Employing correct configurations for Hudi's cleaner table service
Apache Hudi provides snapshot isolation between writers and readers. This is made possible by Hudi’s MVCC concurrency model. In this blog, we will explain how to employ the right configurations to manage multiple file versions. Furthermore, we will discuss mechanisms available to users on how to maintain just the required number of old file versions so that long running readers do not fail.
Reclaiming space and keeping your data lake storage costs in check
Hudi provides different table management services to be able to manage your tables on the data lake. One of these services is called the Cleaner. As you write more data to your table, for every batch of updates received, Hudi can either generate a new version of the data file with updates applied to records (COPY_ON_WRITE) or write these delta updates to a log file, avoiding rewriting newer version of an existing file (MERGE_ON_READ). In such situations, depending on the frequency of your updates, the number of file versions of log files can grow indefinitely. If your use-cases do not require keeping an infinite history of these versions, it is imperative to have a process that reclaims older versions of the data. This is Hudi’s cleaner service.
Problem Statement
In a data lake architecture, it is a very common scenario to have readers and writers concurrently accessing the same table. As the Hudi cleaner service periodically reclaims older file versions, scenarios arise where a long running query might be accessing a file version that is deemed to be reclaimed by the cleaner. Here, we need to employ the correct configs to ensure readers (aka queries) don’t fail.
Deeper dive into Hudi Cleaner
To deal with the mentioned scenario, lets understand the different cleaning policies that Hudi offers and the corresponding properties that need to be configured. Options are available to schedule cleaning asynchronously or synchronously. Before going into more details, we would like to explain a few underlying concepts:
- Hudi base file: Columnar file which consists of final data after compaction. A base file’s name follows the following naming convention:
<fileId>_<writeToken>_<instantTime>.parquet. In subsequent writes of this file, file id remains the same and commit time gets updated to show the latest version. This also implies any particular version of a record, given its partition path, can be uniquely located using the file id and instant time. - File slice: A file slice consists of the base file and any log files consisting of the delta, in case of MERGE_ON_READ table type.
- Hudi File Group: Any file group in Hudi is uniquely identified by the partition path and the file id that the files in this group have as part of their name. A file group consists of all the file slices in a particular partition path. Also any partition path can have multiple file groups.
Cleaning Policies
Hudi cleaner currently supports below cleaning policies:
- KEEP_LATEST_COMMITS: This is the default policy. This is a temporal cleaning policy that ensures the effect of having lookback into all the changes that happened in the last X commits. Suppose a writer is ingesting data into a Hudi dataset every 30 minutes and the longest running query can take 5 hours to finish, then the user should retain atleast the last 10 commits. With such a configuration, we ensure that the oldest version of a file is kept on disk for at least 5 hours, thereby preventing the longest running query from failing at any point in time. Incremental cleaning is also possible using this policy.
- KEEP_LATEST_FILE_VERSIONS: This policy has the effect of keeping N number of file versions irrespective of time. This policy is useful when it is known how many MAX versions of the file does one want to keep at any given time. To achieve the same behaviour as before of preventing long running queries from failing, one should do their calculations based on data patterns. Alternatively, this policy is also useful if a user just wants to maintain 1 latest version of the file.
Examples
Suppose a user is ingesting data into a hudi dataset of type COPY_ON_WRITE every 30 minutes as shown below:
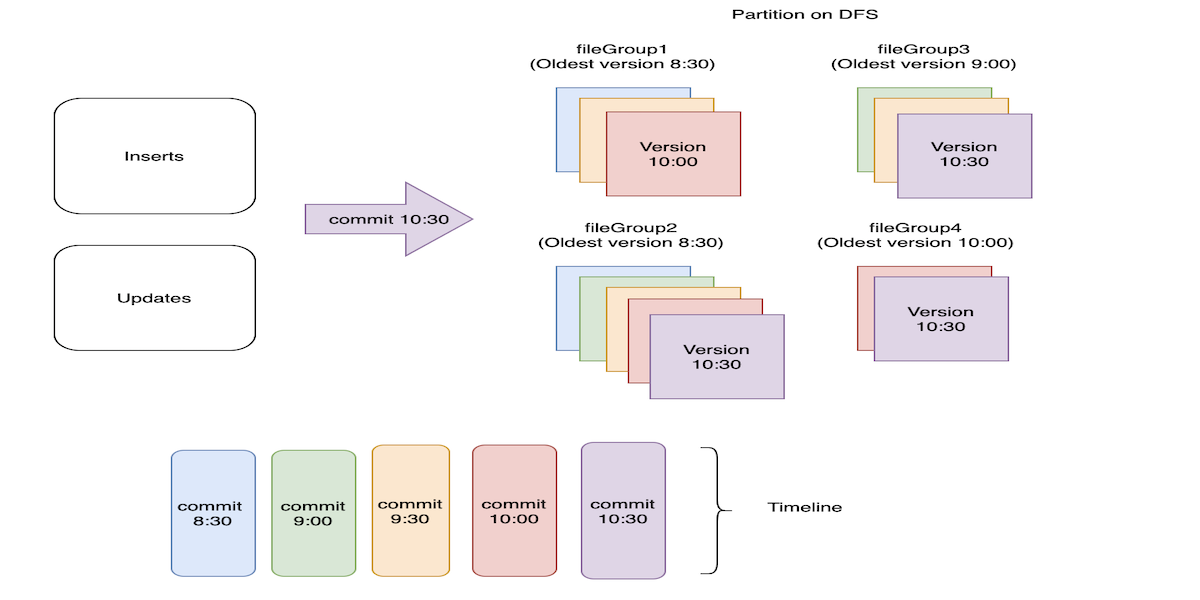 Figure1: Incoming records getting ingested into a hudi dataset every 30 minutes
Figure1: Incoming records getting ingested into a hudi dataset every 30 minutes
The figure shows a particular partition on DFS where commits and corresponding file versions are color coded. 4 different file groups are created in this partition as depicted by fileGroup1, fileGroup2, fileGroup3 and fileGroup4. File group corresponding to fileGroup2 has records ingested from all the 5 commits, while the group corresponding to fileGroup4 has records from the latest 2 commits only.
Suppose the user uses the below configs for cleaning:
hoodie.cleaner.policy=KEEP_LATEST_COMMITS
hoodie.cleaner.commits.retained=2
Cleaner selects the versions of files to be cleaned by taking care of the following:
- Latest version of a file should not be cleaned.
- The commit times of the last 2 (configured) + 1 commits are determined. In Figure1,
commit 10:30andcommit 10:00correspond to the latest 2 commits in the timeline. One extra commit is included because the time window for retaining commits is essentially equal to the longest query run time. So if the longest query takes 1 hour to finish, and ingestion happens every 30 minutes, you need to retain last 2 commits since 2*30 = 60 (1 hour). At this point of time, the longest query can still be using files written in 3rd commit in reverse order. Essentially this means if a query started executing aftercommit 9:30, it will still be running when clean action is triggered right aftercommit 10:30as in Figure2. - Now for any file group, only those file slices are scheduled for cleaning which are not savepointed (another Hudi table service) and whose commit time is less than the 3rd commit (
commit 9:30in figure below) in reverse order.
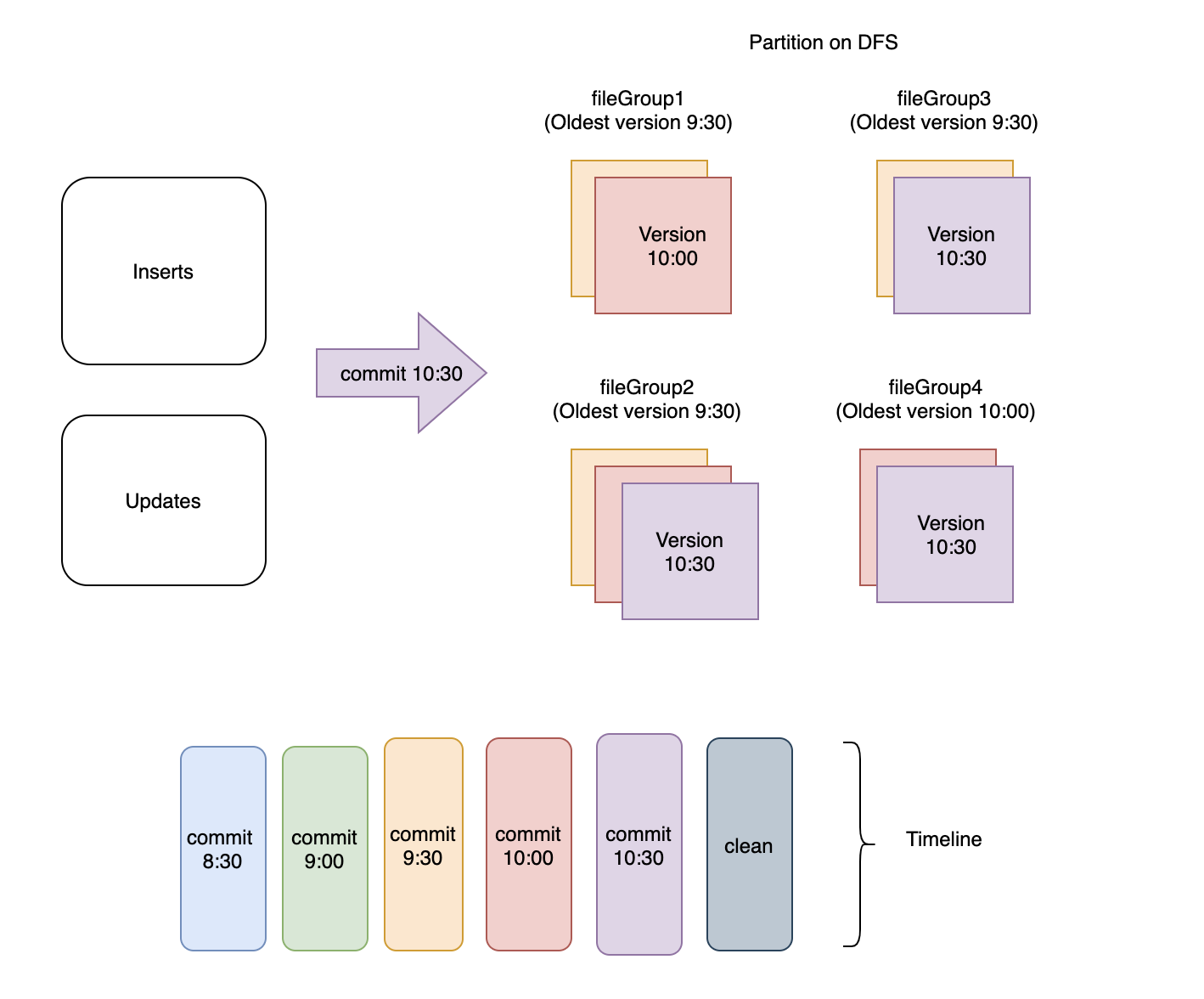 Figure2: Files corresponding to latest 3 commits are retained
Figure2: Files corresponding to latest 3 commits are retained
Now, suppose the user uses the below configs for cleaning:
hoodie.cleaner.policy=KEEP_LATEST_FILE_VERSIONS
hoodie.cleaner.fileversions.retained=1
Cleaner does the following:
- For any file group, latest version (including any for pending compaction) of file slices are kept and the rest are scheduled for cleaning. Clearly as shown in Figure3, if clean action is triggered right after
commit 10:30, the cleaner will simply leave the latest version in every file group and delete the rest.
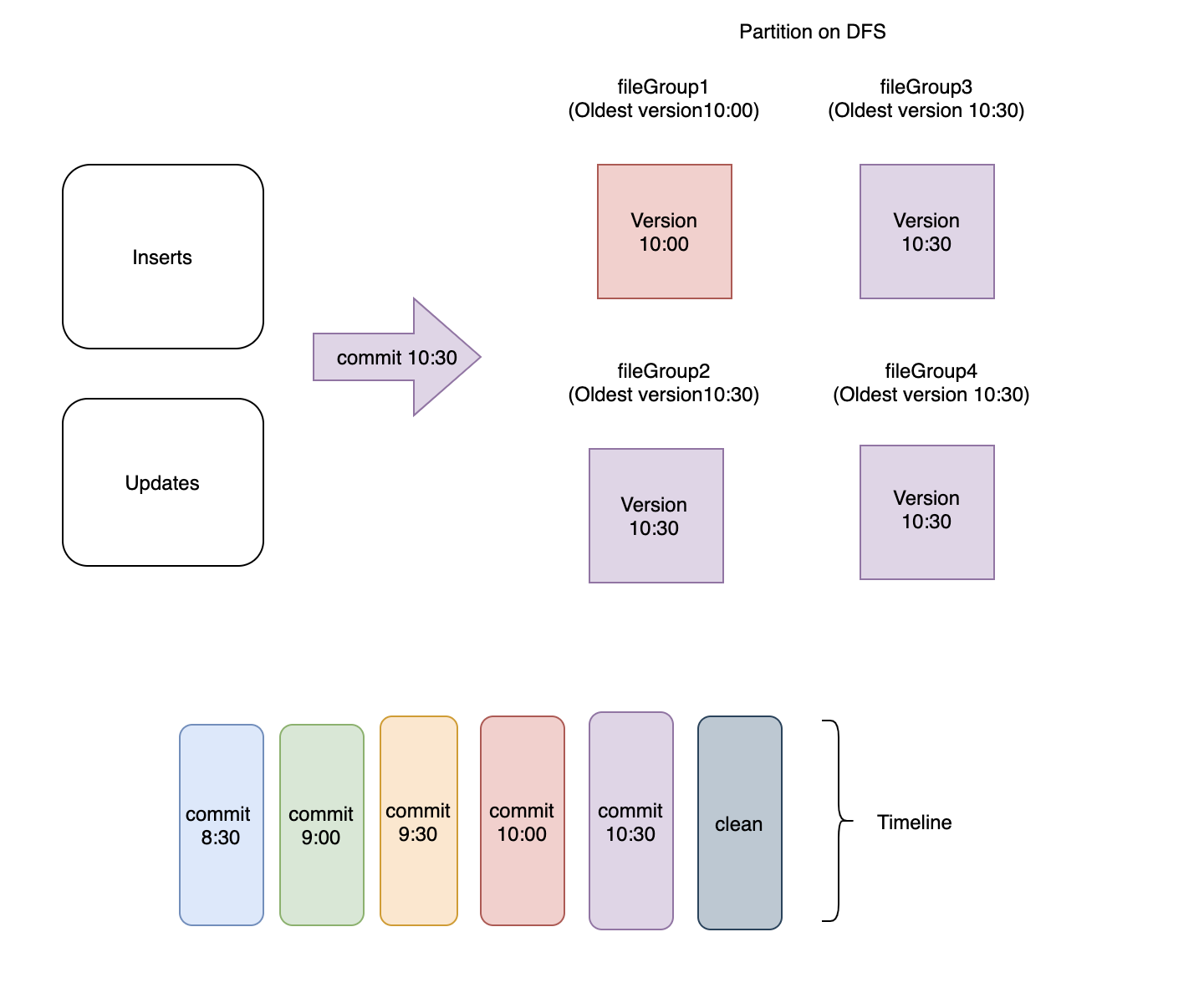 Figure3: Latest file version in every file group is retained
Figure3: Latest file version in every file group is retained
Configurations
You can find the details about all the possible configurations along with the default values here.
Run command
Hudi's cleaner table service can be run as a separate process or along with your data ingestion. As mentioned earlier, it basically cleans up any stale/old files lying around. In case you want to run it along with ingesting data, configs are available which enable you to run it synchronously or asynchronously. You can use the below command for running the cleaner independently:
[hoodie]$ spark-submit --class org.apache.hudi.utilities.HoodieCleaner \
--props s3:///temp/hudi-ingestion-config/kafka-source.properties \
--target-base-path s3:///temp/hudi \
--spark-master yarn-cluster
In case you wish to run the cleaner service asynchronously with writing, please configure the below:
hoodie.clean.automatic=true
hoodie.clean.async=true
Further you can use Hudi CLI for managing your Hudi dataset. CLI provides the below commands for cleaner service:
cleans showclean showpartitionscleans run
You can find more details and the relevant code for these commands in org.apache.hudi.cli.commands.CleansCommand class.
Future Scope
Work is currently going on for introducing a new cleaning policy based on time elapsed. This will help in achieving a consistent retention throughout regardless of how frequently ingestion happens. You may track the progress here.
We hope this blog gives you an idea about how to configure the Hudi cleaner and the supported cleaning policies. Please visit the blog section for a deeper understanding of various Hudi concepts. Cheers!