Apache Hudi meets Apache Flink
Apache Hudi (Hudi for short) is a data lake framework created at Uber. Hudi joined the Apache incubator for incubation in January 2019, and was promoted to the top Apache project in May 2020. It is one of the most popular data lake frameworks.
1. Why decouple
Hudi has been using Spark as its data processing engine since its birth. If users want to use Hudi as their data lake framework, they must introduce Spark into their platform technology stack. A few years ago, using Spark as a big data processing engine can be said to be very common or even natural. Since Spark can either perform batch processing or use micro-batch to simulate streaming, one engine solves both streaming and batch problems. However, in recent years, with the development of big data technology, Flink, which is also a big data processing engine, has gradually entered people's vision and has occupied a certain market in the field of computing engines. In the big data technology community, forums and other territories, the voice of whether Hudi supports Flink has gradually appeared and has become more frequent. Therefore, it is a valuable thing to make Hudi support the Flink engine, and the first step of integrating the Flink engine is that Hudi and Spark are decoupled.
In addition, looking at the mature, active, and viable frameworks in the big data, all frameworks are elegant in design and can be integrated with other frameworks and leverage each other's expertise. Therefore, decoupling Hudi from Spark and turning it into an engine-independent data lake framework will undoubtedly create more possibilities for the integration of Hudi and other components, allowing Hudi to better integrate into the big data ecosystem.
2. Challenges
Hudi's internal use of Spark API is as common as our usual development and use of List. Since the data source reads the data, and finally writes the data to the table, Spark RDD is used as the main data structure everywhere, and even ordinary tools are implemented using the Spark API. It can be said that Hudi is a universal data lake framework implemented by Spark. Hudi also leverages deep Spark functionality like custom partitioning, in-memory caching to implement indexing and file sizing using workload heuristics. For some of these, Flink offers better out-of-box support (e.g using Flink’s state store for indexing) and can in fact, make Hudi approach real-time latencies more and more.
In addition, the primary engine integrated after this decoupling is Flink. Flink and Spark differ greatly in core abstraction. Spark believes that data is bounded, and its core abstraction is a limited set of data. Flink believes that the essence of data is a stream, and its core abstract DataStream contains various operations on data. Hudi has a streaming first design (record level updates, record level streams), that arguably fit the Flink model more naturally. At the same time, there are multiple RDDs operating at the same time in Hudi, and the processing result of one RDD is combined with another RDD. This difference in abstraction and the reuse of intermediate results during implementation make it difficult for Hudi to use a unified API to operate both RDD and DataStream in terms of decoupling abstraction.
3. Decoupling Spark
In theory, Hudi uses Spark as its computing engine to use Spark's distributed computing power and RDD's rich operator capabilities. Apart from distributed computing power, Hudi uses RDD more as a data structure, and RDD is essentially a bounded data set. Therefore, it is theoretically feasible to replace RDD with List (of course, it may sacrifice performance/scale). In order to ensure the performance and stability of the Hudi Spark version as much as possible. We can keep setting the bounded data set as the basic operation unit. Hudi's main operation API remains unchanged, and RDD is extracted as a generic type. The Spark engine implementation still uses RDD, and other engines use List or other bounded data set according to the actual situation.
Decoupling principle
-
Unified generics. The input records
JavaRDD<HoodieRecord>, key of input recordsJavaRDD<HoodieKey>, and result of write operationsJavaRDD<WriteStatus>used by the Spark API use genericI,K,Oinstead; -
De-sparkization. All APIs of the abstraction layer must have nothing to do with Spark. Involving specific operations that are difficult to implement in the abstract layer, rewrite them as abstract methods and introduce Spark subclasses.
For example: Hudi uses the JavaSparkContext#map() method in many places. To de-spark, you need to hide the JavaSparkContext. For this problem, we introduced the HoodieEngineContext#map() method, which will block the specific implementation details of map, so as to achieve de-sparkization in abstraction.
-
Minimize changes to the abstraction layer to ensure the original function and performance of Hudi;
-
Replace the
JavaSparkContextwith theHoodieEngineContextabstract class to provide the running environment context.
In addition, some of the core algorithms in Hudi, like rollback, has been redone without the need for computing a workload profile ahead of time, which used to rely on Spark caching.
4. Flink integration design
Hudi's write operation is batch processing in nature, and the continuous mode of DeltaStreamer is realized by looping batch processing. In order to use a unified API, when Hudi integrates Flink, we choose to collect a batch of data before processing, and finally submit it in a unified manner (here we use List to collect data in Flink).
In Hudi terminology, we will stream data for a given commit, but only publish the commits every so often, making it practical to scale storage on cloud storage and also tunable.
The easiest way to think of batch operation is to use a time window. However, when using a window, when there is no data flowing in a window, there will be no output data, and it is difficult for the Flink sink to judge whether all the data from a given batch has been processed. Therefore, we use Flink's checkpoint mechanism to collect batches. The data between every two barriers is a batch. When there is no data in a subtask, the mock result data is made up. In this way, on the sink side, when each subtask has result data issued, it can be considered that a batch of data has been processed and the commit can be executed.
The DAG is as follows:
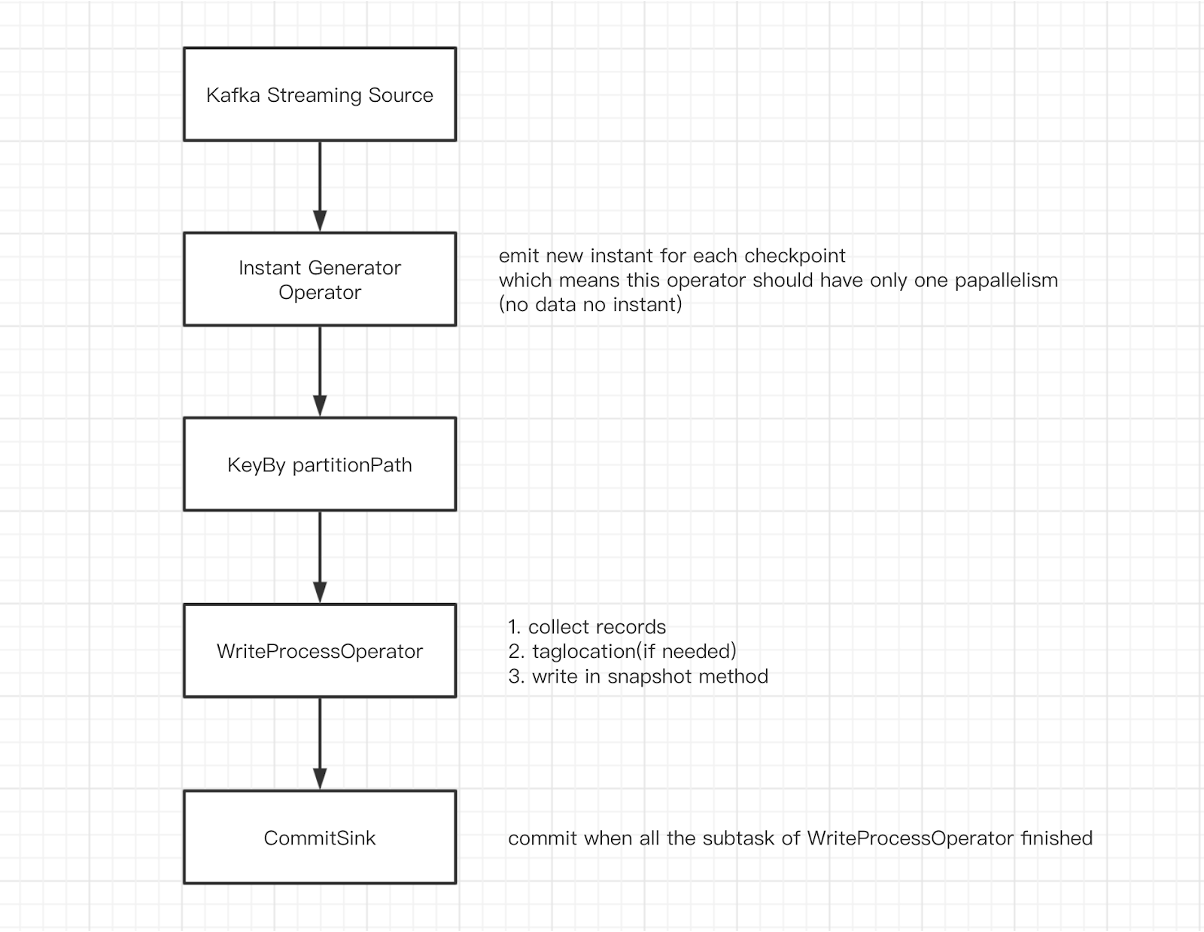
- Source: receives Kafka data and converts it into
List<HoodieRecord>; - InstantGeneratorOperator: generates a globally unique instant. When the previous instant is not completed or the current batch has no data, no new instant is created;
- KeyBy partitionPath: partitions according to
partitionPathto avoid multiple subtasks from writing the same partition; - WriteProcessOperator: performs a write operation. When there is no data in the current partition, it sends empty result data to the downstream to make up the number;
- CommitSink: receives the calculation results of the upstream task. When receiving the parallelism results, it is considered that all the upstream subtasks are completed and the commit is executed.
Note:
InstantGeneratorOperator and WriteProcessOperator are both custom Flink operators. InstantGeneratorOperator will block checking the state of the previous instant to ensure that there is only one instant in the global (or requested) state.
WriteProcessOperator is the actual execution Where a write operation is performed, the write operation is triggered at checkpoint.
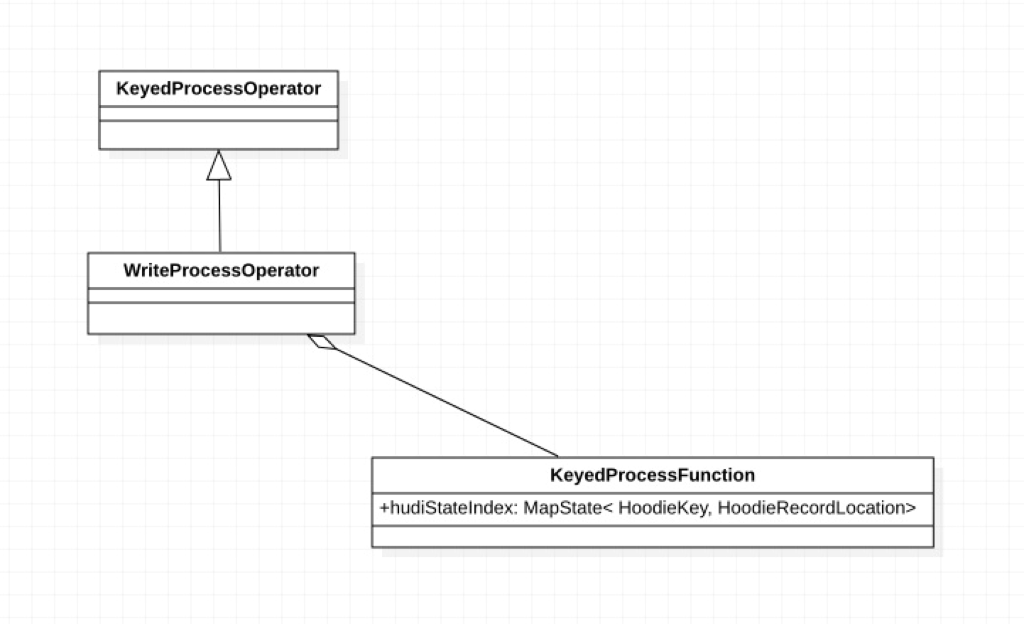
4.1 Index design based on Flink State
Stateful computing is one of the highlights of the Flink engine. Compared with using external storage, using Flink's built-in State can significantly improve the performance of Flink applications.
Therefore, it would be a good choice to implement a Hudi index based on Flink's State.
The core of the Hudi index is to maintain the mapping of the Hudi key HoodieKey and the location of the Hudi data HoodieRecordLocation.
Therefore, based on the current design, we can simply maintain a MapState<HoodieKey, HoodieRecordLocation> in Flink UDF to map the HoodieKey and HoodieRecordLocation, and leave the fault tolerance and persistence of State to the Flink framework.
5. Implementation examples
1) HoodieTable
/**
* Abstract implementation of a HoodieTable.
*
* @param <T> Sub type of HoodieRecordPayload
* @param <I> Type of inputs
* @param <K> Type of keys
* @param <O> Type of outputs
*/
public abstract class HoodieTable<T extends HoodieRecordPayload, I, K, O> implements Serializable {
protected final HoodieWriteConfig config;
protected final HoodieTableMetaClient metaClient;
protected final HoodieIndex<T, I, K, O> index;
public abstract HoodieWriteMetadata<O> upsert(HoodieEngineContext context, String instantTime,
I records);
public abstract HoodieWriteMetadata<O> insert(HoodieEngineContext context, String instantTime,
I records);
public abstract HoodieWriteMetadata<O> bulkInsert(HoodieEngineContext context, String instantTime,
I records, Option<BulkInsertPartitioner<I>> bulkInsertPartitioner);
...
}
HoodieTable is one of the core abstractions of Hudi, which defines operations such as insert, upsert, and bulkInsert supported by the table.
Take upsert as an example, the input data is changed from the original JavaRDD<HoodieRecord> inputRdds to I records, and the runtime JavaSparkContext jsc is changed to HoodieEngineContext context.
From the class annotations, we can see that T, I, K, O represents the load data type, input data type, primary key type and output data type of Hudi operation respectively.
These generics will run through the entire abstraction layer.
2) HoodieEngineContext
/**
* Base class contains the context information needed by the engine at runtime. It will be extended by different
* engine implementation if needed.
*/
public abstract class HoodieEngineContext {
public abstract <I, O> List<O> map(List<I> data, SerializableFunction<I, O> func, int parallelism);
public abstract <I, O> List<O> flatMap(List<I> data, SerializableFunction<I, Stream<O>> func, int parallelism);
public abstract <I> void foreach(List<I> data, SerializableConsumer<I> consumer, int parallelism);
......
}
HoodieEngineContext plays the role of JavaSparkContext, it not only provides all the information that JavaSparkContext can provide,
but also encapsulates many methods such as map, flatMap, foreach, and hides The specific implementation of JavaSparkContext#map(),JavaSparkContext#flatMap(), JavaSparkContext#foreach() and other methods.
Take the map method as an example. In the Spark implementation class HoodieSparkEngineContext, the map method is as follows:
@Override
public <I, O> List<O> map(List<I> data, SerializableFunction<I, O> func, int parallelism) {
return javaSparkContext.parallelize(data, parallelism).map(func::apply).collect();
}
In the engine that operates List, the implementation can be as follows (different methods need to pay attention to thread-safety issues, use parallel() with caution):
@Override
public <I, O> List<O> map(List<I> data, SerializableFunction<I, O> func, int parallelism) {
return data.stream().parallel().map(func::apply).collect(Collectors.toList());
}
Note:
The exception thrown in the map function can be solved by wrapping SerializableFunction<I, O> func.
Here is a brief introduction to SerializableFunction:
@FunctionalInterface
public interface SerializableFunction<I, O> extends Serializable {
O apply(I v1) throws Exception;
}
This method is actually a variant of java.util.function.Function. The difference from java.util.function.Function is that SerializableFunction can be serialized and can throw exceptions.
This function is introduced because the input parameters that the JavaSparkContext#map() function can receive must be serializable.
At the same time, there are many exceptions that need to be thrown in the logic of Hudi, and the code for try-catch in the Lambda expression will be omitted It is bloated and not very elegant.
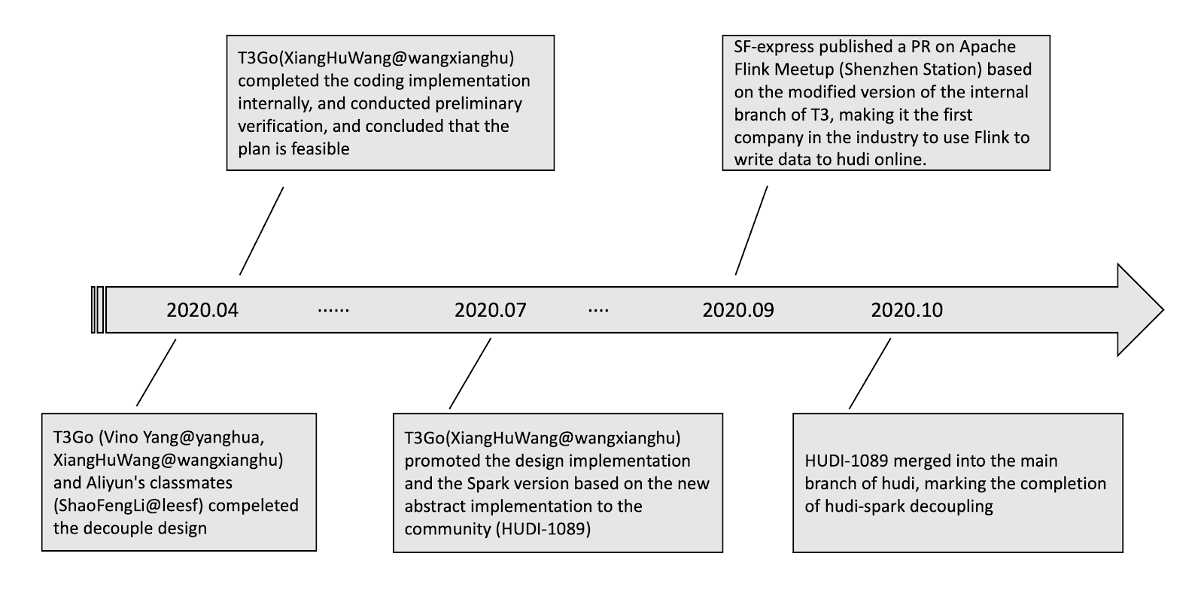
6. Current progress and follow-up plan
6.1 Working time axis
6.2 Follow-up plan
1) Promote the integration of Hudi and Flink
Push the integration of Flink and Hudi to the community as soon as possible. In the initial stage, this feature may only support Kafka data sources.
2) Performance optimization
In order to ensure the stability and performance of the Hudi-Spark version, the decoupling did not take too much into consideration the possible performance problems of the Flink version.
3) flink-connector-hudi like third-party package development
Make the binding of Hudi-Flink into a third-party package. Users can this third-party package to read/write from/to Hudi with Flink.