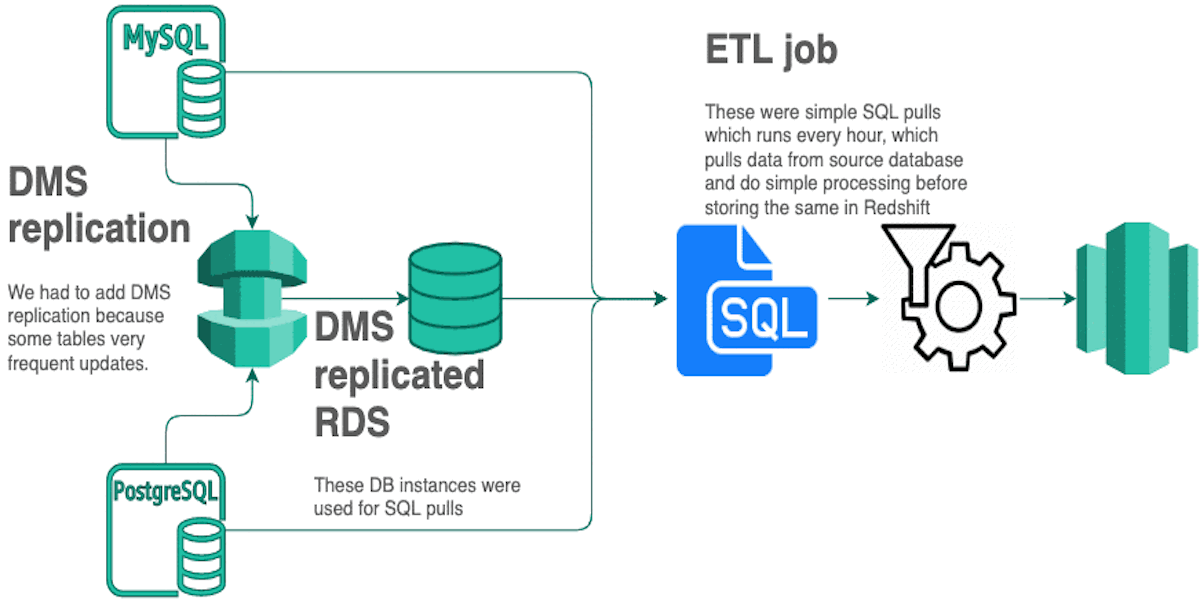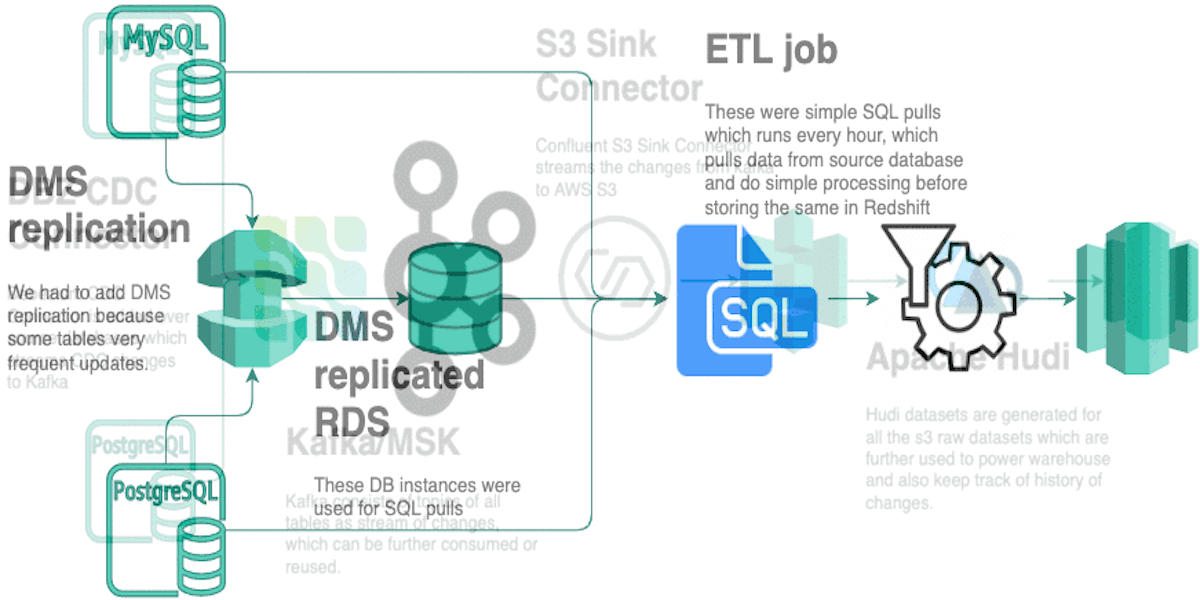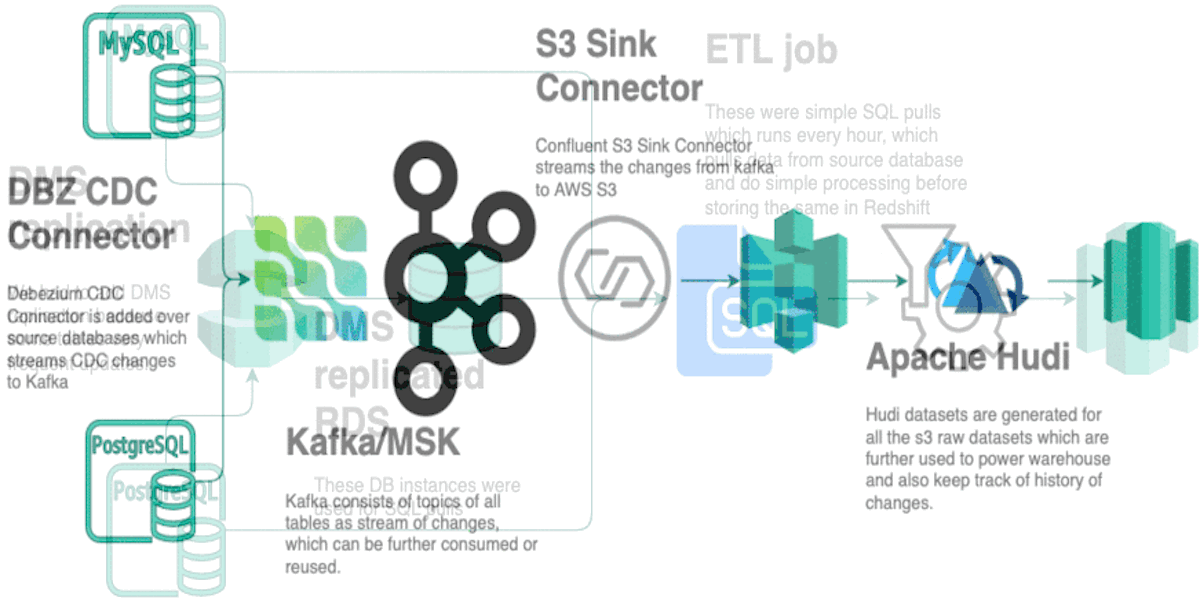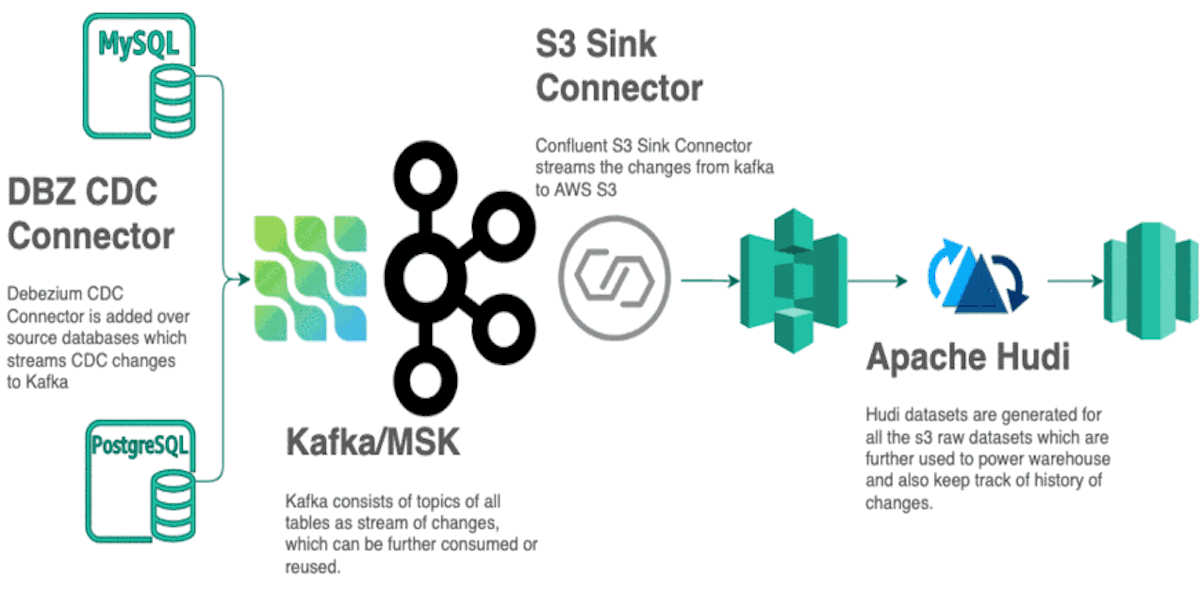
Origins of Data Lake at GrofersOctober 19, 2020 by Akshay Agarwaluse-casedatalakechange data capturecdcgrofers
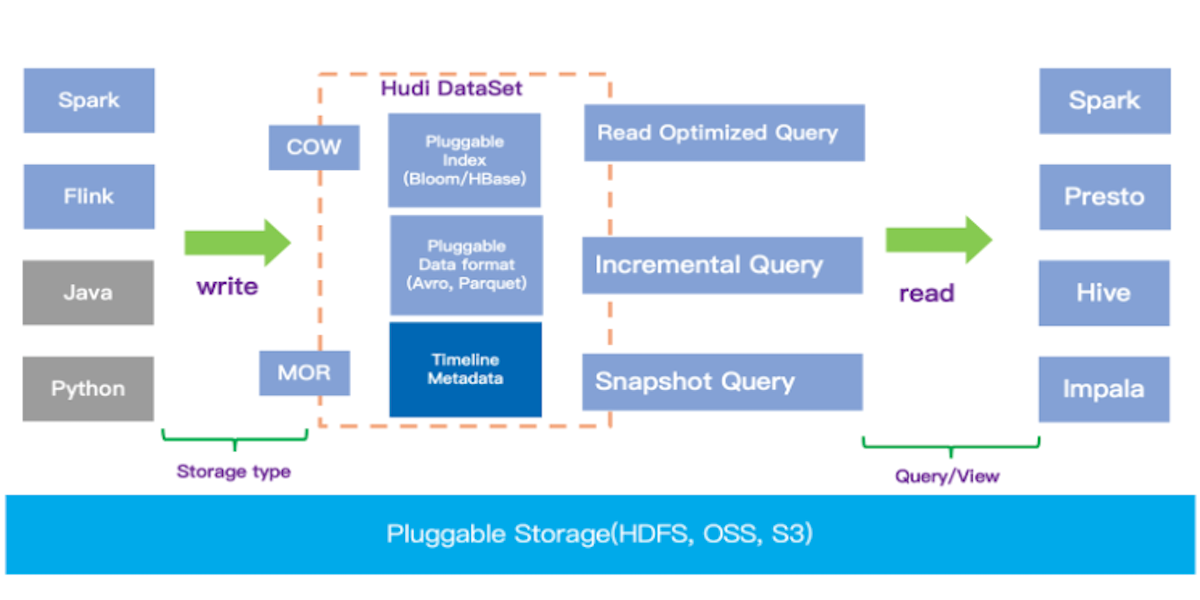
Building a Large-scale Transactional Data Lake at Uber Using Apache HudiJune 9, 2020 by Nishith Agarwaluse-casedatalakeanalytics at scaleuber
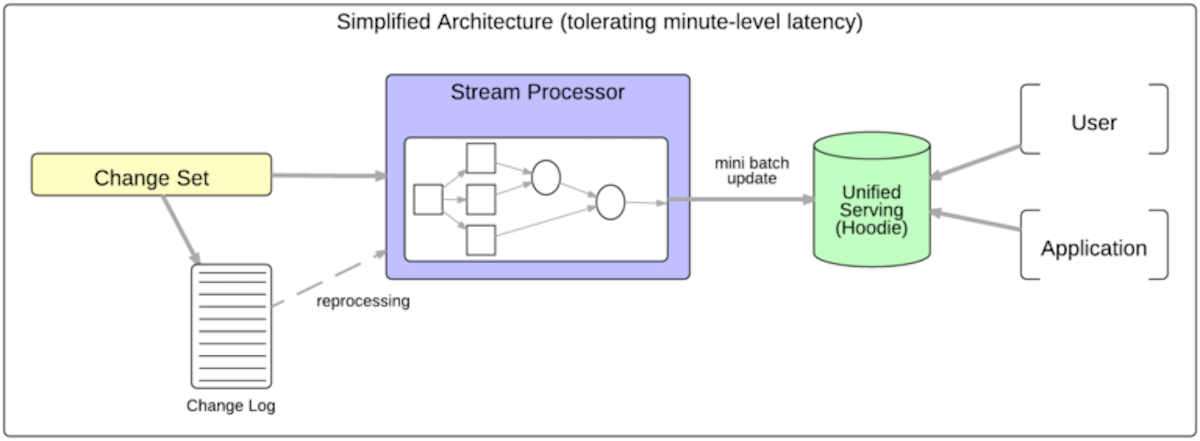
Hoodie: Uber Engineering's Incremental Processing Framework on HadoopMarch 12, 2017 by Prasanna Rajaperumal and Vinoth Chandaruse-caseincremental processinguber