Compaction
Background
Compaction is a table service employed by Hudi specifically in Merge-on-Read (MOR) tables to merge updates from row-based log files to the corresponding columnar-based base file periodically to produce a new version of the base file. Compaction is not applicable to Copy-on-Write (COW) tables and only applies to MOR tables.
Why MOR tables need compaction?
To understand the significance of compaction in MOR tables, it is helpful to understand the MOR table layout first. In Hudi, data is organized in terms of file groups. Each file group in a MOR table consists of a base file and one or more log files. Typically, during writes, inserts are stored in the base file, and updates are appended to log files.
 Figure: MOR table file layout showing different file groups with base data file and log files
Figure: MOR table file layout showing different file groups with base data file and log files
During the compaction process, updates from the log files are merged with the base file to form a new version of the base file as shown below. Since MOR is designed to be write-optimized, on new writes, after index tagging is complete, Hudi appends the records pertaining to each file groups as log blocks in log files. There is no synchronous merge happening during write, resulting in a lower write amplification and better write latency. In contrast, on new writes to a COW table, Hudi combines the new writes with the older base file to produce a new version of the base file resulting in a higher write amplification and higher write latencies.
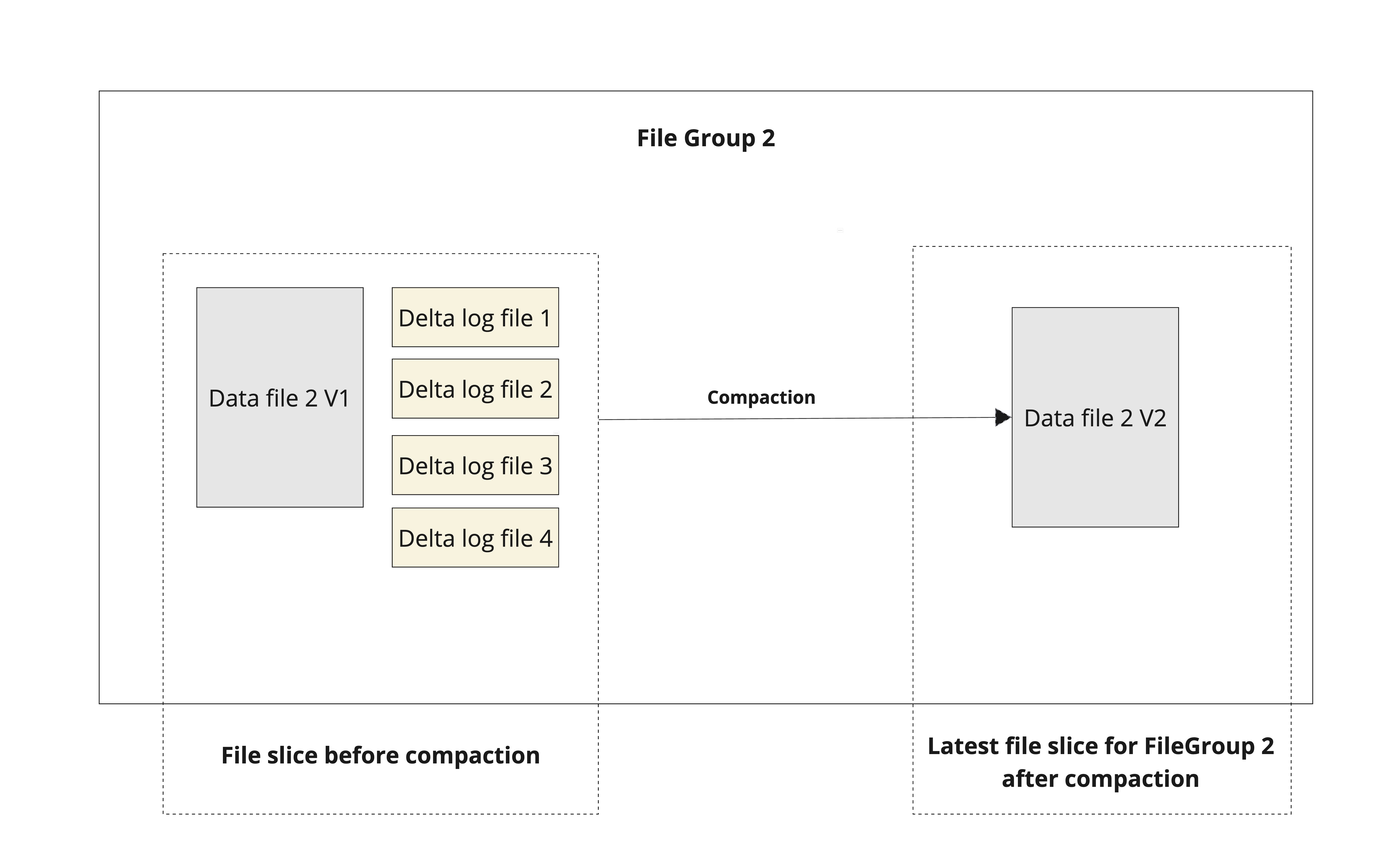 Figure: Compaction on a given file group
Figure: Compaction on a given file group
While serving the read query(snapshot read), for each file group, records in base file and all its corresponding log files are merged together and served. And hence the read latency for MOR snapshot query might be higher compared to COW table since there is no merge involved in case of COW at read time. Compaction takes care of merging the updates from log files with the base file at regular intervals to bound the growth of log files and to ensure the read latencies do not spike up.
Compaction Architecture
There are two steps to compaction.
- Compaction Scheduling: In this step, Hudi scans the partitions and selects file slices to be compacted. A compaction plan is finally written to Hudi timeline.
- Compaction Execution: In this step the compaction plan is read and file slices are compacted.
Strategies in Compaction Scheduling
There are two strategies involved in scheduling the compaction:
- Trigger Strategy: Determines how often to trigger scheduling of the compaction.
- Compaction Strategy: Determines which file groups to compact.
Hudi provides various options for both these strategies as discussed below.
Incremental Scheduling
Hudi supports incremental scheduling for compaction operations, which significantly improves performance on tables with a large number of partitions. Instead of scanning all partitions during each compaction scheduling run, incremental scheduling only processes partitions that have changed since the last completed compaction.
This feature is enabled by default via hoodie.table.services.incremental.enabled. When enabled, compaction scheduling will:
- Identify partitions that have been modified since the last completed compaction by analyzing commit metadata within the time window between the last completed compaction and the current scheduling instant
- Include any partitions that were marked as missing from previous scheduling runs (e.g., due to IO limits)
- Only scan and process those incremental partitions
- Fall back to scanning all partitions if the last completed compaction instant cannot be found (e.g., due to archival) or if an exception occurs during incremental partition retrieval
For tables with many partitions, this optimization can dramatically reduce scheduling overhead and improve overall job stability.
Trigger Strategies
| Config Name | Default | Description ||
|----------------------------------------------------|-------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------|
| hoodie.compact.inline.trigger.strategy | NUM_COMMITS (Optional) | org.apache.hudi.table.action.compact.CompactionTriggerStrategy: Controls when compaction is scheduled.Config Param: INLINE_COMPACT_TRIGGER_STRATEGY
NUM_COMMITS: triggers compaction when there are at least N delta commits after last completed compaction.NUM_COMMITS_AFTER_LAST_REQUEST: triggers compaction when there are at least N delta commits after last completed or requested compaction.TIME_ELAPSED: triggers compaction after N seconds since last compaction.NUM_AND_TIME: triggers compaction when both there are at least N delta commits and N seconds elapsed (both must be satisfied) after last completed compaction.NUM_OR_TIME: triggers compaction when both there are at least N delta commits or N seconds elapsed (either condition is satisfied) after last completed compaction.
Compaction Strategies
| Config Name | Default | Description |
|---|---|---|
| hoodie.compaction.strategy | org.apache.hudi.table.action.compact.strategy.LogFileSizeBasedCompactionStrategy (Optional) | Compaction strategy decides which file groups are picked up for compaction during each compaction run. By default. Hudi picks the log file with most accumulated unmerged data. Config Param: COMPACTION_STRATEGY |
Available Strategies (Provide the full package name when using the strategy):
LogFileNumBasedCompactionStrategy: orders the compactions based on the total log files count, filters the file group with log files count greater than the threshold and limits the compactions within a configured IO bound.LogFileSizeBasedCompactionStrategy: orders the compactions based on the total log files size, filters the file group which log files size is greater than the threshold and limits the compactions within a configured IO bound.BoundedIOCompactionStrategy: CompactionStrategy which looks at total IO to be done for the compaction (read + write) and limits the list of compactions to be under a configured limit on the IO.BoundedPartitionAwareCompactionStrategy:This strategy ensures that the last N partitions are picked up even if there are later partitions created for the table. lastNPartitions is defined as the N partitions before the currentDate. currentDay = 2018/01/01 The table has partitions for 2018/02/02 and 2018/03/03 beyond the currentDay This strategy will pick up the following partitions for compaction : (2018/01/01, allPartitionsInRange[(2018/01/01 - lastNPartitions) to 2018/01/01), 2018/02/02, 2018/03/03)DayBasedCompactionStrategy:This strategy orders compactions in reverse order of creation of Hive Partitions. It helps to compact data in latest partitions first and then older capped at the Total_IO allowed.UnBoundedCompactionStrategy: UnBoundedCompactionStrategy will not change ordering or filter any compaction. It is a pass-through and will compact all the base files which has a log file. This usually means no-intelligence on compaction.UnBoundedPartitionAwareCompactionStrategy:UnBoundedPartitionAwareCompactionStrategy is a custom UnBounded Strategy. This will filter all the partitions that are eligible to be compacted by a {@link BoundedPartitionAwareCompactionStrategy} and return the result. This is done so that a long running UnBoundedPartitionAwareCompactionStrategy does not step over partitions in a shorter running BoundedPartitionAwareCompactionStrategy. Essentially, this is an inverse of the partitions chosen in BoundedPartitionAwareCompactionStrategy
Please refer to advanced configs for more details.
Ways to trigger Compaction
Inline
By default, compaction is run asynchronously.
If latency of ingesting records is important for you, you are most likely using Merge-on-Read tables. Merge-on-Read tables store data using a combination of columnar (e.g parquet) + row based (e.g avro) file formats. Updates are logged to delta files & later compacted to produce new versions of columnar files. To improve ingestion latency, Async Compaction is the default configuration.
If immediate read performance of a new commit is important for you, or you want simplicity of not managing separate compaction jobs, you may want synchronous inline compaction, which means that as a commit is written it is also compacted by the same job.
For this deployment mode, please use hoodie.compact.inline = true for Spark Datasource and Spark SQL writers. For
Hudi Streamer sync once mode inline compaction can be achieved by passing the flag --disable-compaction (Meaning to
disable async compaction). Further in Hudi Streamer when both
ingestion and compaction is running in the same spark context, you can use resource allocation configuration
in Hudi Streamer CLI such as (--delta-sync-scheduling-weight,
--compact-scheduling-weight, --delta-sync-scheduling-minshare, and --compact-scheduling-minshare)
to control executor allocation between ingestion and compaction.
Async & Offline Compaction models
There are a couple of ways here to trigger compaction .
Async execution within the same process
In streaming ingestion write models like Hudi Streamer continuous mode, Flink and Spark Streaming, async compaction is enabled by default and runs alongside without blocking regular ingestion.
Spark Structured Streaming
Compactions are scheduled and executed asynchronously inside the streaming job.Here is an example snippet in java
import org.apache.hudi.DataSourceWriteOptions;
import org.apache.hudi.HoodieDataSourceHelpers;
import org.apache.hudi.config.HoodieCompactionConfig;
import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.spark.sql.streaming.OutputMode;
import org.apache.spark.sql.streaming.ProcessingTime;
DataStreamWriter<Row> writer = streamingInput.writeStream().format("org.apache.hudi")
.option("hoodie.datasource.write.operation", operationType)
.option("hoodie.datasource.write.table.type", tableType)
.option("hoodie.datasource.write.recordkey.field", "_row_key")
.option("hoodie.datasource.write.partitionpath.field", "partition")
.option("hoodie.table.ordering.fields", "timestamp")
.option("hoodie.compact.inline.max.delta.commits", "10")
.option("hoodie.datasource.compaction.async.enable", "true")
.option("hoodie.table.name", tableName).option("checkpointLocation", checkpointLocation)
.outputMode(OutputMode.Append());
writer.trigger(new ProcessingTime(30000)).start(tablePath);
Hudi Streamer Continuous Mode
Hudi Streamer provides continuous ingestion mode where a single long running spark application ingests data to Hudi table continuously from upstream sources. In this mode, Hudi supports managing asynchronous compactions. Here is an example snippet for running in continuous mode with async compactions
spark-submit --packages org.apache.hudi:hudi-utilities-slim-bundle_2.12:1.0.2,org.apache.hudi:hudi-spark3.5-bundle_2.12:1.0.2 \
--class org.apache.hudi.utilities.streamer.HoodieStreamer \
--table-type MERGE_ON_READ \
--target-base-path <hudi_base_path> \
--target-table <hudi_table> \
--source-class org.apache.hudi.utilities.sources.JsonDFSSource \
--source-ordering-field ts \
--props /path/to/source.properties \
--continous
Scheduling and Execution by a separate process
For some use cases with long running table services, instead of having the regular writes block, users have the option to run both steps of the compaction (scheduling and execution) offline in a separate process altogether. This allows for regular writers to not bother about these compaction steps and allows users to provide more resources for the compaction job as needed.
This model needs a lock provider configured for all jobs - the regular writer as well as the offline compaction job.
Scheduling inline and executing async
In this model, it is possible for a Spark Datasource writer or a Flink job to just schedule the compaction inline ( that will serialize the compaction plan in the timeline but will not execute it). And then a separate utility like HudiCompactor or HoodieFlinkCompactor can take care of periodically executing the compaction plan.
This model may need a lock provider if metadata table is enabled.
Hudi Compactor Utility
Hudi provides a standalone tool to execute specific compactions asynchronously. Below is an example and you can read more in the deployment guide The compactor utility allows to do scheduling and execution of compaction.
Example:
spark-submit --packages org.apache.hudi:hudi-utilities-slim-bundle_2.12:1.0.2,org.apache.hudi:hudi-spark3.5-bundle_2.12:1.0.2 \
--class org.apache.hudi.utilities.HoodieCompactor \
--base-path <base_path> \
--table-name <table_name> \
--schema-file <schema_file> \
--instant-time <compaction_instant>
Note, the instant-time parameter is now optional for the Hudi Compactor Utility. If using the utility without --instant time,
the spark-submit will execute the earliest scheduled compaction on the Hudi timeline.
Available Options
The HoodieCompactor utility supports the following retry and timeout options (effective in scheduleAndExecute mode):
| Option Name | Short Flag | Default | Description |
|---|---|---|---|
--retry-last-failed-job | -rc | false | When set to true, checks, rolls back, and executes the last failed compaction plan instead of planning a new compaction job directly. This is useful for recovering from previous failures. |
--job-max-processing-time-ms | -jt | 0 | Maximum processing time in milliseconds before considering a compaction job as failed. If this time is exceeded and the job is still unfinished, Hudi will consider the job as failed and relaunch it (when used with --retry-last-failed-job). A value of 0 or negative disables the timeout check. |
These retry options are only effective when using --mode scheduleAndExecute. The --retry-last-failed-job option requires --job-max-processing-time-ms to be set to a positive value to detect stale inflight instants.
Hudi CLI
Hudi CLI is yet another way to execute specific compactions asynchronously. Here is an example and you can read more in the deployment guide
Example:
hudi:trips->compaction run --tableName <table_name> --parallelism <parallelism> --compactionInstant <InstantTime>
...
Flink Offline Compaction
Offline compaction needs to submit the Flink task on the command line. The program entry is as follows: hudi-flink-bundle_2.11-0.9.0-SNAPSHOT.jar :
org.apache.hudi.sink.compact.HoodieFlinkCompactor
# Command line
./bin/flink run -c org.apache.hudi.sink.compact.HoodieFlinkCompactor lib/hudi-flink-bundle_2.11-0.9.0.jar --path hdfs://xxx:9000/table
Options
| Option Name | Default | Description |
|---|---|---|
--path | n/a **(Required)** | The path where the target table is stored on Hudi |
--compaction-max-memory | 100 (Optional) | The index map size of log data during compaction, 100 MB by default. If you have enough memory, you can turn up this parameter |
--schedule | false (Optional) | whether to execute the operation of scheduling compaction plan. When the write process is still writing, turning on this parameter have a risk of losing data. Therefore, it must be ensured that there are no write tasks currently writing data to this table when this parameter is turned on |
--seq | LIFO (Optional) | The order in which compaction tasks are executed. Executing from the latest compaction plan by default. LIFO: executing from the latest plan. FIFO: executing from the oldest plan. |
--service | false (Optional) | Whether to start a monitoring service that checks and schedules new compaction task in configured interval. |
--min-compaction-interval-seconds | 600(s) (optional) | The checking interval for service mode, by default 10 minutes. |
--retry | 0 (Optional) | Number of retries for compaction operation. Only effective in single-run mode (not service mode). Default is 0 (no retry). |
--retry-last-failed-job | false (Optional) | Check and retry last failed compaction job if the inflight instant exceeds max processing time. Only effective in single-run mode. Requires --job-max-processing-time-ms to be set to a positive value. |
--job-max-processing-time-ms | 0 (Optional) | Maximum processing time in milliseconds before considering a compaction job as failed. Used with --retry-last-failed-job. Default 0 means no timeout check. |
The retry options (--retry, --retry-last-failed-job, --job-max-processing-time-ms) are only effective in single-run mode, not in service mode. Service mode has implicit retry semantics via its continuous monitoring loop. A warning will be logged if --retry-last-failed-job is enabled but --job-max-processing-time-ms is not set to a positive value.