Record Level Index: Hudi's blazing fast indexing for large-scale datasets


Introduction
Index is a critical component that facilitates quick updates and deletes for Hudi writers, and it plays a pivotal role in boosting query executions as well. Hudi provides several index types, including the Bloom and Simple indexes with global variations, the HBase Index that leverages a HBase server, the hash-based Bucket index, and the multi-modal index realized through the metadata table. The choice of an index depends on factors such as table sizes, partition data distributions, or traffic patterns, where a specific index may be more suitable for simpler operation or better performance[^1]. Users often face trade-offs when selecting index types for different tables, since there hasn't been a generally performant index capable of facilitating both writes and reads with minimal operational overhead.
Starting from Hudi 0.14.0, we are thrilled to announce a general purpose index for Apache Hudi - the Record Level Index (RLI). This innovation not only dramatically boosts write efficiency but also improves read efficiency for relevant queries. Integrated seamlessly within the table storage layer, RLI can easily work without any additional operational efforts.
In the subsequent sections of this blog, we will give a brief introduction to Hudi's metadata table, a pre-requisite for discussing RLI. Following that, we will delve into the design and workflows of RLI, and then show performance analysis and index type comparisons. The blog will conclude with insights into future work for RLI.
Metadata table
A Hudi metadata table is a Merge-on-Read (MoR) table within the .hoodie/metadata/ directory. It contains various
metadata pertaining to records, seamlessly integrated into both the writer and reader paths to improve indexing efficiency.
The metadata is segregated into four partitions: files, column stats, bloom filters, and record level index.
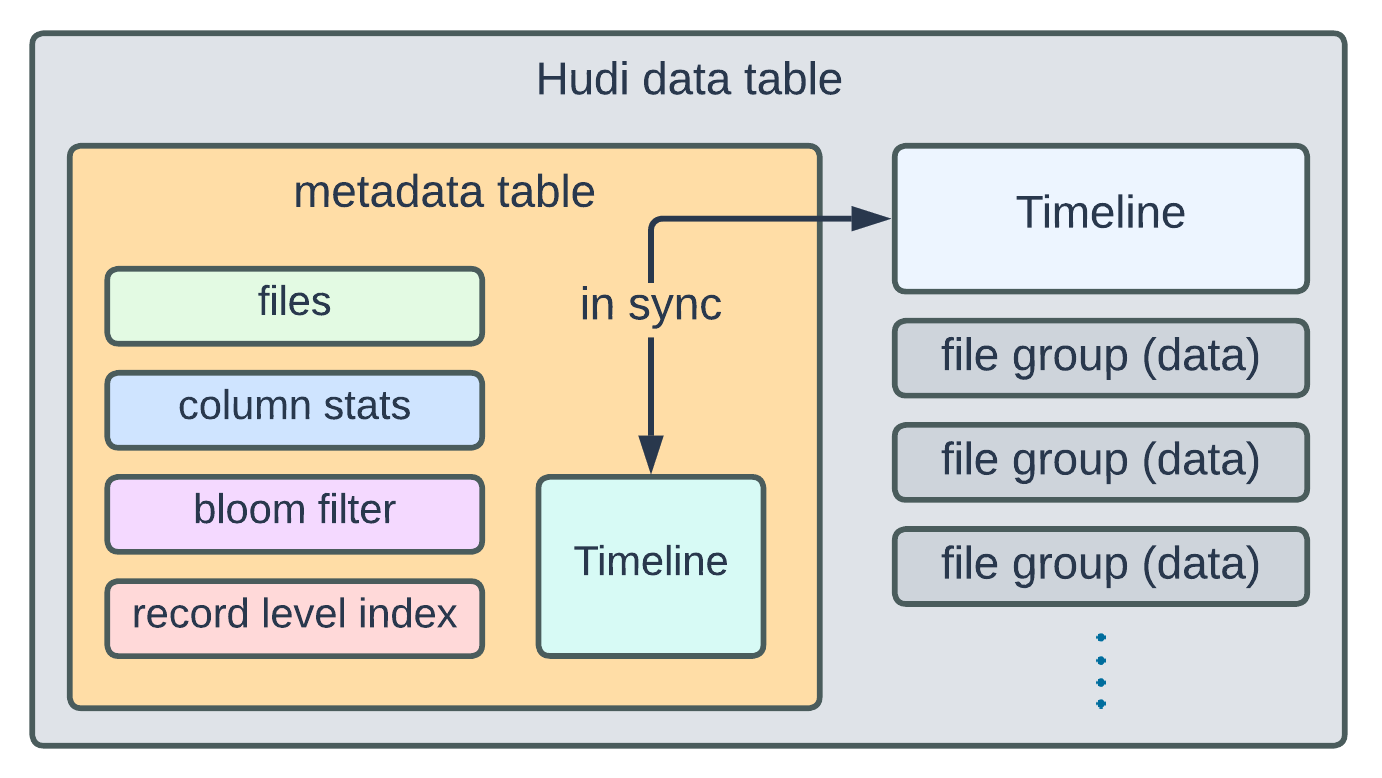
The metadata table is updated synchronously with each commit action on the Timeline, in other words, the commits to the metadata table are part of the transactions to the Hudi data table. With four partitions containing different types of metadata, this layout serves the purpose of a multi-modal index:
filespartition keeps track of the Hudi data table’s partitions, and data files of each partitioncolumn statspartition records statistics about each column of the data tablebloom filterpartition stores serialized bloom filters for base filesrecord level indexpartition contains mappings of individual record key and the corresponding file group id
Users can activate the metadata table by setting hoodie.metadata.enable=true. Once activated, the files partition
will always be enabled. Other partitions can be enabled and configured individually to harness additional indexing
capabilities.
Record Level Index
Starting from release 0.14.0, the Record Level Index (RLI) can be activated by setting hoodie.metadata.record.index.enable=true
and hoodie.index.type=RECORD_INDEX. The core concept behind RLI is the ability to determine the location of records, thus
reducing the number of files that need to be scanned to extract the desired data. This process is usually referred to as "index look-up".
Hudi employs a primary-key model, requiring each record to be associated with a key
to satisfy the uniqueness constraint. Consequently, we can establish one-to-one mappings between record keys and file groups,
precisely the data we intend to store within the record level index partition.
Performance is paramount when it comes to indexes. The metadata table, which includes the RLI partition, chooses HFile[^2], HBase’s file format that utilizes B+ tree-like structures for fast look-up, as the file format. Real-world benchmarking has shown that an HFile containing 1 million RLI mappings can look up a batch of 100k records in just 600 ms. We will cover the performance topic in a later section with detailed analysis.
Initialization
Initializing the RLI partition for an existing Hudi table can be a laborious and time-consuming task, contingent on the number of records. Just like with a typical database, building indexes takes time, but the investment ultimately pays off by speeding up numerous queries in the future.
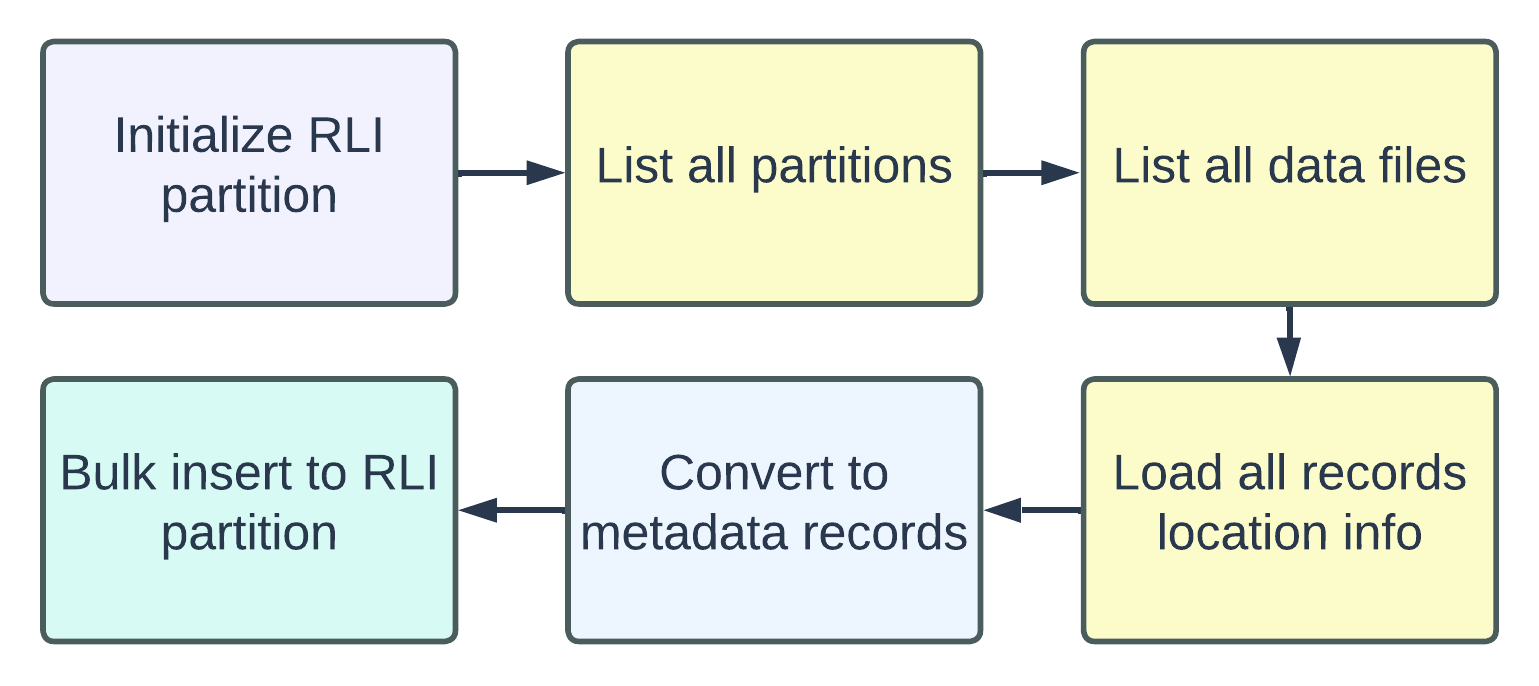
The diagram above shows the high-level steps of RLI initialization. Since these jobs are all parallelizable, users can
scale the cluster and configure relevant parallelism settings (e.g., hoodie.metadata.max.init.parallelism) accordingly
to meet their time requirement.
Focusing on the final step, "Bulk insert to RLI partition," the metadata table writer employs a hash function to partition the RLI records, ensuring that the number of resulting file groups aligns with the number of partitions. This guarantees consistent record key look-ups.
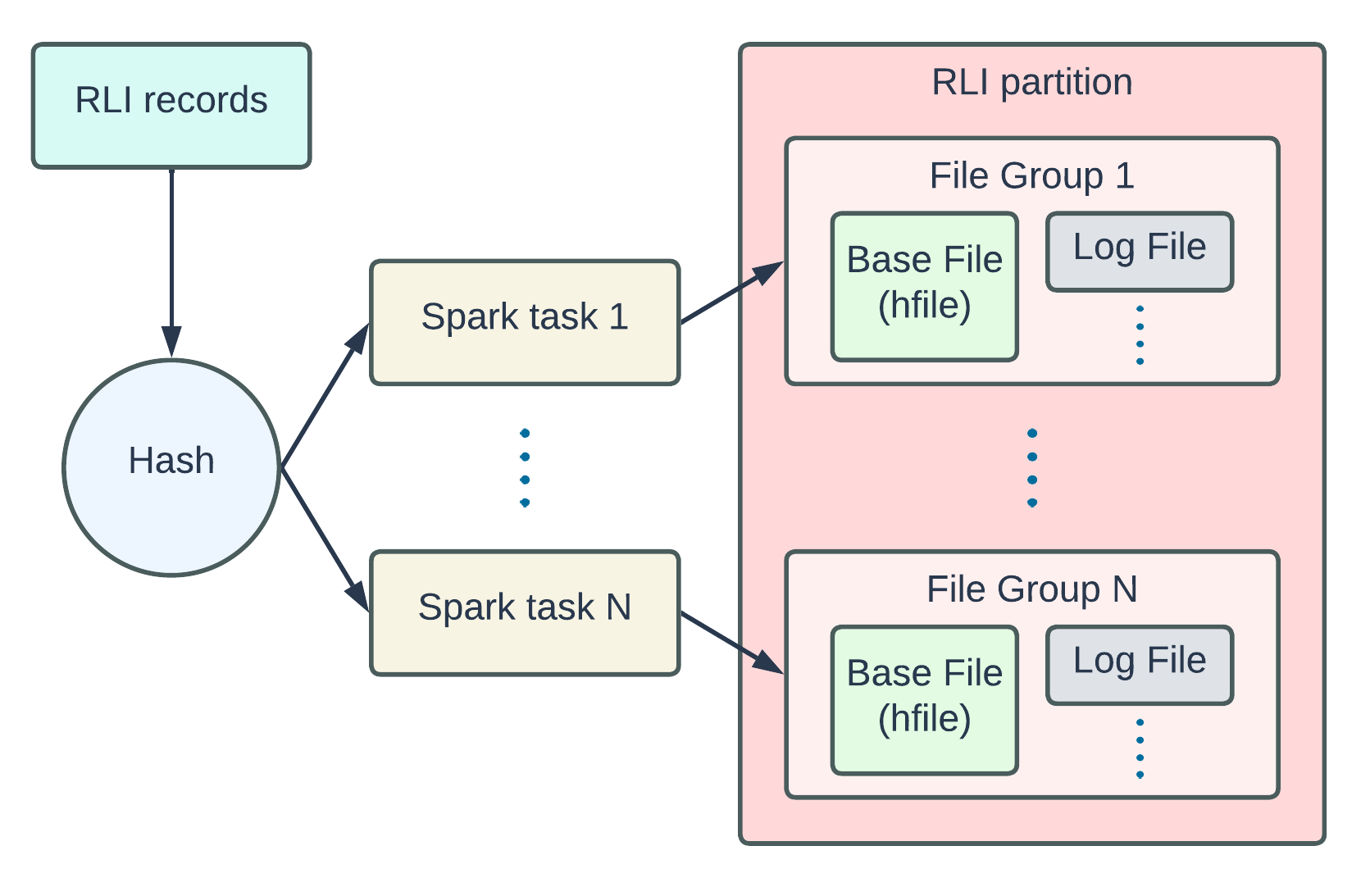
It’s important to note that the current implementation fixes the number of file groups in the RLI partition once it’s initialized. Therefore, users should lean towards over-provisioning the file groups and adjust these configurations accordingly.
hoodie.metadata.record.index.max.filegroup.count
hoodie.metadata.record.index.min.filegroup.count
hoodie.metadata.record.index.max.filegroup.size
hoodie.metadata.record.index.growth.factor
In future development iterations, RLI should be able to overcome this limitation by dynamically rebalancing file groups to accommodate the ever-increasing number of records.
Updating RLI upon data table writes
During regular writes, the RLI partition will be updated as part of the transactions. Metadata records will be generated using the incoming record keys with their corresponding location info. Given that the RLI partition contains the exact mappings of record keys and locations, upserts to the data table will result in upsertion of the corresponding keys to the RLI partition, The hash function employed will guarantee that identical keys are routed to the same file group.
Writer Indexing
Being part of the write flow, RLI follows the high-level indexing flow, similar to any other global index: for a given set of records, it tags each record with location information if the index finds them present in any existing file group. The key distinction lies in the source of truth for the existence test—the RLI partition. The diagram below illustrates the tagging flow with detailed steps.
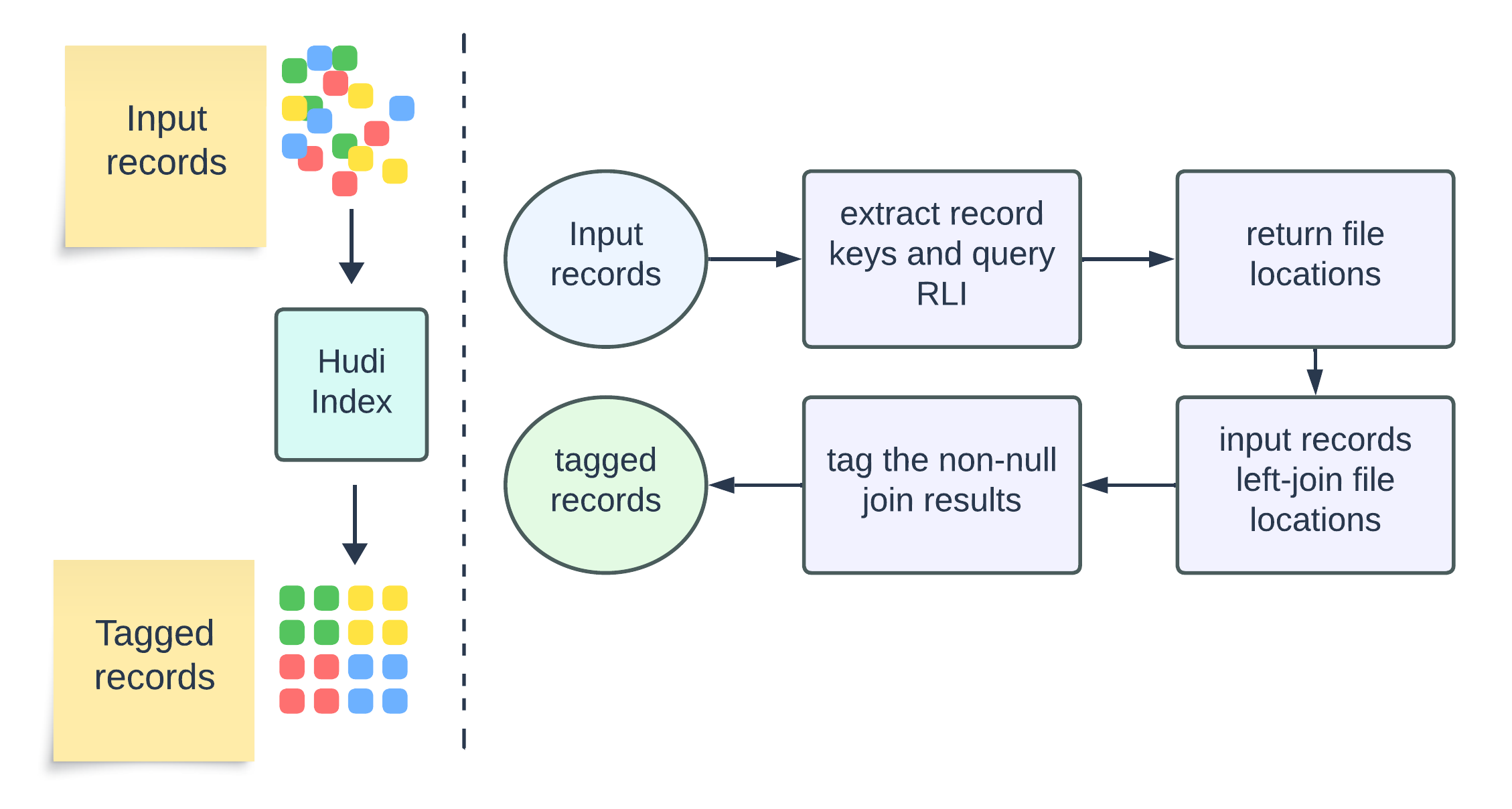
The tagged records will be passed to Hudi write handles and will undergo write operations to their respective file groups. The indexing process is a critical step in applying updates to the table, as its efficiency directly influences the write latency. In a later section, we will demonstrate the Record Level Index performance using benchmarking results.
Read Flow
The Record Level Index is also integrated on the query side[^3]. In queries that involve equality check (e.g., EqualTo or IN) against the record key column, Hudi’s file index implementation optimizes the file pruning process. This optimization is achieved by leveraging RLI to precisely locate the file groups that need to be read for completing the queries.
Storage
Storage efficiency is another vital aspect of the design. Each RLI mapping entry must include some necessary information to precisely locate files, such as record key, partition path, file group id, etc. To optimize the storage, RLI adopts some compression techniques such as encoding file group id (in the form of UUID) into 2 Longs to represent the high and low bits. Using Gzip compression and a 4MB block size, an individual RLI record averages only 48 bytes in size. To illustrate this more practically, let’s assume we have a table of 100TB data with about 1 billion records (average record size = 100Kb). The storage space required by the RLI partition will be approximately 48 Gb, which is less than 0.05% of the total data size. Since RLI contains the same number of entries as the data table, storage optimization is crucial to make RLI practical, especially for tables of petabyte size and beyond.
RLI exploits the low cost of storage to enable the rapid look-up process similar to the HBase index, while avoiding the operational overhead of running an extra server. In the next section, we will review some benchmarking results to demonstrate its performance advantages.
Performance
We conducted a comprehensive benchmarking analysis of the Record Level Index evaluating aspects such write latency, index look-up latency, and data shuffling in comparison to existing indexing mechanisms in Hudi. In addition to the benchmarks for write operations, we will also showcase the reduction in query latencies for point look-ups. Hudi 0.14.0 and Spark 3.2.1 were used throughout the experiments.
In comparison to the Global Simple Index (GSI) in Hudi, Record Level Index (RLI) is crafted for significant performance advantages stemming from a greatly reduced scan space and minimized data shuffling. GSI conducts join operations between incoming records and existing data across all partitions of the data table, resulting in substantial data shuffling and computational overhead to pinpoint the records. On the other hand, RLI efficiently extracts location info through a hash function, leading to a considerably smaller amount of data shuffling by only loading the file groups of interest from the metadata table.
Write latency
In the first set of experiments, we established two pipelines: one configured using GSI, and the other configured with RLI. Each pipeline was executed on an EMR cluster of 10 m5.4xlarge core instances, and was set to ingest batches of 200Mb data into a 1TB dataset of 2 billion records. The RLI partition was configured with 1000 file groups. For N batches of ingestion, the average write latency using RLI showed a remarkable 72% improvement over GSI.
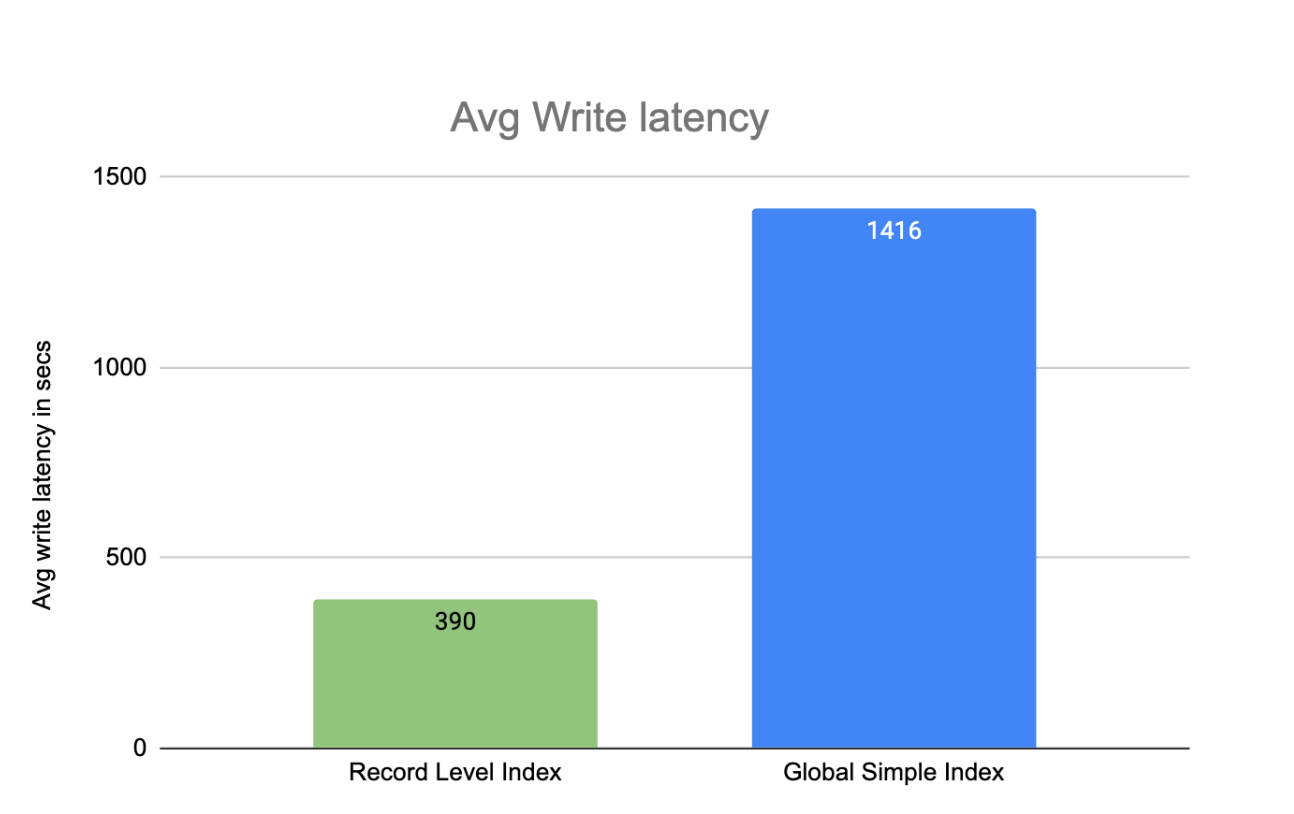
Note: Between Global Simple Index and Global Bloom Index in Hudi, the former yielded better results due to the randomness of record keys. Therefore, we omitted the presentation of the Global Bloom Index in the chart.
Index look-up latency
We also isolated the index look-up step using HoodieReadClient to accurately gauge indexing efficiency. Through experiments involving the look-up of 400,000 records (0.02%) in a 1TB dataset of 2 billion records, RLI showcased a 72% improvement over GSI, consistent with the end-to-end write latency results.
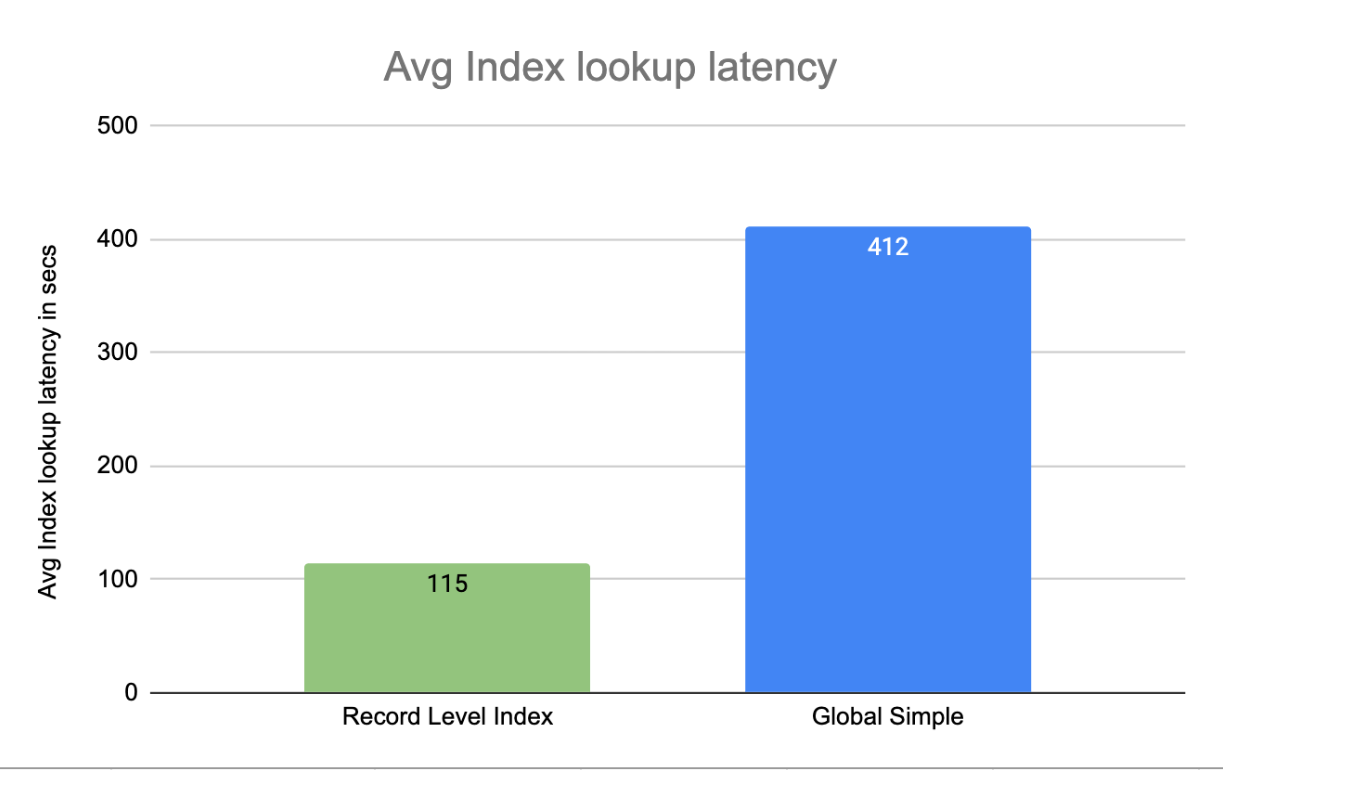
Data shuffling
In the index look-up experiments, we observed that around 85Gb of data was shuffled for GSI, whereas only 700Mb was shuffled for RLI. This reflects an impressive 92% reduction in data shuffling when using RLI compared to GSI.
Query latency
The Record Level Index will greatly boost Spark queries with “EqualTo” and “IN” predicates on record key columns. We created a 400GB Hudi table comprising 20,000 file groups. When we executed a query predicated on a single record key, we observed a significant improvement in query time. With RLI enabled, the query time decreased from 977 seconds to just 12 seconds, representing an impressive 98% reduction in latency[^4].
When to Use
RLI demonstrates outstanding performance in general, elevating update and delete efficiency to a new level and fast-tracking reads when executing key-matching queries. Enabling RLI is also as simple as setting some configuration flags. Below, we have summarized a comparison table highlighting these important characteristics of RLI in contrast to other common Hudi index types.
| Record Level Index | Global Simple Index | Global Bloom Index | HBase Index | Bucket Index | |
|---|---|---|---|---|---|
| Performant look-up in general | Yes | No | No | Yes, with possible throttling issues | Yes |
| Boost both writes and reads | Yes | No, write-only | No, write-only | No, write-only | No, write-only |
| Easy to enable | Yes | Yes | Yes | No, require HBase server | Yes |
Many real-world applications will significantly benefit from using RLI. A common example is fulfilling the GDPR requirements. Typically, when users make requests, a set of IDs will be provided to identify the to-be-deleted records, which will either be updated (columns being nullified) or permanently removed. By enabling RLI, offline jobs performing such changes will become notably more efficient, resulting in cost savings. On the read side, analysts or engineers collecting historical events through certain tracing IDs will also experience blazing fast responses from the key-matching queries.
While RLI holds the above-mentioned advantages over all other index types, it is important to consider certain aspects when using it. Similar to any other global index, RLI requires record-key uniqueness across all partitions in a table. As RLI keeps track of all record keys and locations, the initialization process may take time for large tables. In scenarios with extremely skewed large workloads, RLI might not achieve the desired performance due to limitations in the current design.
Future Work
In this initial version of the Record Level Index, certain limitations are acknowledged. As mentioned in the "Initialization" section, the number of file groups must be predetermined during the creation of the RLI partition. Hudi does use some heuristics and a growth factor for an existing table, but for a new table, it is recommended to set appropriate file group configs for RLI. As the data volume increases, the RLI partition requires re-bootstrapping when additional file groups are needed for scaling out. To address the need for rebalancing, a consistent hashing technique could be employed.
Another valuable enhancement would involve supporting the indexing of secondary columns alongside the record key fields, thus catering to a broader range of queries. On the reader side, there is a plan to integrate more query engines, such as Presto and Trino, with the Record Level Index to fully leverage the performance benefits offered by Hudi metadata tables.
[^1] This blog well-explained some best practices regarding index selection and configuration.
[^2] Other formats like Parquet can also be supported in the future.
[^3] As of now, query engine integration is only available for Spark, with plans to support additional engines in the future.
[^4] The query improvement is specific to record-key-matching queries and does not reflect a general reduction in latency by enabling RLI. In the case of the single record-key query, 99.995% of file groups (19999 out of 20000) were pruned during query execution.