Concurrency Control in Open Data Lakehouse

Concurrency control in an open data lakehouse determines how multiple writers, table services, and readers can safely operate on the same table at once, and open table formats implement it using methods adapted from database systems: optimistic concurrency control (OCC), multi-version concurrency control (MVCC), and - in Apache Hudi - non-blocking concurrency control (NBCC). This post covers the database foundations of these methods, then examines how Apache Hudi, Apache Iceberg, and Delta Lake apply them.
See the Hudi concurrency control docs for configuration reference, Lakehouse Concurrency Control: Are we too optimistic? for a critique of OCC under contention, and the NBCC deep dive for how non-blocking multi-writer support works.
Introduction
Concurrency control is critical in database management systems to ensure consistent and safe access to shared data by multiple users. Relational databases (RDBMS) such as MySQL (InnoDB) and analytical databases (such as data warehouses) have been offering robust concurrency control mechanisms to effectively deal with this. As data grows in scale and complexity, managing concurrent access becomes more challenging, especially in large distributed systems like Data Lakes or Lakehouses, which are expected to handle different types of workloads in the analytics realm. While data lakes have traditionally struggled with concurrent operations due to the lack of a storage engine and ACID guarantees, lakehouse architectures with open table formats like Apache Hudi, Apache Iceberg, and Delta Lake take inspiration from some of the widely used concurrency control methods to support high concurrent workloads.
This blog goes into the fundamentals of concurrency control, explores why it is essential for lakehouses, and examines how open table formats such as Apache Hudi enable strong concurrency control mechanisms to uphold the ACID properties and deal with varied workloads.
Concurrency Control Foundations
At the core of concurrency control are the concepts of Isolation and Serializability, which define the expected behavior for concurrent transactions and ensure the "I" in ACID properties. Let’s quickly go over these concepts from a general database system perspective.
Isolation and Serializability
In transactional systems, Isolation ensures that each transaction operates independently of others, as if it were executed in a single-user environment. This means a transaction should be "all by itself," free from interference by other concurrent operations, preventing concurrency anomalies like dirty reads or lost updates. This isolation allows end users (such as developers or analysts) to understand the impact of a transaction without worrying about conflicts from other simultaneous operations.
Serializability takes this idea further by defining the correct execution order for concurrent transactions. It guarantees that the outcome of executing transactions concurrently will be the same as if they had been executed serially, one after the other. In other words, even if transactions are interleaved, their combined effect should appear as though there were no parallel execution at all. Serializability is thus a rigorous correctness criterion that concurrency control models in databases strive to enforce, providing a predictable environment for transactional workloads.
For example, imagine an online concert ticketing system where multiple customers are attempting to purchase tickets for the same concert at the same time. Suppose there are only 5 tickets left, and two customers - Customer A and Customer B try to buy 3 tickets each simultaneously. Without proper concurrency control, these transactions might interfere with each other, leading to scenarios where more tickets are "sold" than available in inventory, resulting in inconsistencies. To maintain serializability, the system must ensure that the outcome of processing these transactions concurrently is the same as if they were processed one at a time (serially), i.e. no more than 5 tickets are sold, ensuring inventory consistency.
Concurrency control methods can be broadly classified into three approaches: Pessimistic Concurrency Control, Optimistic Concurrency Control, and Multi-Version Concurrency Control (MVCC).
Pessimistic Concurrency Control (2PL)
Pessimistic Concurrency Control assumes that conflicts between transactions can happen often and avoids having ‘problems’ in the first place. The most commonly used method, Strict Two-Phase Locking (2PL), works in this way:
- Transactions acquire a shared lock before reading data and an exclusive lock before writing.
- Locks are held until the transaction commits or aborts but releases immediately after the commit command executes, ensuring serializability.
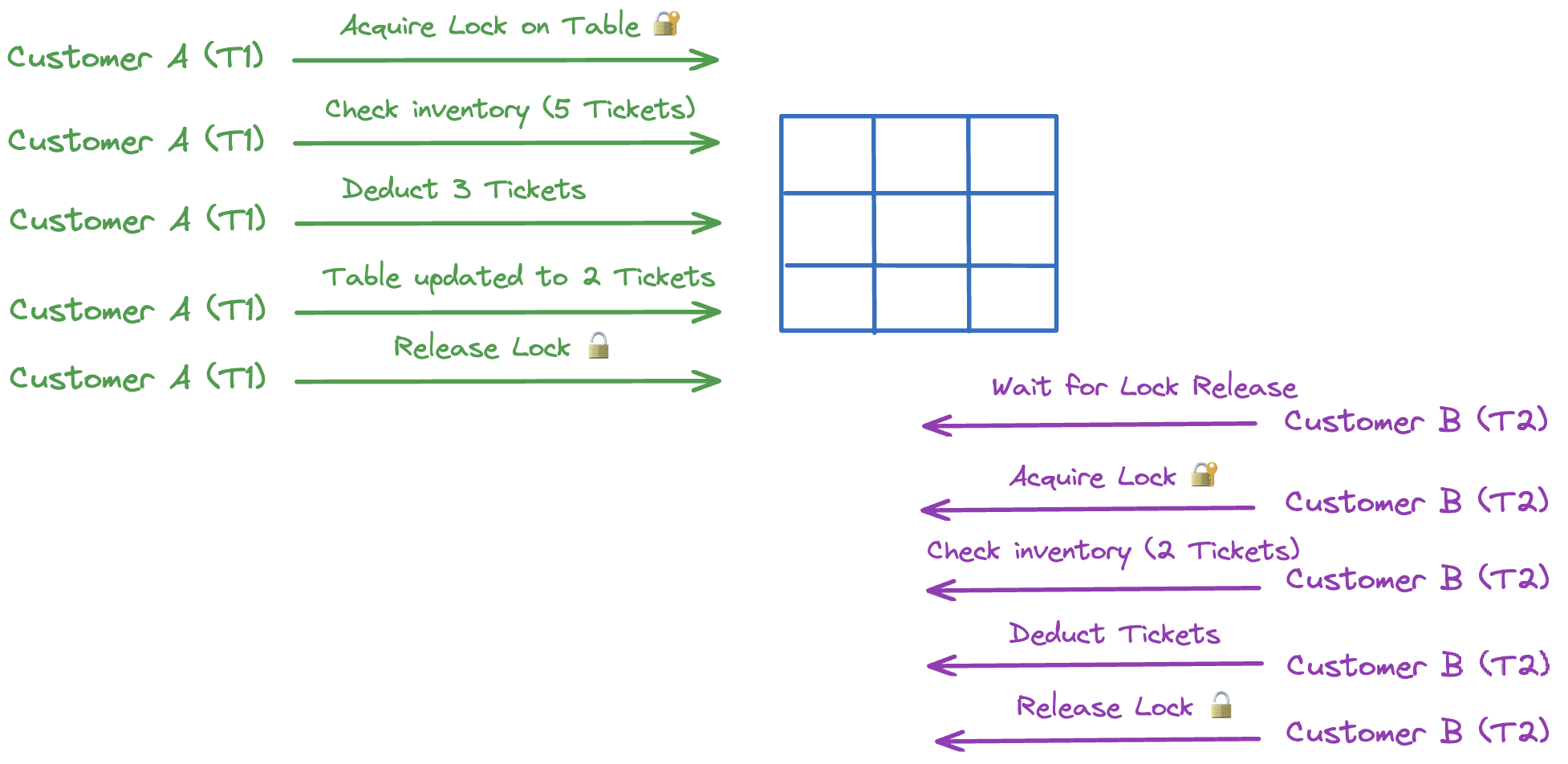
If we take our online concert ticketing system example, where we have 5 tickets left and Customer A and Customer B both attempt to buy 3 tickets simultaneously. With Strict Two-Phase Locking (2PL), Transaction T1 (Customer A’s purchase) acquires an exclusive lock on the inventory, preventing Transaction T2 (Customer B’s purchase) from accessing it until T1 completes. T1 checks the inventory, deducts 3 tickets for Customer A, reducing the count to 2, and then releases the lock. Only then can T2 proceed, locking the inventory, seeing the updated 2 tickets, and completing the purchase for Customer B. This ensures serializability by isolating transactions through locking, yielding the same result as if the transactions had run one after the other.
While Strict 2PL guarantees correctness, it comes with some downsides:
- Transactions waiting to acquire locks may be blocked for long durations, especially in high-contention scenarios, leading to reduced throughput.
- If two transactions hold locks on different resources and wait for each other to release them, a deadlock occurs, requiring intervention (e.g., by aborting one transaction).
- The strict correctness requirements can lead to long transaction times, making it less suitable for high-concurrency workloads.
Strict 2PL is present in relational database systems such as PostgreSQL, and Oracle Database.
Optimistic Concurrency Control (OCC)
Optimistic concurrency control takes the opposite approach - it assumes that conflicts happen rarely, and if there are such scenarios, then it would deal with it at the time of the conflict. OCC works this way:
- Transactions track read and write operations and, upon completion, validate these changes to check for conflicts.
- If conflicts are detected, one or more conflicting transactions are rolled back and can be retried if needed be.
OCC is particularly effective in low-contention environments, where conflicts between transactions are infrequent. However, in scenarios with frequent conflicts, such as multiple transactions attempting to modify the same data, OCC may result in a high number of rollbacks, reducing its efficiency. Its ability to allow multiple transactions to proceed without locking makes it a good choice for workloads where contention is low and throughput is prioritized over strict blocking mechanisms.
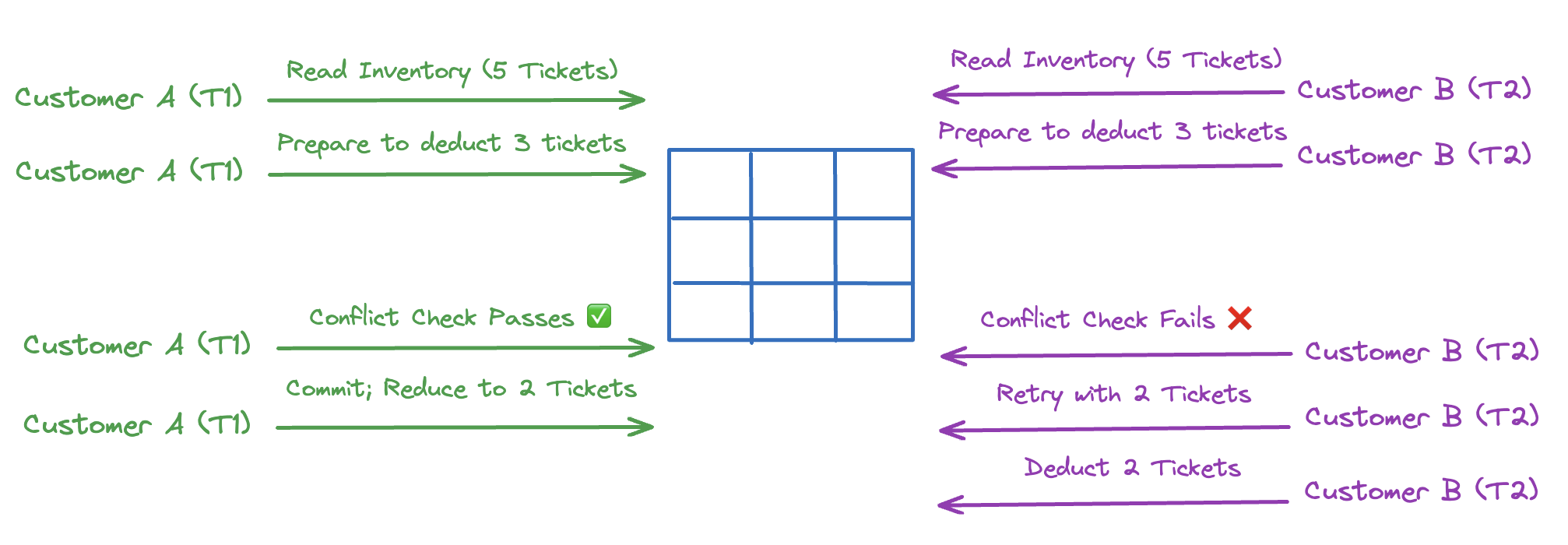
For our example, with OCC, both transactions will proceed, each reading the initial count of 5 tickets and preparing to deduct 3. When they try to commit, a conflict check (history) will reveal that reducing by 3 tickets would oversell the inventory. As a result, one transaction (e.g., Customer B’s) is rolled back, allowing Customer A to complete their purchase, reducing the inventory to 2. Customer B then retries, sees only 2 tickets left, and adjusts accordingly.
Multi-Version Concurrency Control (MVCC)
MVCC enables concurrent transactions by maintaining multiple versions of each data item, allowing transactions to read data as it appeared at a specific point in time. Here’s how MVCC works at a high-level:
- Each transaction is split into a "read set" and a "write set." This separation of read and write sets enhances concurrency by reducing conflicts.
- All reads in a transaction operate as if they are accessing a single, consistent ‘snapshot’ of the data at a particular moment.
- Writes are applied as if they are part of a ‘later snapshot’, ensuring that any changes made by the transaction are isolated from other concurrent transactions until the transaction completes.
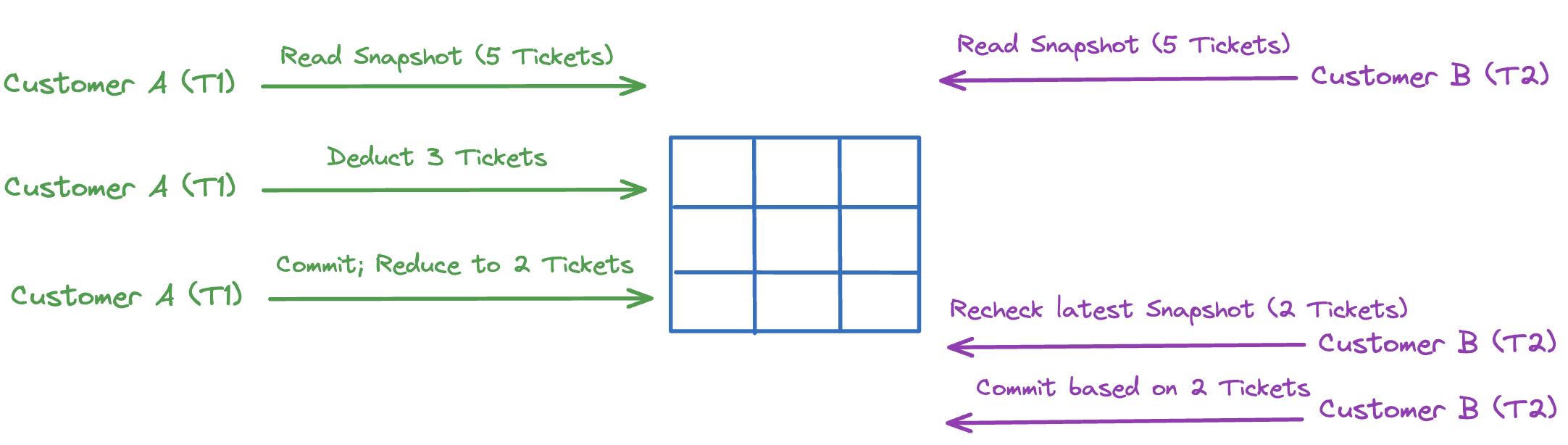
In our example, with MVCC, each customer sees a consistent snapshot of 5 tickets when they start. Customer A completes their purchase first, reducing the inventory to 2 tickets. When Customer B finishes, they commit their transaction based on the latest snapshot, seeing only 2 tickets left and adjusting their purchase accordingly.
Concurrency Control in Open Table Formats
Data lakes were built for scalable storage, cheaper cost, and to address some of the limitations of data warehouses (such as handling varied data types), but they lack the transactional storage engine needed to enforce ACID guarantees. We learnt in our previous section how isolation (the "I" in ACID) plays a critical role in managing concurrency by ensuring that each transaction operates independently without unintended interference from others. This level of isolation is essential for preventing concurrency anomalies like dirty reads, lost updates, and other issues that can compromise data integrity. Data lakehouse architecture with open table formats such as Apache Hudi, Apache Iceberg, and Delta Lake as the foundation for the storage layer addresses this problem by applying some of the concurrency control methods available in the database systems.
Let’s take a look at what type of concurrency control methods are available within these formats with a focus on Apache Hudi.
Apache Hudi
Most of the concurrency control implementations today in lakehouse table formats focus on optimistically handling conflicts. OCC relies on the assumption that conflicts are rare, making it suitable for simple, append-only jobs but inadequate for scenarios that require frequent updates or deletes. In OCC, each job typically takes a table-level lock to check for conflicts by determining if there are overlapping files that multiple jobs have impacted. If a conflict is detected, the job will abort its operation entirely. This could be a problem with certain types of workloads. For example, an ingest job writing data every 30 minutes and a deletion job running every two hours may often conflict, causing the deletion job to fail. In such cases especially with long-running transactions, OCC is problematic because the chance of conflicts increases over time.
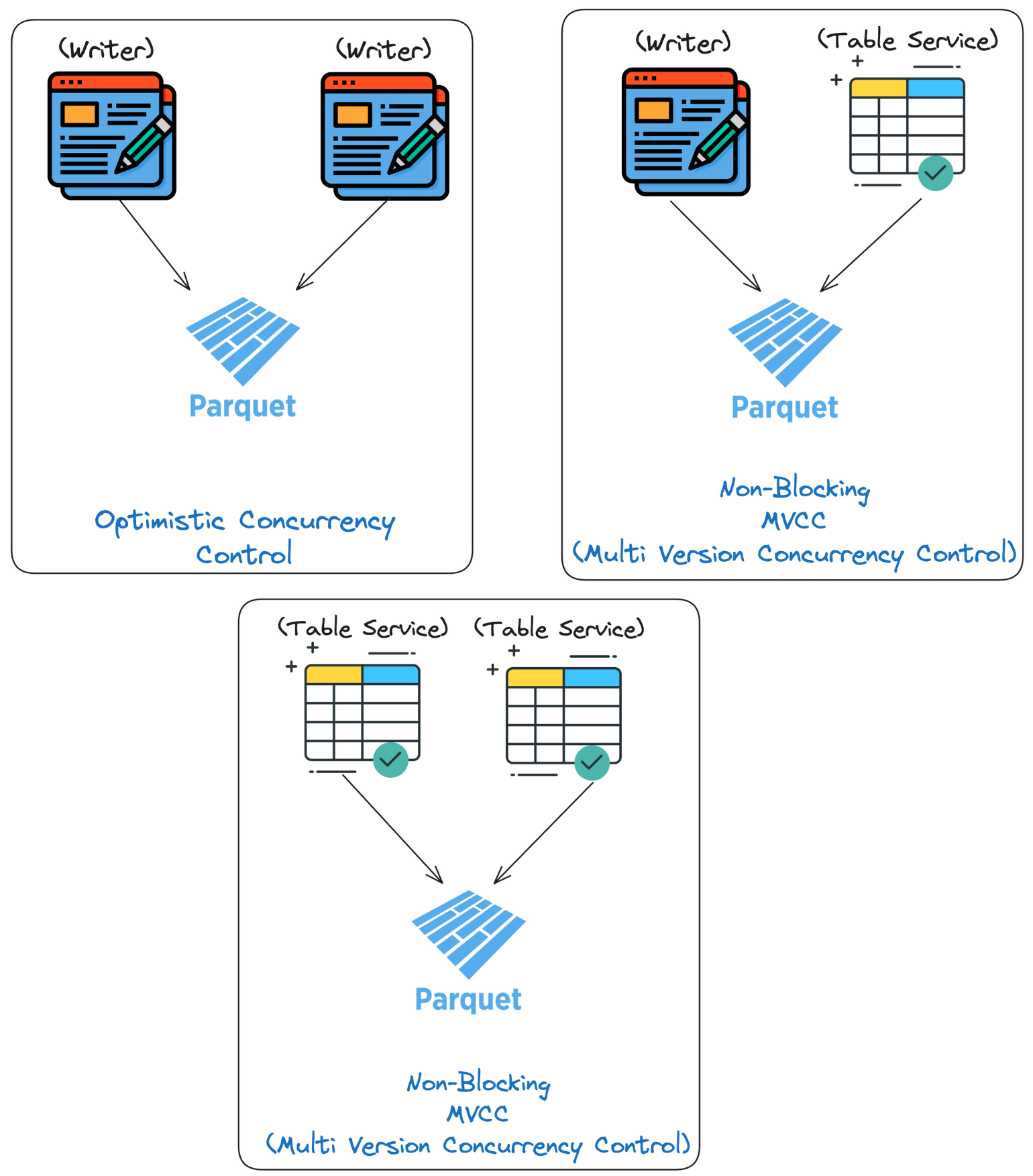
Apache Hudi’s uniqueness lies in the fact that it clearly distinguishes the different actors interacting with the format, i.e. writer processes (that issue user’s upserts/deletes), table services (such as clustering, compaction) and readers (that execute queries and read data). Hudi provides Snapshot Isolation between all three types of processes, meaning they all operate on a consistent snapshot of the table. For writers, Hudi implements a variant of Serializable Snapshot Isolation (SSI). Here’s how Hudi supports different types of concurrency control methods, offering fine-grained control over concurrent data access and updates.
OCC (Multi Writers)
OCC is primarily used to manage concurrent writer processes in Hudi. For example, two different Spark jobs interacting with the same Hudi table to perform updates. Hudi’s OCC workflow involves a series of checks to detect and handle conflicts, ensuring that only one writer can successfully commit changes to a particular file group at any given time. Here’s a quick summary of what file groups and slices mean in Hudi.
File group: Groups multiple versions of a base file (e.g. Parquet). The file group is uniquely identified by a File id. Each version corresponds to the commit's timestamp recording updates to records in the file.
File slice: A File group can further be split into multiple slices. Each file slice within the file-group is uniquely identified by the commit's timestamp that created it.
OCC works in three phases - read, validate and write. When a writer begins a transaction, it first makes the changes, i.e. commits in isolation. During the validation phase, writers compare their proposed changes against existing file groups in the timeline to detect conflicts. Finally, in the write phase, the changes are either committed if no conflicts are found or rolled back if conflicts are detected.
For multi-writing scenarios, when a writer begins the commit process, it acquires a short-duration lock from the lock provider, typically implemented with an external service such as Zookeeper, Hive Metastore, or DynamoDB. Once the lock is secured, the writer loads the current timeline to check for previously completed actions on the targeted file group. After that, it scans for any instances marked as completed with a timestamp greater than the target file slice's timestamp. If any such completed instances are found, it indicates that another writer has already modified the target file group, leading to a conflict. In this case, Hudi’s OCC logic prevents the current transaction from proceeding by aborting the writer’s operation, ensuring that only one writer’s updates are committed. If no conflicting instant exists, the transaction is allowed to proceed, and the writer completes the write operation, adding a new file slice to the timeline. Finally, Hudi updates the timeline with the location of the new file slice and releases the table lock, allowing other transactions to proceed. This approach adheres to the ACID principles providing consistency guarantees.
It is important to note that Hudi acquires locks only at critical points, such as during the commit or while scheduling table services, rather than across the entire transaction. This approach significantly improves concurrency by allowing writers to work in parallel without contention.
Additionally, Hudi’s OCC operates at the file level, meaning conflicts are detected and resolved based on the files being modified. For instance, when two writers work on non-overlapping files, both writes are allowed to succeed. However, if their operations overlap and modify the same set of files, only one transaction will succeed, and the other will be rolled back. This file-level granularity is a significant advantage in many real-world scenarios, as it enables multiple writers to proceed without issues as long as they are working on different files, improving concurrency and overall throughput.
MVCC (Writer-Table Service and Table Service-Table Service)
Apache Hudi provides support for Multiversion Concurrency Control (MVCC) between writers and table-services (for example, an update Spark job and clustering) and between different table services (such as compaction and clustering). Similar to OCC, the Hudi timeline is instrumental in Hudi’s MVCC implementation, which keeps a track of all the events (instants) happening in a particular Hudi table. Every writer and reader relies on the file system’s state to decide where to carry out the operations, thereby providing read-write isolation.
When a write operation begins, Hudi marks the action as either requested or inflight on the timeline, making all processes aware of the ongoing operation. This ensures that table management operations such as compaction and clustering are aware of active writes and do not include the file slices currently being modified. With Hudi 1.0's new timeline design, compaction and clustering operations are now based on both the requested and completion times of actions, treating these timestamps as intervals to dynamically determine file slices. This means a service like compaction no longer needs to block ongoing writes and can be scheduled at any instant without interfering with active operations.
Under the new design, file slicing includes only those file slices whose completion times precede the start of the compaction or clustering process. This intelligent slicing mechanism ensures that these table management services work only on finalized data while new writes seamlessly continue without impacting the base files being compacted. By decoupling the scheduling of table services from active writes, Hudi 1.0 eliminates the need for strict scheduling sequences or blocking behaviors.
Non-Blocking Concurrency Control (Multi Writers)
In a generic sense, Non-Blocking Concurrency Control (NBCC) allows multiple transactions to proceed simultaneously without locking, reducing delays and improving throughput in high-concurrency environments. Hudi 1.0 introduces a new concurrency mode, NON_BLOCKING_CONCURRENCY_CONTROL, where, unlike OCC, multiple writers can operate on the same table simultaneously with non-blocking conflict resolution. This approach eliminates the need for explicit locks to serialize writes, enabling higher concurrency. Instead of requiring each writer to wait, NBCC allows concurrent writes to proceed, making it ideal for real-time applications that demand faster data ingestion.
In NBCC, the only lock required is for writing the commit metadata to the Hudi timeline, which ensures that the order and state of completed transactions is tracked accurately. With the release of version 1.0, Hudi introduces TrueTime semantics for instant times on the timeline, ensuring unique and monotonically increasing instant values. Each action on the Hudi timeline now includes both a requested time and a completion time, enabling these actions to be treated as intervals. This allows for more precise conflict detection by reasoning about overlapping actions within these time intervals. The final serialization of writes in NBCC is determined by the completion times. This means multiple writers can modify the same file group, with conflicts resolved automatically by query readers and the compactor. NBCC is available with the new Hudi 1.0 release, thereby providing more controls to balance speed with data consistency, even under heavy concurrent workloads.
Concurrency Control Deployment Modes in Hudi
Hudi offers several deployment models to handle different concurrency needs, allowing users to optimize for performance, simplicity, or high-concurrency scenarios depending on the requirements.
Single Writer with Inline Table Services
In this model, only one writer handles data ingestion or updates, with table services (such as cleaning, compaction, and clustering) running inline sequentially after every write. This approach eliminates the need for concurrency control as all operations occur in a single process. MVCC in Hudi guarantees that readers see consistent snapshots, isolating them from ongoing writes and table services. This model is ideal for straightforward use cases where the focus is on getting data into the lakehouse without the complexity of managing multiple writers.
Single Writer with Async Table Services
For workloads that require higher throughput without blocking writers, Hudi supports asynchronous table services. In this model, a single writer continuously ingests data, while table services such as compaction and clustering run asynchronously in the same process. MVCC allows these background jobs to operate concurrently with ingestion without creating conflicts, as they coordinate to avoid race conditions. This model suits applications where ingestion speed is essential, as async services help optimize the table in the background, reducing operational complexity without the need for external orchestration.
Multi-Writer Configuration
In cases where multiple writer jobs need to access the same table, Hudi supports multi-writer setups. This model allows disparate processes, such as multiple ingestion writers or a mix of ingestion and separate table service jobs to write concurrently. To manage conflicts, Hudi uses OCC with file-level conflict resolution, allowing non-overlapping writes to proceed while conflicting writes are resolved by allowing only one to succeed. For these types of multi-writer setups, external lock providers like Amazon DynamoDB, Zookeeper, or Hive Metastore are required to coordinate concurrent access. This setup is ideal for production-level, high-concurrency environments where different processes need to modify the table simultaneously.
Note that while Hudi provides OCC to deal with multiple writers, table services can still run asynchronously and without locks if they operate in the same process as the writer. This is because Hudi intelligently differentiates between the different types of actors (writers, table services) that interact with the table.
You will need to set the following properties to activate OCC with locks.
hoodie.write.concurrency.mode=optimistic_concurrency_control
hoodie.write.lock.provider=<lock-provider-classname>
hoodie.cleaner.policy.failed.writes=LAZY
Hoodie.write.lock.provider defines the lock provider class that manages locks for concurrent writes. Default is org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider
The LAZY mode cleans failed writes only after a heartbeat timeout when the cleaning service runs and is recommended when using multiple writers.
How to use OCC with Apache Hudi and Apache Spark
This is a simple example where we configure OCC by setting the hoodie.write.concurrency.mode to optimistic_concurrency_control. We also specify a lock provider (in this case, Zookeeper) to manage concurrent access, along with essential table options like the precombine field, record key, and partition path.
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder \
.appName("Hudi Example with OCC") \
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") \
.getOrCreate()
# Sample DataFrame
inputDF = spark.createDataFrame([
(1, "2024-11-19 10:00:00", "A", "partition1"),
(2, "2024-11-19 10:05:00", "B", "partition1")
], ["uuid", "ts", "value", "partitionpath"])
tableName = "my_hudi_table"
basePath = "s3://path-to-your-hudi-table"
# Write DataFrame to Hudi with OCC and Zookeeper lock provider
inputDF.write.format("hudi") \
.option("hoodie.datasource.write.precombine.field", "ts") \
.option("hoodie.cleaner.policy.failed.writes", "LAZY") \
.option("hoodie.write.concurrency.mode", "optimistic_concurrency_control") \
.option("hoodie.write.lock.provider", "org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider") \
.option("hoodie.write.lock.zookeeper.url", "zk-cs.hudi-infra.svc.cluster.local") \
.option("hoodie.write.lock.zookeeper.port", "2181") \
.option("hoodie.write.lock.zookeeper.base_path", "/test") \
.option("hoodie.datasource.write.recordkey.field", "uuid") \
.option("hoodie.datasource.write.partitionpath.field", "partitionpath") \
.option("hoodie.table.name", tableName) \
.mode("overwrite") \
.save(basePath)
spark.stop()
Apache Iceberg
Apache Iceberg supports multiple concurrent writes through Optimistic Concurrency Control (OCC). The most important part to note here is that Iceberg needs a catalog component to adhere to the ACID guarantees. Each writer assumes it is the only one making changes, generating new table metadata for its operation. When a writer completes its updates, it attempts to commit the changes by performing an atomic swap of the latest metadata.json file in the catalog, replacing the existing metadata file with the new one.
If this atomic swap fails (due to another writer committing changes in the meantime), the writer’s commit is rejected. The writer then retries the entire process by creating a new metadata tree based on the latest state of the table and attempting the atomic swap again.
When it comes to table maintenance tasks, such as optimizations (e.g., compaction) or large delete jobs, Iceberg treats these as regular writes. These operations can overlap with ingestion jobs, but they follow the same OCC principles - conflicts are resolved by retrying based on the latest table state. Users are recommended to schedule such jobs during official maintenance periods to avoid contention, as frequent retries due to conflicts can impact performance.
Delta Lake
Delta Lake provides concurrency control through Optimistic Concurrency Control (OCC) for transactional guarantees between writes. OCC allows multiple writers to attempt changes independently, assuming conflicts are infrequent. When a writer tries to commit, it checks for any conflicting updates from other transactions in the transaction log. If a conflict is found, the transaction is rolled back, and the writer retries based on the latest version of the data.
Additionally, Delta Lake employs Multi-Version Concurrency Control (MVCC) within the file system to separate reads from writes. By keeping data objects and the transaction log immutable, MVCC allows readers to access a consistent snapshot of the data, even as new writes are added. This not only protects existing data from modification during concurrent transactions but also enables time-travel queries, allowing users to query historical snapshots.
Conclusion
Concurrency control is critical for Open lakehouse architectures, especially when your architecture has multiple concurrent pipelines interacting with the same table. Open table formats such as Apache Hudi bring well-established concurrency control methods from traditional database systems into the Lakehouse architecture to handle these operations while maintaining data consistency and scalability. Apache Hudi’s unique design to distinguish between writers, table services, and readers ensures snapshot isolation across all three processes. By supporting multiple concurrency control methods, such as OCC for managing writer conflicts, MVCC for isolating background table services and writers, and a novel NBCC for non-blocking, real-time ingestion, Hudi offers greater flexibility with complex workloads.
FAQ
What concurrency control methods do open table formats use?
The main methods, adapted from database systems, are pessimistic locking (2PL), optimistic concurrency control (OCC), and multi-version concurrency control (MVCC). Apache Iceberg and Delta Lake rely on OCC for concurrent writes, with Delta Lake also using MVCC to separate reads from writes. Apache Hudi supports OCC between writers, MVCC between writers and table services, and additionally non-blocking concurrency control (NBCC).
When does optimistic concurrency control become a problem?
OCC assumes conflicts are rare, so it suits simple, append-only jobs. With frequent updates or deletes, a detected conflict aborts the job entirely. For example, an ingest job writing every 30 minutes and a deletion job running every two hours may often overlap, causing the deletion job to fail repeatedly - and with long-running transactions the chance of conflict grows over time.
How does Apache Hudi reduce contention between writers and table services?
Hudi distinguishes between writers, table services, and readers, providing snapshot isolation across all three. It uses MVCC between writers and table services, so operations like compaction and clustering run without blocking active writes. Locks are acquired only at critical points, such as during a commit, rather than across the whole transaction, and OCC conflict detection works at the file level so non-overlapping writes both succeed.
What is non-blocking concurrency control (NBCC)?
NBCC is a concurrency mode introduced in Hudi 1.0 where multiple writers operate on the same table simultaneously, with conflicts resolved automatically by query readers and the compactor rather than by aborting writers. The only lock needed is for writing commit metadata to the timeline, and the final serialization of writes is determined by completion times using Hudi's TrueTime semantics.
Do I need an external lock provider to run multiple Hudi writers?
For multi-writer setups using OCC, yes - an external lock provider such as Amazon DynamoDB, Zookeeper, or Hive Metastore coordinates concurrent access, together with hoodie.write.concurrency.mode=optimistic_concurrency_control and a LAZY failed-writes cleaning policy. Table services can still run lock-free and asynchronously when they operate in the same process as the writer.